
Tensorflow training
Tensorflow training
-
Another significant state in the ML life cycle is the training of neural network models. Because this is the most computationally intensive part of ML/DL, data scientists need results as quickly as possible to be productive.
TFJobs
Kubeflow uses a Kubernetes custom resource, TFJobs, to run TensorFlow training jobs in an automated fashion and enable data scientists to monitor job progress by viewing the results. Kubeflow provides a YAML representation for TFJobs. For more information, see TensorFlow Training (TFJob).
To run the training jobs efficiently and take advantage of the hardware optimization features that are available in the latest Intel Xeon scalable processor, Dell EMC recommends using the Intel Optimized Tensorflow ML Framework. The Optimized TensorFlow ML framework uses Intel MKL-DNN library primitives to take advantage of Intel architecture features such as AVX2 for floating-point matrix multiplication and to run Tensorflow training jobs on Intel CPUs.
TensorFlow distributed training uses the compute capability of multiple nodes to work on the same neural network training, reducing execution time. Multiple components play a role to enable distributed training. For example, the Parameter Server (PS) stores the parameters that the individual workers need, while worker nodes are responsible for the computation or model training.
Running a TFJob
To demonstrate the capabilities of the latest Intel Xeon Scalable processor in running ML/DL training jobs and the scaling efficiencies of the OpenShift Platform, we ran the commonly used TensorFlow CNN benchmark to train the ResNet50 model.
To deploy the TFJob, we used the following YAML file:
tf_intel_cnn.yaml
apiVersion: kubeflow.org/v1beta2
kind: TFJob
metadata:
labels:
experiment: experiment
name: inteltfjob
namespace: default
spec:
tfReplicaSpecs:
Ps:
nodeSelector:
intelrole: ps
replicas: 1
template:
metadata:
creationTimestamp: null
spec:
nodeSelector:
intelrole: ps
containers:
- args:
- nohup
- unbuffer
- python
- /opt/benchmarks/tf_cnn_benchmarks.py
- --batch_size=256
- --model=resnet50
- --variable_update=parameter_server
- --mkl=True
- --num_batches=100
- --num_inter_threads=2
- --num_intra_threads=40
- --data_format=NHWC
- --kmp_blocktime=1
- --local_parameter_device=cpu
image: docker.io/intelaipg/intel-optimized-tensorflow
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources: {}
workingDir: /home/benchmarks/tf_cnn_benchmarks.py
restartPolicy: OnFailure
Worker:
nodeSelector:
intelrole: worker
replicas: 2
template:
metadata:
creationTimestamp: null
spec:
nodeSelector:
intelrole: worker
containers:
- args:
- nohup
- unbuffer
- python
- /opt/benchmarks/tf_cnn_benchmarks.py
- --batch_size=500
- --model=resnet50
- --variable_update=parameter_server
- --mkl=True
- --num_batches=100
- --num_inter_threads=2
- --num_intra_threads=40
- --data_format=NHWC
- --kmp_blocktime=1
- --local_parameter_device=cpu
image: docker.io/intelaipg/intel-optimized-tensorflow
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources: {}
workingDir: /home/benchmarks/tf_cnn_benchmarks.py
restartPolicy: OnFailure
Note: The container image specified in the file, docker.io/intelaipg/intel-optimized-tensorflow, uses the Intel MKL-DNN library to optimize TensorFlow performance on Intel Xeon processors. Parameters recommended by Intel, such as using NUM_INTER_THREADS and NUM_INTRA_THREADS to specify inter- and intra-task parallelism, are passed as arguments to the training run to take advantage of all available cores on the Xeon CPU and maximize parallelism.
- To register the YAML file, run the following command:
$ oc apply -f tf_intel_cnn.yaml
- To run the Tensorflow benchmark by executing the TFJob, set the variables by running the following commands:
$ export KUBEFLOW_TAG=v0.5.0
$ export KUBEFLOW_SRC=${HOME}/kubeflow-${KUBEFLOW_TAG}
$ export KFAPP=kf-app
$ export CNN_JOB_NAME=inteltfjob
- Generate the ks component for tf-job-simple-v1beta1 by running the following command:
$ ks generate tf-job-simple-v1beta1 ${CNN_JOB_NAME} --name=${CNN_JOB_NAME}
- Deploy the TFJob to the cluster by running the following command:
$ ks apply default -c ${CNN_JOB_NAME}
- To view the logs of the running tfjob, run the following command:
$ oc get -n kubeflow -o yaml tfjobs ${CNN_JOB_NAME}
NAME AGE
Inteltfjob 1m
- Check that the pods for running the benchmark were launched by running the following command:
$ oc get pods
NAME READY STATUS RESTARTS AGE
inteltfjob-ps-0 0/1 Pending 0 4m
inteltfjob-worker-0 1/1 Running 0 4m
inteltfjob-worker-1 1/1 Running 0 4m
After the TFJob launches successfully, it is displayed in the TFJobs dashboard, as shown in the following figure:
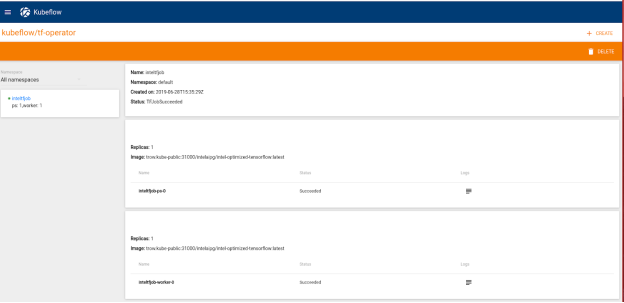
Figure 9. TFJobs dashboard