
None
None
-
ROCm Communication Collectives Library (RCCL) is a stand-alone library of standard collective communication routines for AMD GPUs. RCCL facilitates multi-GPU and multi-node communication for GPUs and networking. RCCL is topology aware of not only the internal GPU connectivity, but also of the internal PCIe topology along with the network architecture. See https://github.com/ROCm/rccl-tests for the rccl-tests source code, including compiling instructions.
AMD Instinct MI300X Infinity platform architecture: The eight AMD Instinct MI300X accelerators in the PowerEdge XE9680 server are placed on a Universal baseboard (UBB 2.0). There are eight Open Compute Project (OCP) Accelerator Modules (OAMs) that are connected in a mesh topology using AMD Infinity fabric. The AMD infinity fabric provides 128 GB/s bi-directional BW connectivity between each GPU. Each MI300X accelerator connects with its peers through seven XGMI links. The following figure shows an example of an eight-way mesh topology:
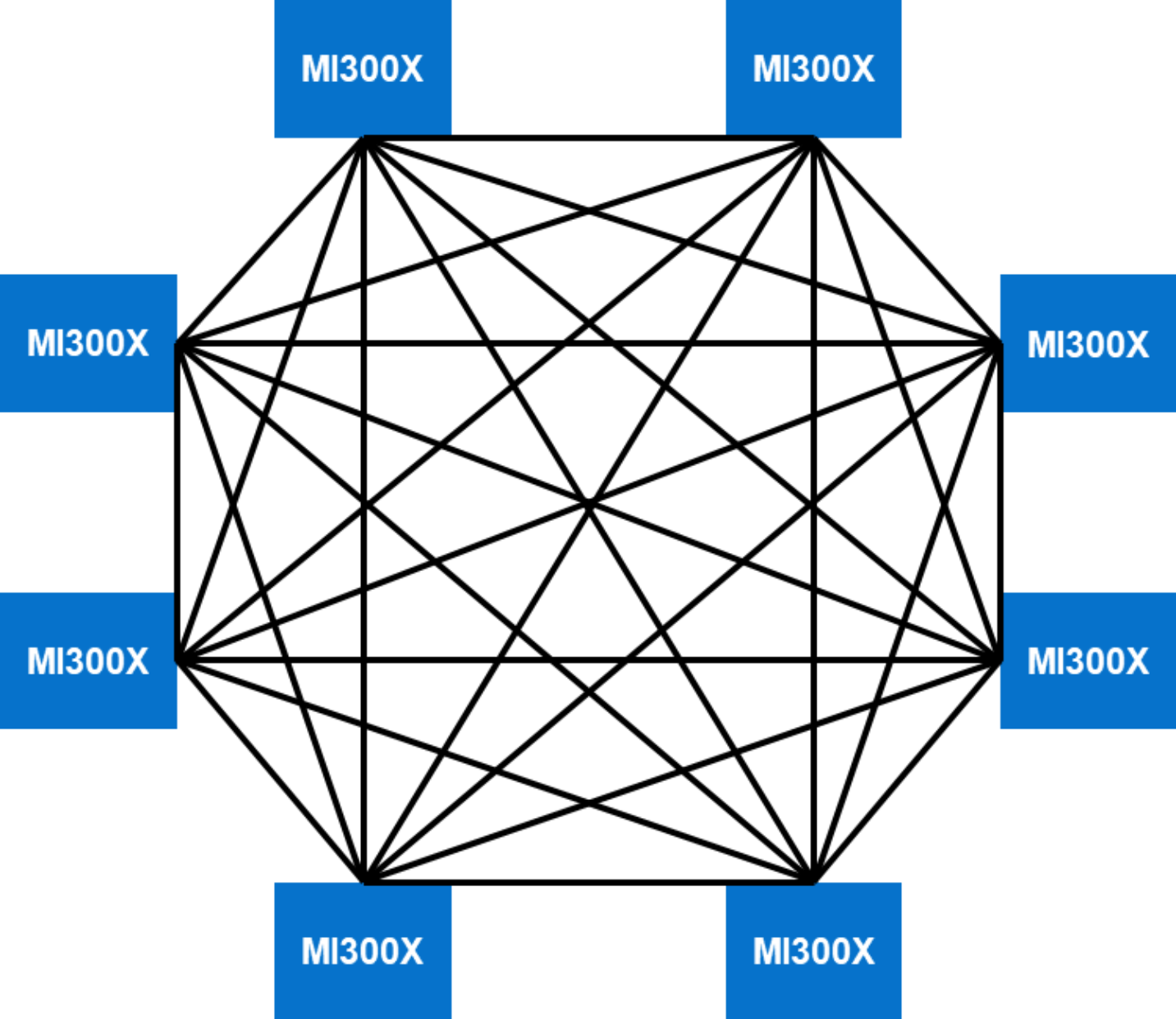
Figure 6. Eight-way mesh topology
Run the following command to run All Reduce performance benchmark on eight MI300X accelerators:
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 8
When running RCCL across all eight GPUs in a single PowerEdge XE9680 node, seven rings are formed. The RCCL test measures the throughput that can be achieved when running the selected collective communication test such as all_reduce across a single GPU. Thus, with each MI300X accelerator connected to seven peer GPUs and when running the all_reduce collective across seven rings, the achieved performance as measured comes to approximately 317 GB/s.