
Sequential IOzone Performance N Clients to N Files
Sequential IOzone Performance N Clients to N Files
-
Sequential N clients to N files performance was measured with IOzone version 3.492. Tests executed varied from single thread up to 1024 threads, and the results of the capacity expanded solution (4x PowerVault ME4084s + 4x PowerVault ME484s) are contrasted to the large size solution (4x PowerVault ME4084s).
Caching effects were minimized by using files big enough to avoid it, with a total data size of 8 TiB, more than two times the total memory size of servers and clients. It is important to note that GPFS uses the tunable page pool sets the maximum amount of memory used for caching data, regardless the amount of RAM installed and free (set to 32 GiB on clients and 96 GiB on servers to allow I/O optimizations). It is also important to note that while in other Dell Technologies HPC solutions, the block size for large sequential transfers is 1 MiB, GPFS was formatted with a block size of 8 MiB, and therefore that value or multiples of it, should be used on the benchmark for optimal performance. A block size of 8 MiB may look too large when using small files, however, GPFS uses subblock allocation to prevent waste. In the current configuration, each block was subdivided in 512 subblocks of 16 KiB each.
The following commands were used to execute the benchmark for writes and reads, where Threads was the variable with the number of threads used (1 to 512 incremented in powers of two), and threadlist was the file that allocated each thread on a different node, using sequential round-robin to spread them homogeneously across the 16 compute nodes. The variable FileSize has the result of 8192 (GiB) / Threads to divide the total data size evenly among all threads used. A transfer size of 16 MiB was used for this performance characterization.
./iozone -i0 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
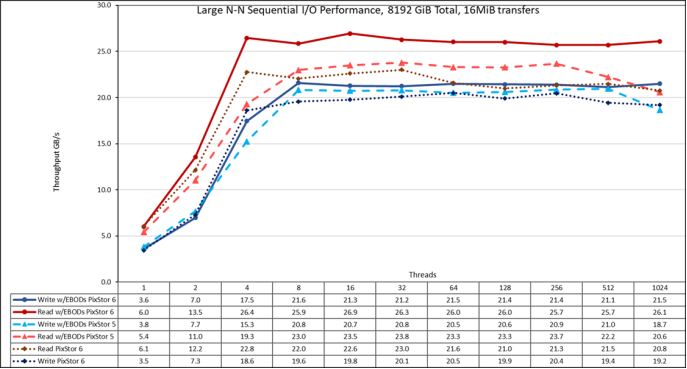
Figure 20. N to N sequential performance
From the results, we can observe that performance rises very fast with the number of clients used and then reaches a plateau that is stable until the maximum number of threads that IOzone allow is reached, and therefore large file sequential performance is stable even for 1024 concurrent clients. Note that both read and write performance benefited from the doubling the number of drives, but writes only slightly and reads significantly. The maximum read performance was limited by the bandwidth of the PowerVault ME4084 controllers used on the storage nodes starting at 4 threads. Similarly, the maximum write performance increased to 21.6 GB/s at 8 and 128 threads and it is closer to the PowerVault ME4 arrays’ maximum specs (22 GB/s).
Here it is important to remember that GPFS preferred mode of operation is scattered, and the solution was formatted to use such mode. In this mode, blocks are allocated from the very beginning of operations in a pseudo-random fashion, spreading data across the whole surface of each HDD. While the obvious disadvantage is a smaller initial maximum performance, that performance is fairly constant regardless of how much space is used on the file system. That is in contrast to other parallel file systems that initially use the outer tracks that can hold more data (sectors) per disk revolution, and therefore have the highest possible performance the HDDs can provide, however, as the system uses more space, inner tracks with less data per revolution are used, with the consequent reduction of performance.