
IPoIB metadata operations
IPoIB metadata operations
-
To get an idea of the maximum for typical metadata performance of the system, MDTest version 3.3.0 is used in these tests. The way that this tool was used can be seen as a quite simple emulation of a home directory solution, with many concurrent users, where users have a simple hierarchical directory structure, using 3K files per subdirectory, increasing the number of users from 1 to 512 in powers of two. Using empty files provides the ceiling numbers for files creates and deletes on such use case.
To make it accessible to all nodes, MDtest was compiled and then installed on each client. Since MDtest must be used with mpirun on a cluster, OpenMPI version 4.0.4rc3-1.51237 was selected, since it was included with the Mellanox OFED deployed on the clients. That version of OpenMPI was copied on a system used to start the tests (another PowerEdge R750 server unrelated to clients or NFS servers) and with the selected MPI version (with mpi-selector), to have a consistent configuration.
The following table describes the MDtest command-line arguments used from previous versions of this solution, which were selected to be able to compare performance results with the previous NFS Storage solution NSS7.4-HA. One goal is to use at least 1 million files for each metadata operation, and since the number of files per directory affect results, that number was kept fixed at 3000. The number of directories per thread was modified according to the number of threads used, to have close to 1M or more files per metadata test, for each iteration. Therefore, this work used the following parameters:
Table 6. Table Metadata Tests: Distribution of files and directories across threads
# Threads
# Files per directory
# Directories per thread
Total number of files
1
3000
320
960000
2
3000
160
960000
4
3000
80
960000
8
3000
40
960000
16
3000
20
960000
32
3000
10
960000
64
3000
8
1536000
128
3000
4
1536000
256
3000
4
3072000
512
3000
4
6144000
As the cluster has 16 compute nodes, in the graphs below, each client executed a one thread per node for thread counts up to 16. For thread counts of 32, 64, 128, 256, and 512, each client node executed respectively 2, 4, 8, 16 and 32 simultaneous threads.
On file creates in general, the new solution has significant improvements over the previous version NSS7.4-HA. There is a 12% improvement for one thread, and then 34% improvement from 2 to 8 threads. At 16 threads, an improvement of only 9% was observed, but after that point performance steadily increased, reaching 82.9% higher than the previous solution version at 512 threads, where the peak creates performance of 88,579 operations per second was observed.
Stat operations registered lower performance relative to the previous version NSS7.4-HA for low thread counts, -18%, -14% and -7% for 1,2, and 8 threads, respectively. Then, at high thread counts, mostly improved performance around 10% higher, except for 64 and 512 threads, where it was higher 17.3% and 25.6% respectively. Again, at 512 threads the peak stats performance of 581,734 operations per second was observed.
Overall, removal operations had significant improvements in performance compared to the previous NSS7.4-HA solution, even higher than create operations. Starting at 34% higher at 1 thread, increasing the relative improvement until reaching 106.6% at 32 threads, then decreasing the relative improvement to 40% at 128 threads, and increasing again at higher thread counts until reaching improvements of 86.7% at 512 threads. The peak removal performance of 87,469 operations per second was reached at 256 threads.
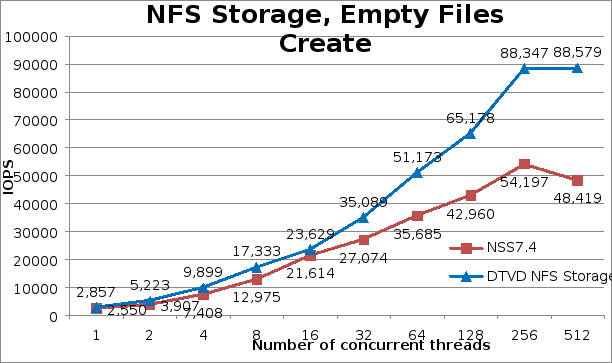
The following figures show respectively the results of files create, stat, and removal operations. Performance improvements for metadata operations, especially for create and removal, must be related to constant enhancements that XFS has received since Red Hat adopted it as the primary file system for the operation system, faster server components (3200 MT/s memory, CPUs with more LLC, HDR higher messaging rates), and improvements to other components in the I/O path. RHEL 8 also includes several tracing facilities, such as blktrace, bcc, bpftrace, pmtrace, fwtrace, llvm tools, Ftrace, perf and pcp), and some of them have an impressive number of XFS events (like perf) ), which can be very helpful to understand challenges and to make improvements.Figure 3. IPoIB file creates performance
Figure 5.

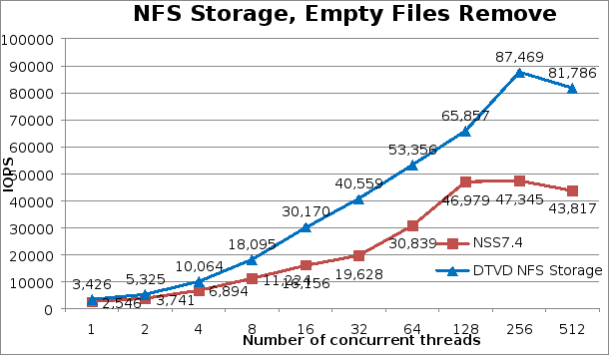

IPoIB files removal performance