
None
None
-
Use Case 2: Scaling Up Multiple Instances of Llama 3 Models
XE9680 with 8xH100 - 8x Llama3 8B
Concurrency
Throughput (tokens per seconds)
TTFT (milliseconds)
Request Latency (milliseconds)
1
162.17
14.55
895.15
5
780.85
16.48
913.94
10
1,527.39
17.69
948.21
25
3,831.93
18.35
920.22
50
7,420.86
20.55
925.76
100
13,896.01
23.52
1,013.57
250
30,652.08
46.89
1,115.80
500
47,488.00
132.27
1,426.87
1000
53,084.03
399.97
2,477.98
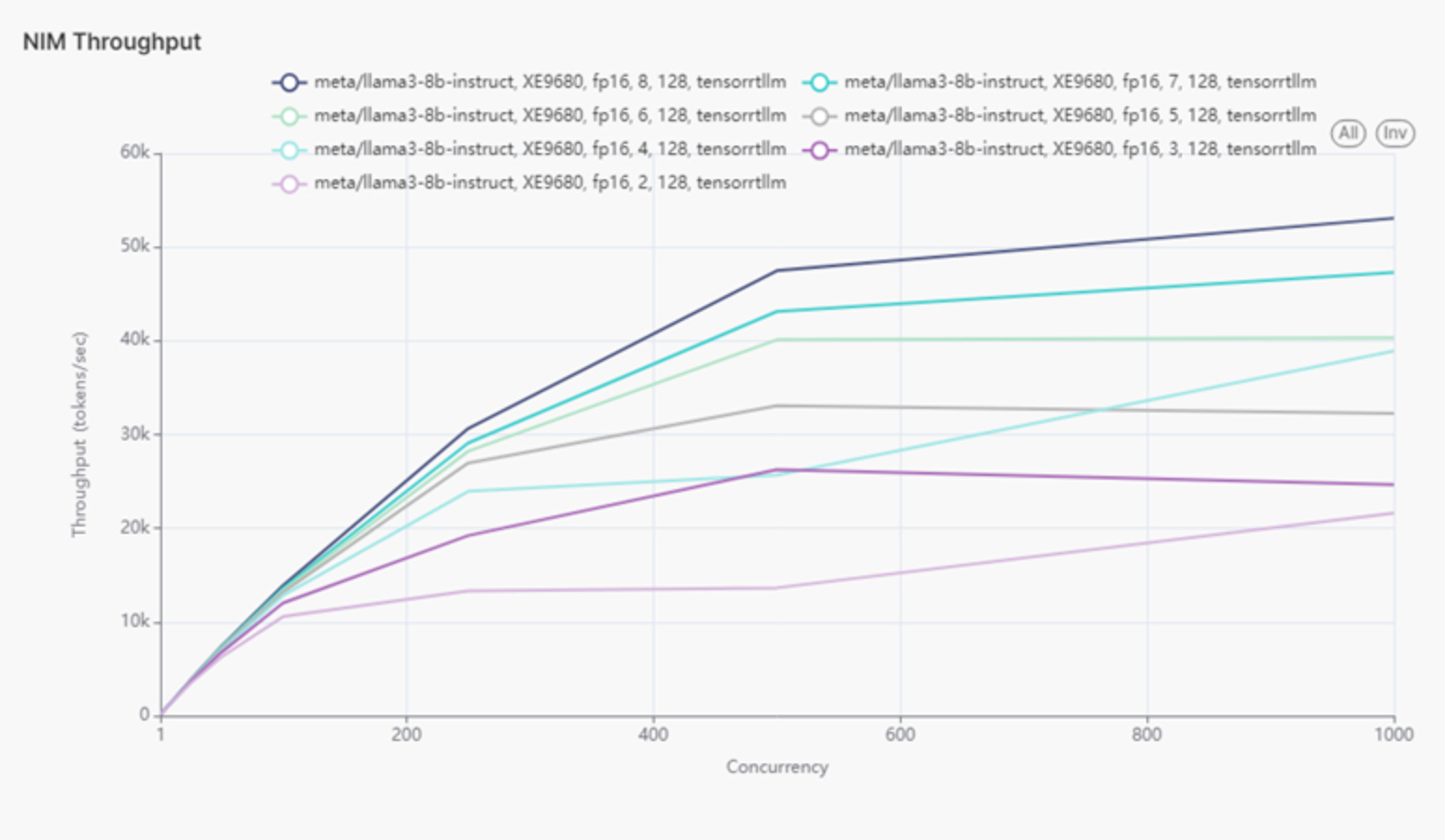
In this use case, Llama 3 8B was configured on the XE9680 server, gradually increasing the number of instances until the server was fully loaded. This setup utilized all eight H100 GPUs, resulting in eight Llama 3 models running simultaneously. Throughput and latency were measured incrementally, starting with one model and increasing to eight. CPU utilization was also recorded alongside GPU throughput and latency.
Table 7.
For the XE9680 server, increasing the number of GPUs from 1 to 8 showed a consistent increase in throughput, with the highest throughput achieved at 53,084.03 tokens per second with 8 instances. Although latency generally increased with the number of instances, it was best managed with optimized resource allocation. This scalability demonstrates the XE9680's capability to handle high workloads efficiently.
Figure 3 shows throughput of eight Llama 3 models on XE9680.
Figure 3.
The same test was conducted on an R760xa server, which has four L40S GPUs. The number of Llama 3 8B instances was increased until the server reached full capacity, with four models running in total. Throughput and latency were similarly measured incrementally, from one model up to four.
Figure 4 shows throughput of eight Llama 3 models on R760xa.
Figure 4.
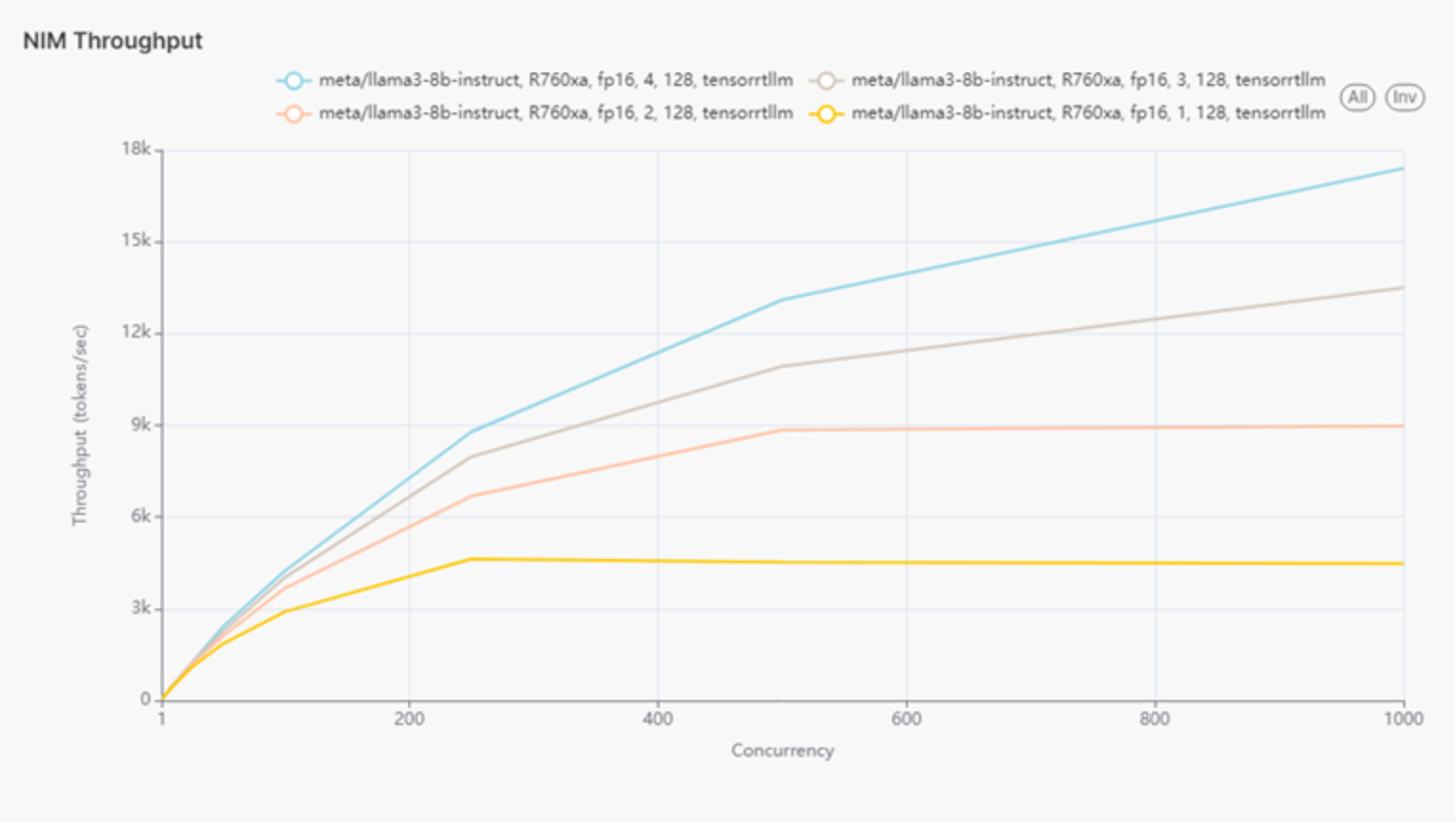
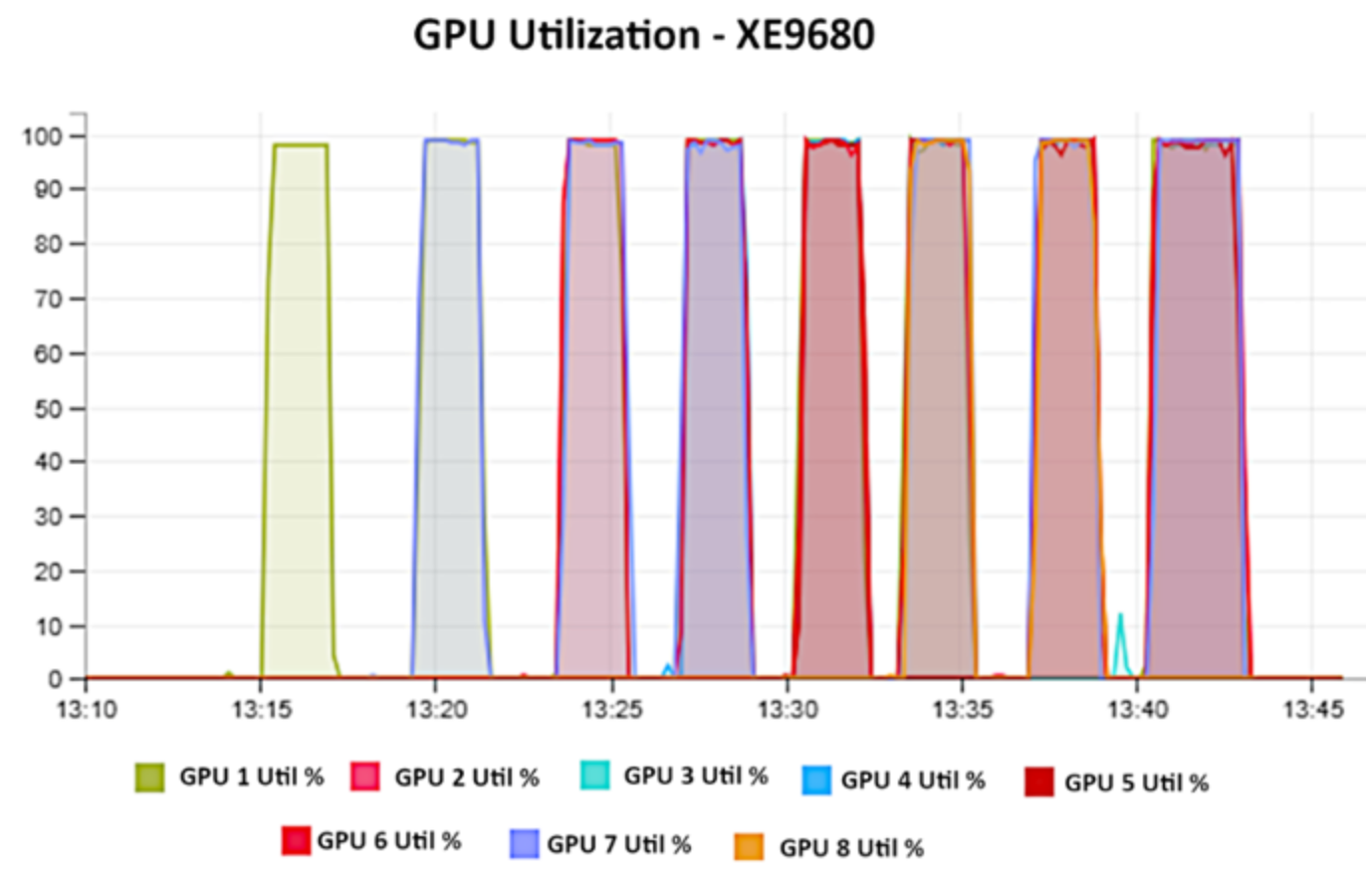
Figure 5 shows GPU utilization as we increased the number of models on the XE9680. As we add running models, the colors overlap. Each model reserves 100% of memory from the respective GPU.
Figure 5.
For the R760xa server, scaling from 1 to 4 GPUs also resulted in significant improvements in throughput, with the best performance observed at 4 GPUs, reaching 17,399.25 tokens per second. Latency remained mostly consistent, with the best result around 32 milliseconds at 4 GPUs and 500 concurrent users. This indicates that the R760xa is well-suited for moderate to high workloads, effectively balancing both latency and throughput.
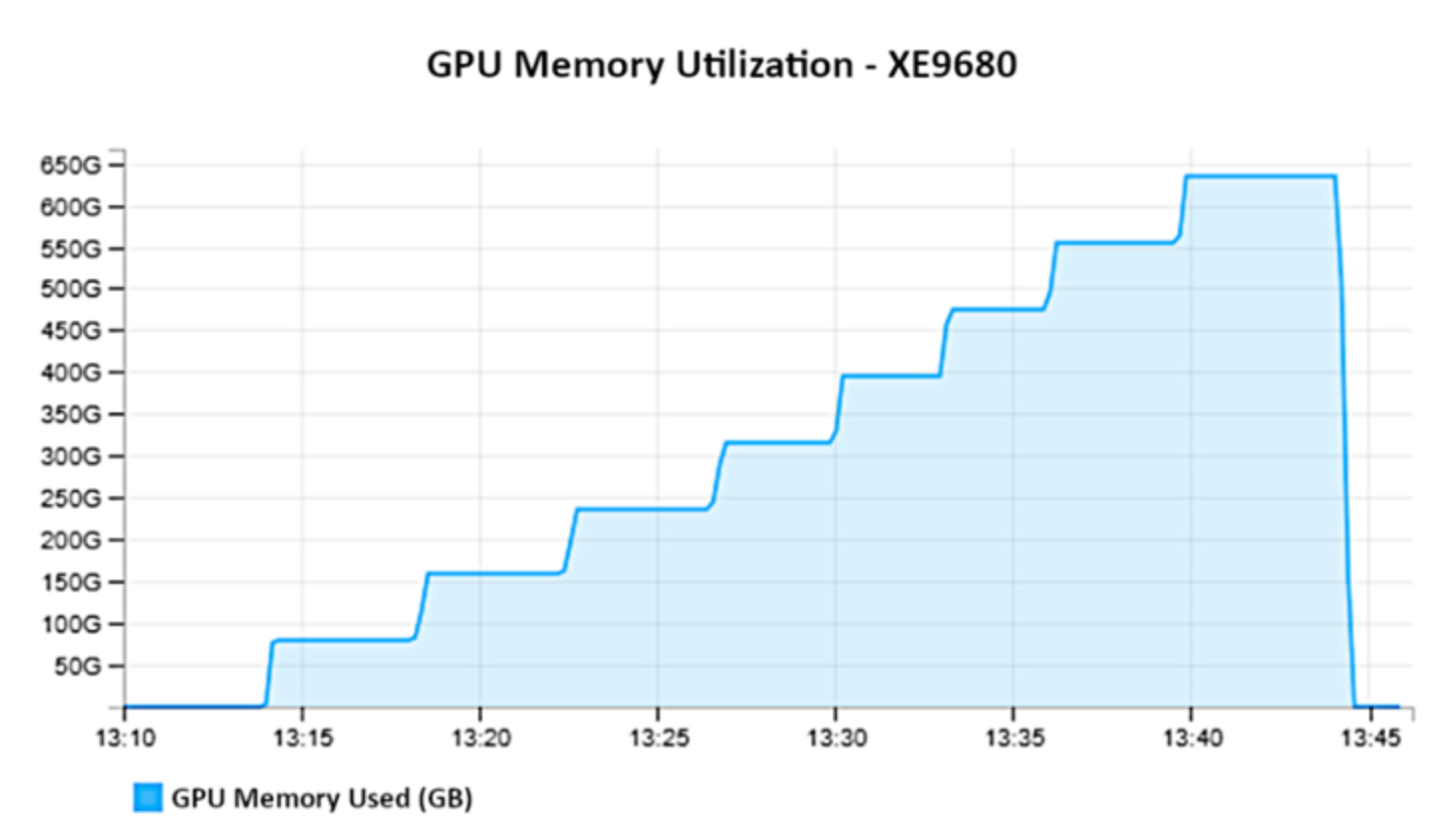
Figure 6 shows GPU memory from a different perspective. We increase the amount of load and GPU memory used.
Figure 6.
It was observed that both XE9680 and R760xa servers can efficiently scale the number of Llama 3 8B model instances, leading to increased throughput without a significant rise in latency. The XE9680 achieved peak throughput with 8 instances, making it ideal for tasks requiring high computational power and data throughput. On the other hand, the R760xa showed optimal performance with 4 instances, balancing throughput and latency, making it suitable for a wide range of enterprise applications.
The GPU utilization data reveals that each model reserves 100% of the memory from the respective GPUs, underscoring the importance of strategic resource management when scaling up instances. As more models are added, GPU memory usage increases proportionally, highlighting the need for adequate hardware resources to maintain performance.
As part of use case 2, we wish to gather more metrics on the XE9680, like power consumption, CPU utilization, memory utilization, and network utilization, to provide a comprehensive view of the system performance under different loads and help in understanding the resource demands of scaling AI workloads. Below are graphs documenting GPU utilization, CPU utilization, memory usage, power consumption, and network utilization for the XE9680.
Figure 7 shows graph of GPU Power Utilization – XE9680
Figure 7.
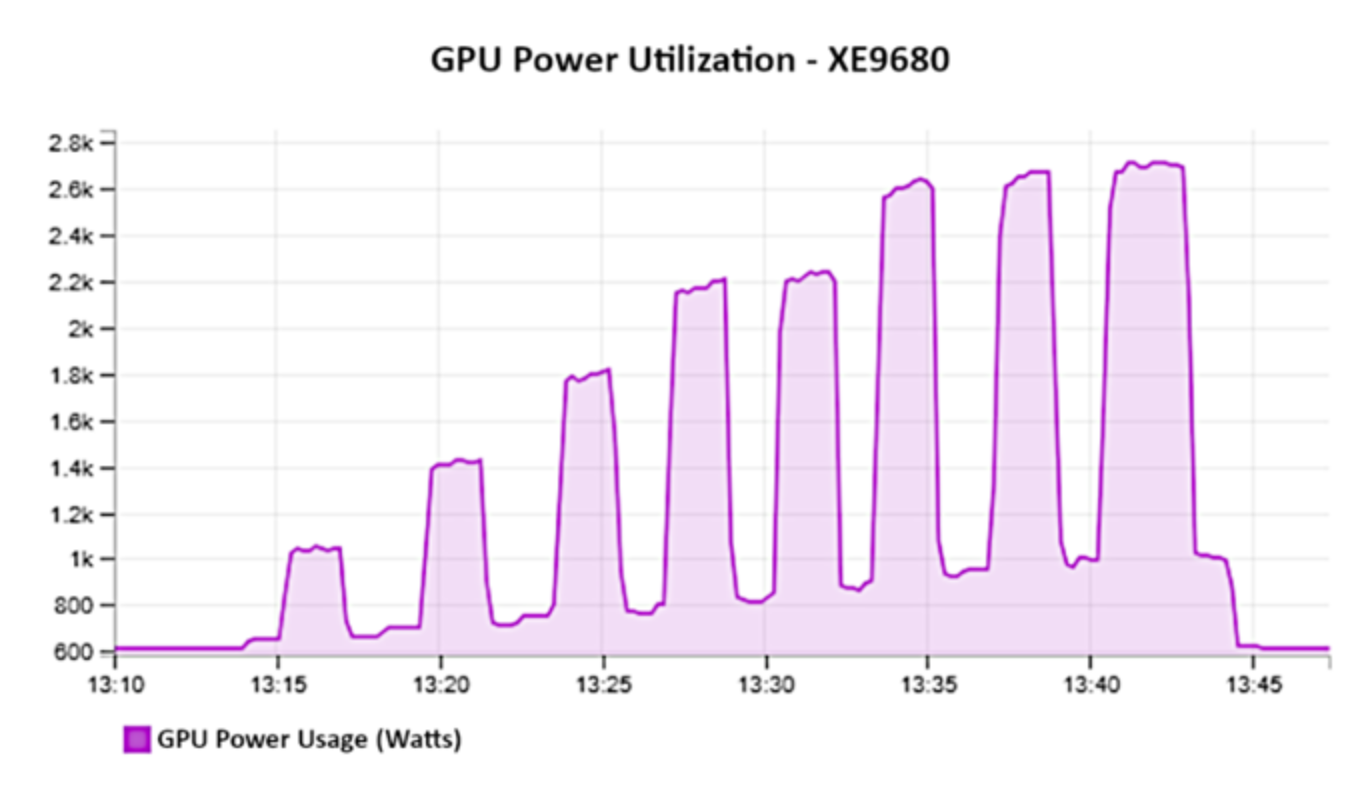
Figure 8 shows CPU Utilization
Figure 8.
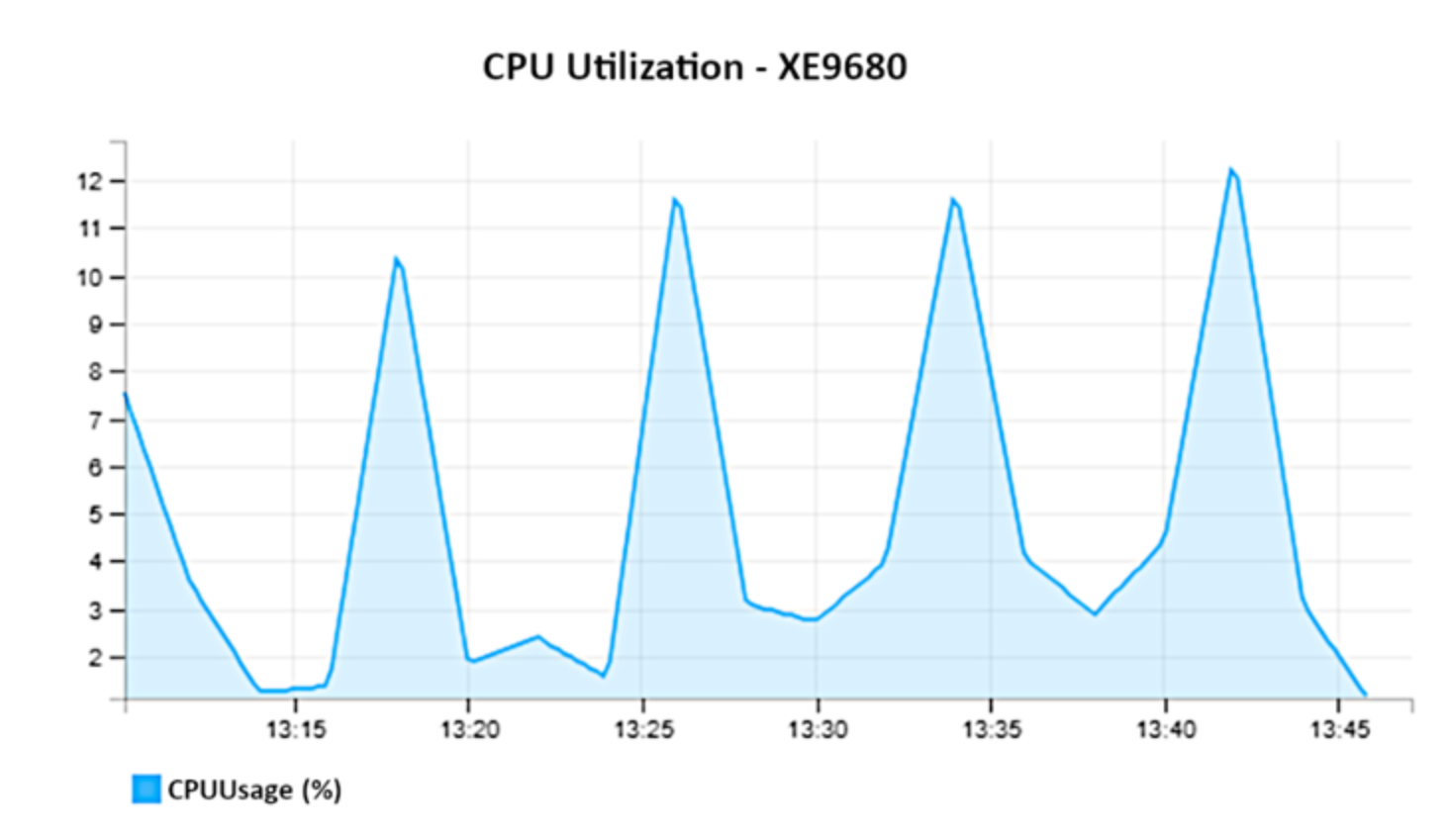
Figure 9 shows memory utilization on XE9680
Figure 9.
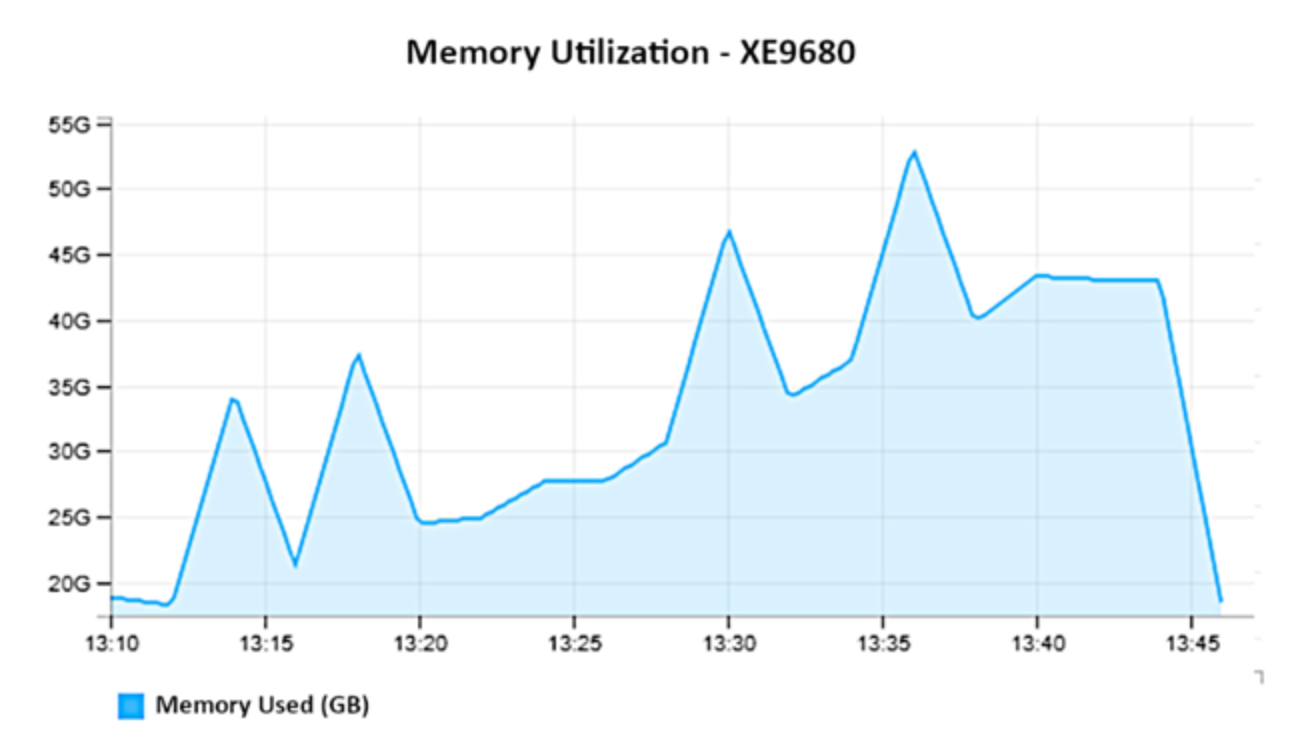
Figure 10 shows network utilization on XE9680.
Figure 10.
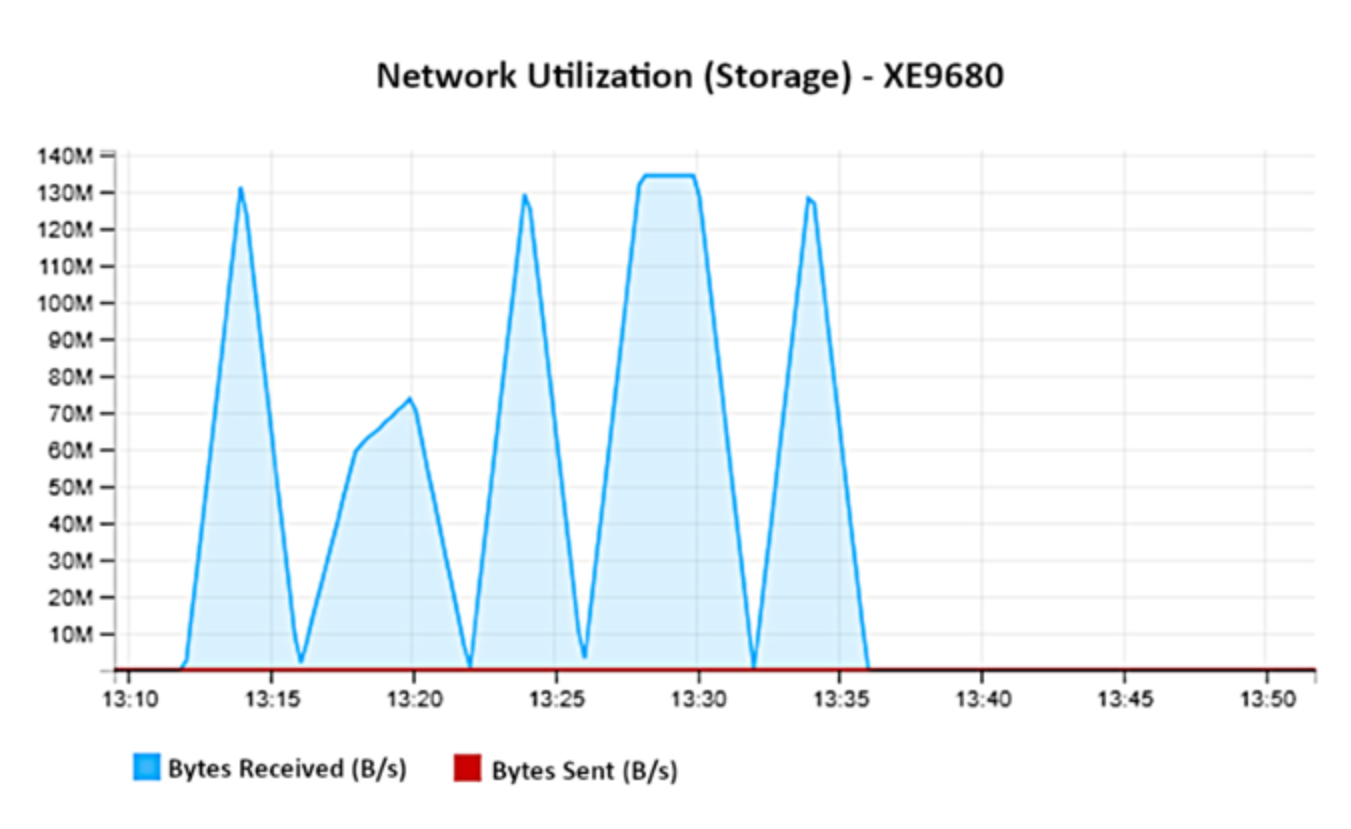
Analysis: Network traffic occurs for initial download of model.