
New T-SQL functions use cases
New T-SQL functions use cases
-
Overview
Microsoft SQL Server 2022 has introduced several new Transact-SQL (T-SQL) queries that can be used to gather additional analytical information. The functions tested by Dell’s software engineers in queries with internal and external data include GREATEST, LEAST, FIRST_VALUE, LAST_VALUE, STRING_SPLIT, GENERATE_SERIES, and DATE_BUCKET. These queries, which were added to Microsoft SQL Server 2022 allow for additional information to be gathered from data stored in a Dell Elastic Cloud Storage data lake. These queries were tested on data stored in Parquet files to simulate a realistic scenario. The data used for these queries comes from the US Weather dataset, the US AQI dataset, and Microsoft’s Wide World Importers dataset.
DATE_BUCKET Function
Function overview
Date buckets allow for data to be grouped according to ranges of dates which is especially useful. This query allows companies to analyze monthly profitability patterns. The DATE_BUCKET function supports parameters that allow for different increments of time to be selected, including hourly, monthly, and yearly. It is possible to allow for periods of several weeks or years to fall into the same bucket by modify the unit of time’s scalar. The start and end dates of the range can be specified, allowing for business data to be precisely analyzed.
Example Monthly DATE_BUCKET Query
SELECT DATE_BUCKET(MONTH, 1, DateOf) AS DayTemp, City,
AVG(Temperature) AS AvgMonthlyTemp
FROM Temperature_View
GROUP BY DATE_BUCKET(MONTH, 1, DateOf), City
ORDER BY DayTemp;
Results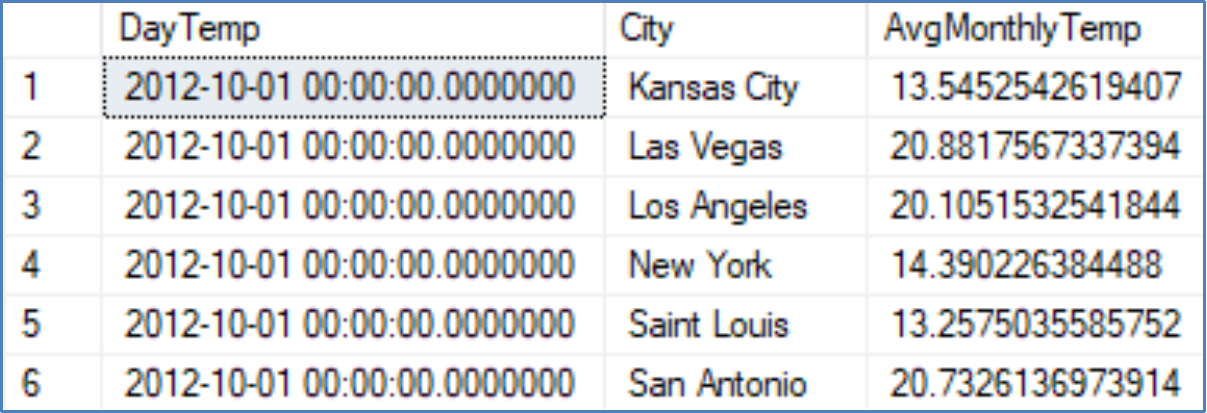
Query description
This query returns the average temperature for each city every month beginning on the first day of the month. It groups all the values that occur within the range of a month and then these groups can be aggregate.
Example Biweekly DATE_BUCKET Query
SELECT DATE_BUCKET(WEEK, 2, InvoiceDate) AS InvoiceWeek,
COUNT(CustomerId) AS CustomerCount
FROM WideWorldImporters.Sales.Invoices
GROUP BY DATE_BUCKET(WEEK, 2, InvoiceDate)
ORDER BY InvoiceWeek;
Results
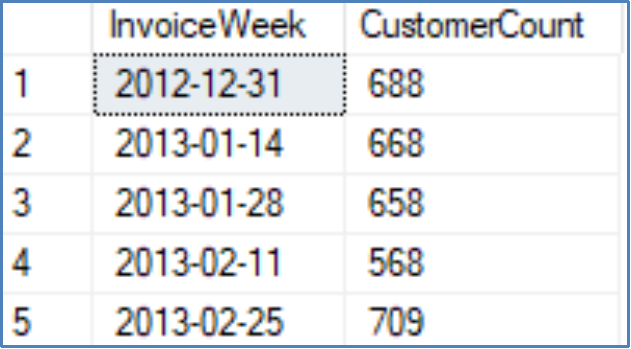
Query description
This query returns the biweekly counts of customers for each invoice. It demonstrates how custom time periods can be specified by users to acquire the preferred information.
GREATEST and LEAST Functions
Function Overview
The MIN and MAX functions do not always permit the retrieval of data in the preferred format. The GREATEST and LEAST T-SQL functions introduced for SQL 2022 allow for the retrieval of the maximum or minimum value of a row, respectively. This is useful for data analysts who could previously only find these values for columns. These functions can be used in SQL stored procedures and functions to select specific parameters.
Example GREATEST Query
SELECT DateTime, 32 + 9/5 * (
GREATEST([San_Antonio], [San_Diego], [San_Francisco], [Kansas_City], [Saint_Louis],
[Las_Vegas], [Los_Angeles], [New_York], Seattle)-273.15) AS HighestTemp
FROM Temperature
WHERE DateTime = '2012-10-01 13:00:00:000';
Results
Query description
This query selects the maximum temperature value from a list of columns for the row entry at a specified DateTime which is useful for perform comparisons between the values in a row. The relevant result can then be added as a new column in the resulting table.
Example LEAST Query
SELECT DateTime, 32 + 9/5 * (
LEAST([San_Antonio], [San_Diego], [San_Francisco], [Kansas_City], [Saint_Louis],
[Las_Vegas], [Los_Angeles], [New_York], Seattle)-273.15) AS LowestTemp
FROM Temperature
WHERE DateTime = '2012-10-01 13:00:00:000';
Results
Query description
This query selects the minimum temperature from a list of columns for each row entry at a specified DateTime.
GENERATE_SERIES Function
Function overview
GENERATE_SERIES is a function that allows for the creation of a series of numeric values. This is helpful for querying specific values or creating new data through joins. It can be used to create completely new data through string concatenation or mathematical operations. It is a powerful function for transforming data and has many use cases.
New String Creation with GENERATE_SERIES
WITH Series AS (
SELECT value AS SeriesId FROM GENERATE_SERIES(1,1000)
)
SELECT TOP 5 'employee'+(CONVERT (varchar (10), SeriesId)) AS Employees
FROM Series;
Results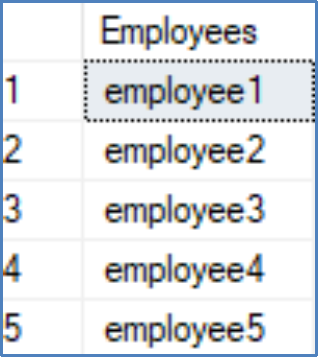
Query description
This example creates a series using the GENERATE_SERIES function and then creates a new table which is populated with numbered employee strings. It demonstrates one of the ways that the GENERATE_SERIES function can create new data.
Finding the First Occurrence of a Repeated Character Sequence Using GENERATE_SERIES
DECLARE @S VARCHAR(8000) = 'Aarrrgggh!';
SELECT value, S
FROM (
SELECT value=1, S=LEFT (@S, 1)
UNION ALL
SELECT value,
CASE
WHEN SUBSTRING(@S, value - 1, 1) <> SUBSTRING(@S, value, 1)
THEN SUBSTRING(@S, value, 1)
END
FROM GENERATE_SERIES(1, 100)
WHERE value BETWEEN 2 AND LEN(@S)
) AS A
WHERE S IS NOT NULL;
Results
Query Description
GENERATE_SERIES can be used to provide additional information regarding the indexing of values. In this case, the string’s repeat character sequences are associated with their ordinal position and the first occurrence of the character in a sequence of identical characters has its index retained to condense string information.
STRING_SPLIT Function
Function overview
The STRING_SPLIT function can split a string into substrings by using a delimiter. The function creates a column containing the substring values and another column with their ordinal position if the ordinal option is enabled. This can be used to analyze frequent words within a column of strings. It can also be used to select and clean substrings to them in an understandable format. For example, each string in a row might contain an employee’s name and badge number. A string split could be used for all the strings in a column and only retrieve the names of employees to display in a view to a user who should not be privileged to see both the employees’ badge numbers and names by using the ordinal option.
Substring Extraction Example with STRING_SPLIT
SELECT D.[Primary Contact], D.Customer, D.FirstName, value City
FROM (
SELECT C2.[Primary Contact], C2.Customer, C2.FirstName, value C2v, ordinal C2o
FROM (
SELECT B.[Primary Contact], B.Customer, B.FirstName, value Bv, ordinal Bo
FROM (
SELECT *
FROM (
SELECT value AS FirstName, C.[Primary Contact], C.Customer
FROM Customer C
CROSS APPLY STRING_SPLIT(C.[Primary Contact], ' ',1)
WHERE ordinal = 1
) AS NS
WHERE Customer <> 'Unknown' AND Customer NOT LIKE '%Head Office%'
) B CROSS APPLY STRING_SPLIT(B.Customer, '(', 1) WHERE ordinal = 2 ) B2
CROSS APPLY STRING_SPLIT(Bv, ')', 1)
WHERE ordinal = 1) D CROSS APPLY STRING_SPLIT(C2v, ',', 1)
WHERE ordinal = 1;
Results

Query description
The city name of each value stored in the customer column is added to the row in this example query. The function splits strings and uses the ordinal property to extract the required substring. This allows data transformation entirely in Microsoft SQL Server.
FIRST_VALUE and LAST_VALUE Functions
Function overview
The FIRST_VALUE and LAST_VALUE functions are nondeterministic because the order by function is nondeterministic, which changes the first and last values depending on the conditions chosen when there are multiple equal values. These functions are helpful for rapidly determining the first and last values that appear in a table or partition. This can be used to find the item with the minimum price and populate its name alongside all the other items in that table’s partition which is an additional functionality not previously available to the MIN and MAX functions without performing a self-join. Partitions can provide great value because they allow for more data insights to be easily visualized by a single query.
Example FIRST_VALUE Query
SELECT City, DateOf, Temperature,
FIRST_VALUE(City) OVER (PARTITION BY DateOf ORDER BY Temperature ASC) AS ColdestCity
FROM Temperature_View
ORDER BY DateOf;
Results

Query description
The FIRST_VALUE function selects the first value in each partition. In this case, the partitions are based on the DateOf values. The first ordered column partition value can be selected and added as a new column without the need for a self-join.
Example LAST_VALUE Query
SELECT City, DateOf, Temperature, LAST_VALUE(City)
OVER (
PARTITION BY DateOf
ORDER BY Temperature ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS HottestCity
FROM Temperature_View
ORDER BY DateOf;
Results
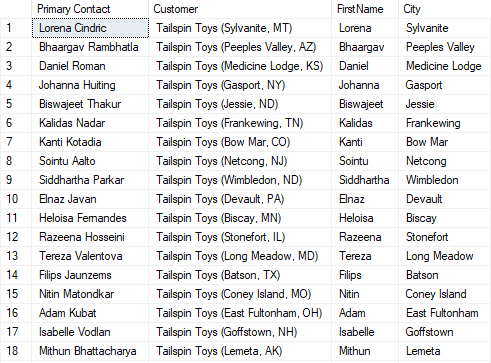
Query description
LAST_VALUE is less intuitive than the FIRST VALUE function, and extra care must be taken to implement it correctly. The simplest use case, however, is to combine FIRST_VALUE and use descending order to emulate the LAST_VALUE function. Thanks to ordering the two functions’ roles are highly interchangeable.
The reason that the LAST_VALUE function is less intuitive is framing. A frame refers to a set of rows for the window which is usually smaller than a partition. The default frame contains the rows between the current row and the first row. For example, with row 5, the window holds the values of rows 1 through 5. FIRST_VALUE includes the first row by default and so this concept does not interfere with retrieving the desired results.
The window only goes up to the current row for the default LAST_VALUE frame. To circumvent this, specify the following frame, ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING. This forces the window to begin with the current row and end at the last row of the partition and provides the expected query results.