
Random Small Blocks IOzone Performance N Clients to N Files
Random Small Blocks IOzone Performance N Clients to N Files
-
Random N clients to N files performance was measured with IOzone version 3.492. Tests executed varied from single thread up to 512 threads. This benchmark used 4 KiB blocks for emulating small blocks traffic.
Caching effects were minimized by setting the GPFS page pool tunable to 16GiB on the clients and 32 GiB on the servers and using files two times that size. The section titled Sequential IOzone Performance N Clients to N Files above has a more complete explanation about why this is effective on GPFS.
The following command was used to execute the benchmark in random I/O mode for both writes and reads, where Threads was the variable with the number of threads used (1 to 512 incremented in powers of two), and threadlist was the file that allocated each thread on a different node, using round robin to spread them homogeneously across the 16 compute nodes.
./iozone -i0 -c -e -w -r 16M -s ${Size}G -t $Threads -+n -+m ./threadlist
./iozone -i2 -O -w -r 4K -s ${Size}G -t $Threads -+n -+m ./threadlist
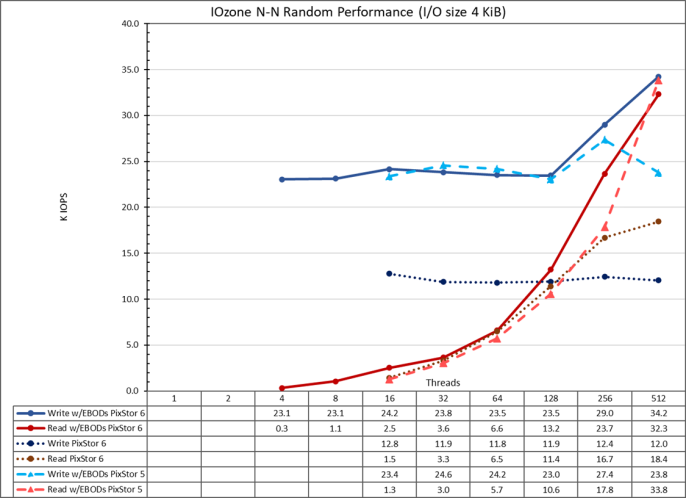
Figure 22. N to N random performance
From the results, we can observe that write performance starts at a high value of 23.1K IOPS at 4 threads and it remains at that level until suddenly rising at 256 threads and reaches a peak of 34.2K IOPS at 512 threads. This was not the expected behavior and more testing is needed to understand the cause.
Read performance on the other hand starts at 322 IOPS at 4 threads and increases performance almost linearly with the number of clients used (keep in mind that number of threads is doubled for each data point) and reaches the maximum performance of 32.33K IOPS at 512 threads. Using more threads will require more than the 16 compute nodes assigned to this testing, to avoid context switching and other related issues that may cause a lower apparent performance, where the arrays could in fact maintain the performance.