
IPoIB random writes and reads N-N
IPoIB random writes and reads N-N
-
To evaluate performance for HPC applications where multiple nodes access files concurrently with random IO patterns, IOzone version 3.492 is used in the random mode. Tests are conducted on thread counts starting from 1 up to 64 incremented by powers of two.

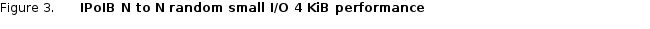
Record size is selected as 4KB to have transfers matching the operating system page size, which is normally an optimal small transfer size for the operating system. Each client first read and then wrote randomly 4GiB of data to a pre created file, to simulate concurrent small random data accesses using different moderately big files. The following figure shows the comparison of random write and read I/O performance of the Validated Design for NFS Storage and the previous version called NSS7.4-HA.From the figure, it is observed that the Validated Design for HPC NFS Storage has similar random write performance as the previous version of the solution for most data points, reaching a maximum of 7281 IOps at 32 threads on the new solution. The thread counts of 1 and 2, the new NFS Storage had a performance 69.5% and 49% higher compared to NSS7.4-HA. Those performance gains, in areas where the PowerVault ME4084 controllers have not reached their limits, especially with 1 or 2 threads, are due to faster server components, including 3200 MT/s memory, CPUs with more LLC, HDR higher messaging rates, and other OS improvements. After that point, performance is nearly the same for both solutions once they reach the max sustained performance, since operations must be written to disk before completion (since NFSv4 uses sync mounts by default), the PowerVault ME4084 controllers impose the limit observed.
The random read performance on the other hand, has a large variation among the results for the two solutions — mostly exhibiting lower IOps on the new system, except for the case of 2 threads, where there was an improvement of 73.7%. This solution seems to have one read plateau at low thread counts, and then increases from 8 to higher thread counts, reaching the peak performance of 11,405 IOps at 64 threads. In the previous release NSS7.4-HA, a peak performance of 16,607 IOps was also reached at 64 threads, which is 31.3%% higher than the current solution.
That can be partially due to server-side caching after file creation, that takes considerable effort to reduce or eliminate, and overdoing it can easily prevent any OS optimizations, precluding getting a reliable sustained performance.
One way to avoid that problem is using large enough total data as twice the amount of RAM in the server (or 512 GiB), but since IOps provided by HDDs are relatively low, executing such benchmarking can take weeks. Even more, since IOzone does not return any values until completion of the write or read stages, the test cannot be interrupted or fail without the need to restart that test that failed without any partial results. That kind of time investment is not always a feasible option.
Since random writes require ME4 controllers to calculate two parity sets per volume, random read performance is expected to be higher than write performance, but only to a degree since there is a limit on the random IOps spinning media can provide. Also affecting performance, read-ahead is an optimization normally done by the OS Block IO layer that can help read performance proportionally to the number of cache hits. However, cache hits should decrease as the total data size increases (reducing the probability of random blocks needed being already in memory), creating superfluous cache allocations and wasting time and resources reading data that most likely will not be used.
Based on preliminary causality work with Iozone and FIO (not included in this report), results with exceptionally large 4KiB IOPS on random read results are partially due to server reading data from cache, avoiding read disk operations. However, completely preventing any server caching (e.g., using a process that grabs most of the server memory and keeps it pinned during the test) results in extremely low performance, since the OS is not able to optimize anything on all the different OS layers, and several OS components may even stop working (e.g., if the OS Out of Memory Killer -OOMK is activated, terminating several HA daemons and other essential processes). In addition, the ME4 controllers require high IO pressure (queued requests) to reach maximum raw random read performance. As it was established by using FIO on raw devices (to eliminate the effect of a file system), with direct IO access to LUNs (to eliminate buffers) and setting read ahead to zero (to only transfer the 4KiB blocks requested and no additional data). IOzone does not seem to be the ideal benchmark for getting the max sustained read performance of 4KiB random IO loads. FIO can be a suitable candidate since it has more control over several aspects of the IO loads, and over execution time (e.g. stopping once sustained performance is reached, rate of change gets smaller than some threshold), but a deeper investigation is required.