
Data virtualization use case
Data virtualization use case
-
Data virtualization does not require information about the data’s format and storage location which revolutionizes data retrieval and manipulation. This allows data integration to occur without needing to copy or move data that is stored in a separate location. A single virtual layer can span multiple storage formats and physical locations.
Accesing external data
Microsoft has added object storage access to the already existing PolyBase features in SQL Server 2022. This allows the use of data virtualization to take full advantage of the benefits of object storage. This new introduction allows for a SQL server instance to directly query data from SQL server and outside data sources. It even permits T-SQL to combine local and external data. This feature is not enabled by default, and it must be installed and enabled on the server instance to be used.
PolyBase
PolyBase’s installation status is checked with the following query:
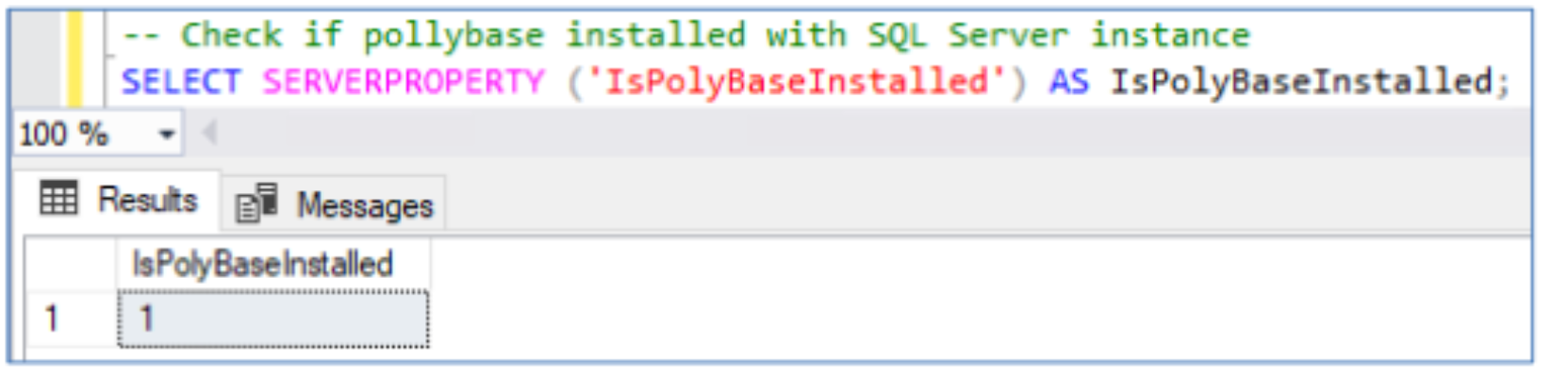
The following stored procedure is run to enable PolyBase:
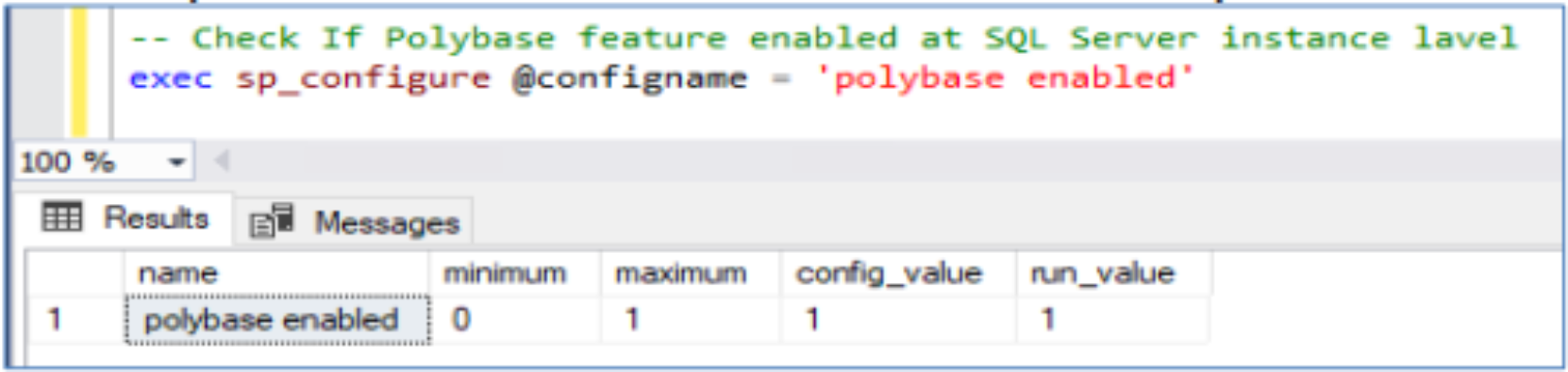
Run the following stored procedure to verify that PolyBase is enabled:

Encryption and communication setup
To access an external data source, an encryption key is used to verify that communication between the external data source and the SQL Server instance is secure. Dell Elastic Cloud Storage is used as the external data source in this example.
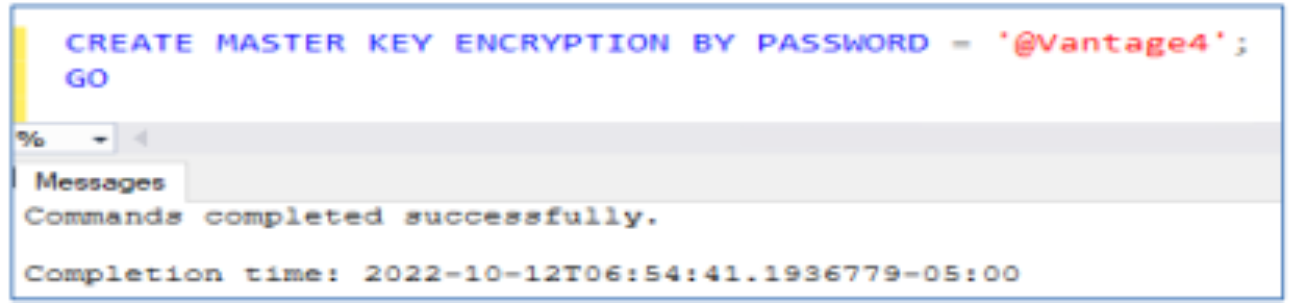
- Create the encryption key in the SQL Server instance.
- Create database scope credentials within the database.

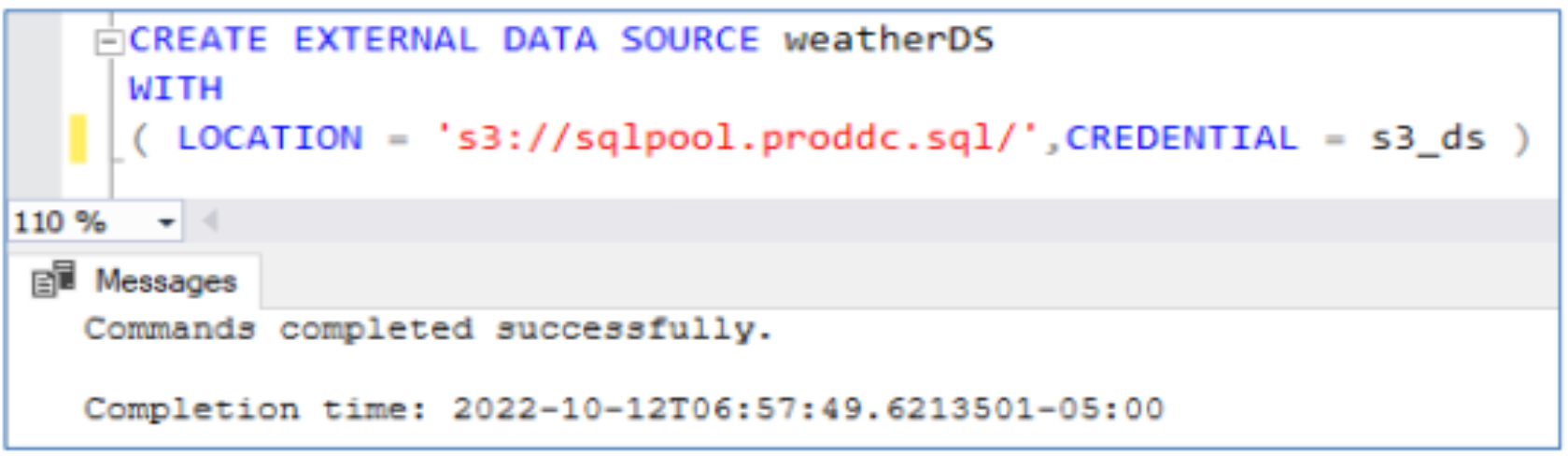
- Establish a connection with the external data source by pointing to the S3 storage URL and passing the database scoped credentials.
- Use OPENROWSET to validate that the data located in ECS is reachable.
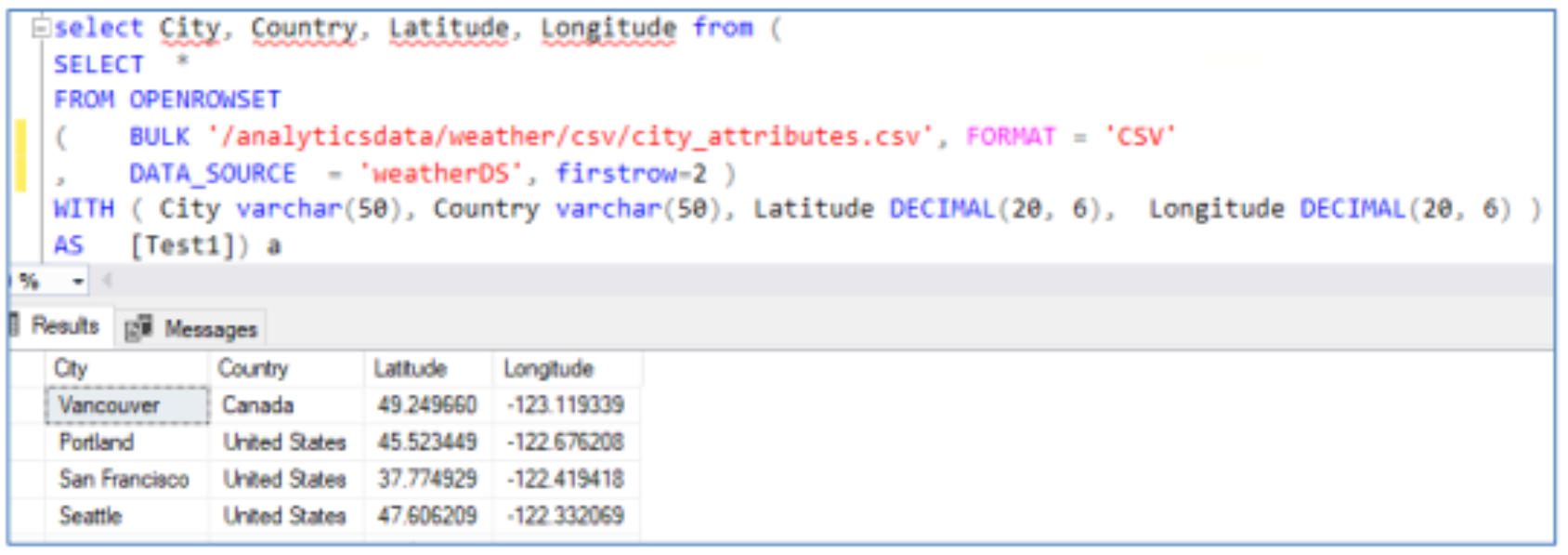
Creating external tables through the use of select queries
CREATE EXTERNAL TABLE AS SELECT (CETAS) allows for the creation of external tables using data that is not present on a local Microsoft SQL Server 2022 instance. Data virtualization is valuable for enterprises engaging with large volumes of data as a part of their daily operations and CETAS makes this process easy. Data virtualization allows all types of data to be accessed from one place which hides the underlying complexity of heterogeneous data and gives data specialists direct data access. Data virtualization requires no extra infrastructure for data and allows new applications to be integrated with existing infrastructure which eliminates wasteful data silos and reduces costs.
Data virtualization with parquet files
Parquet is an open-source datafile format created by Apache that is designed for efficient data storage and retrieval. The data in a Parquet file is stored in columnar format and uses efficient data compression and encoding schemes. Parquet files provide the enhanced performance needed for handling complex data at scale. These files were designed by Apache to be a common interchange format for both interactive and batch workloads.
Traditional database engines such as SQL Server store data in row-based comma separated files, however in SQL Server 2022, T-SQL queries enable the conversion of csv files to Parquet using CREATE EXTERNAL TABLE AS SELECT (CETAS) with the OPENROWSET syntax. Using these features, it is possible to join relational data in SQL with efficiently stored non-relational data located in object storages such as Dell’s Elastic Cloud Storage. It is possible to use CETAS queries to create external datasets in Parquet file format without ever landing the data within the SQL server instance. The following is an example of creating an external dataset with CETAS.

It is also possible to convert table data to Parquet through CETAS. The following is an example this command:CREATE CREDENTIAL [s3://<ECS Bucket URL>]
WITH IDENTITY = ‘S3 Access Key’,
SECRET = ‘sqluser:<Username>/<Password>’;
CSV data can be converted to Parquet using CETAS and OPENROWSET together. Here is a command that accomplishes this:
CREATE EXTERNAL TABLE ext_city_attributes
WITH
(
LOCATION = '/analyticsdata/weather/parquet/ext_city_attributes.parquet',
DATA_SOURCE = weatherDS,
FILE_FORMAT = ParquetFileFormat
) AS
SELECT City, Country, Latitude, Longitude
FROM (
SELECT *
FROM OPENROWSET
(
BULK '/analyticsdata/weather/csv/city_attributes.csv',
FORMAT = 'CSV',
DATA_SOURCE = 'weatherDS',
FIRSTROW=2
)
WITH (
City VARCHAR(50),
Country VARCHAR(50),
Latitude DECIMAL(20, 6),
Longitude DECIMAL(20, 6)
) AS Test1
) AS A;
PySpark can also be used to convert the data from CSV to Parquet as shown below:
import os
import sys
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
import findspark
findspark.init()
import pyspark
import findspark
findspark.init()
sc = pyspark.SparkContext(master='spark://spark1n.proddc.sql:7077')
sc._jsc.hadoopConfiguration().set("mapreduce.fileoutputcommitter.marksuccessfuljobs", "false")
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("'spark://spark1n.proddc.sql:7077'").getOrCreate()
from pyspark.sql import SQLContext
sqlContext = spark.builder.getOrCreate()
from pyspark.sql.types import *
schema = StructType([
StructField("City", StringType(), True),
StructField("Country", StringType(), True),
StructField("Latitude", DoubleType(), True),
StructField("Longitude", DoubleType(), True)
])
rdd = sc.textFile("csv/city_attributes.csv").map(lambda line: line.split(","))
rdd = rdd.zipWithIndex().filter(lambda tup: tup[1] > 14).map(lambda x:x[0])
rdd = rdd.map(lambda p: (p[0], p[1], float(p[2]), float(p[3]) ) )
df = sqlContext.createDataFrame(rdd, schema)
df.printSchema()
df.show()
df.write.mode("overwrite").parquet("city_attributes.parquet")
These different methods of converting data to and from Parquet files serve different purposes. The OPENROWSET use case works well for small batches of data that can quickly run and for scenarios where it is not necessary to have immediate access to the database. Large workloads can take many hours to run and would use the resources required for regular database operations to convert data to a different format. In these cases, it is more practical to rely on a platform such as PySpark to handle the data conversion without utilizing resources meant for analytical processes.
Accessing external data
External tables simplify working with data outside of SQL Server, using PolyBase to access the external data. When creating external tables, information about the file format is required along with the data source, and location of the files. An external file format must be specified in SQL Server:
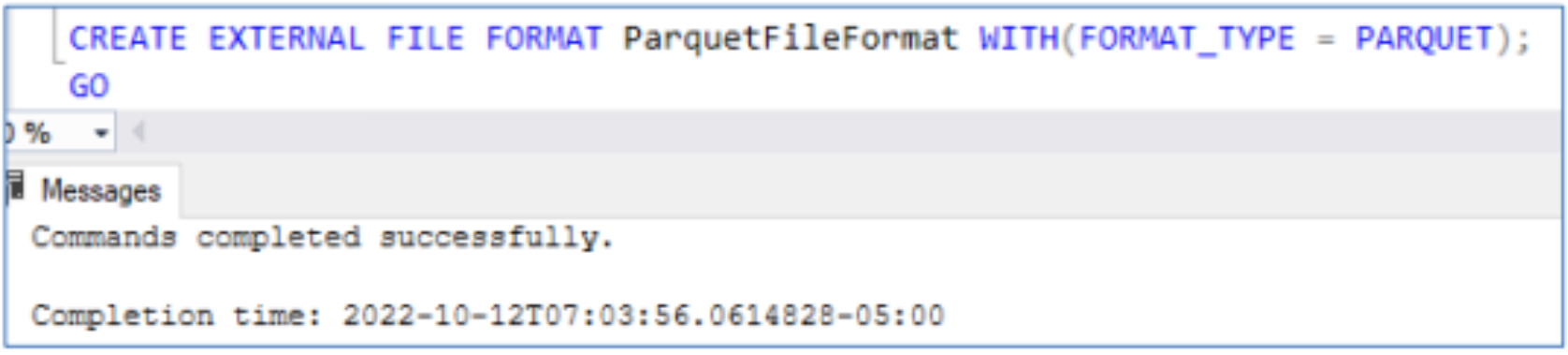
Users can create an external table from the data on S3 compatible storage by providing the file location, the data source and file format as shown in the following screenshots.
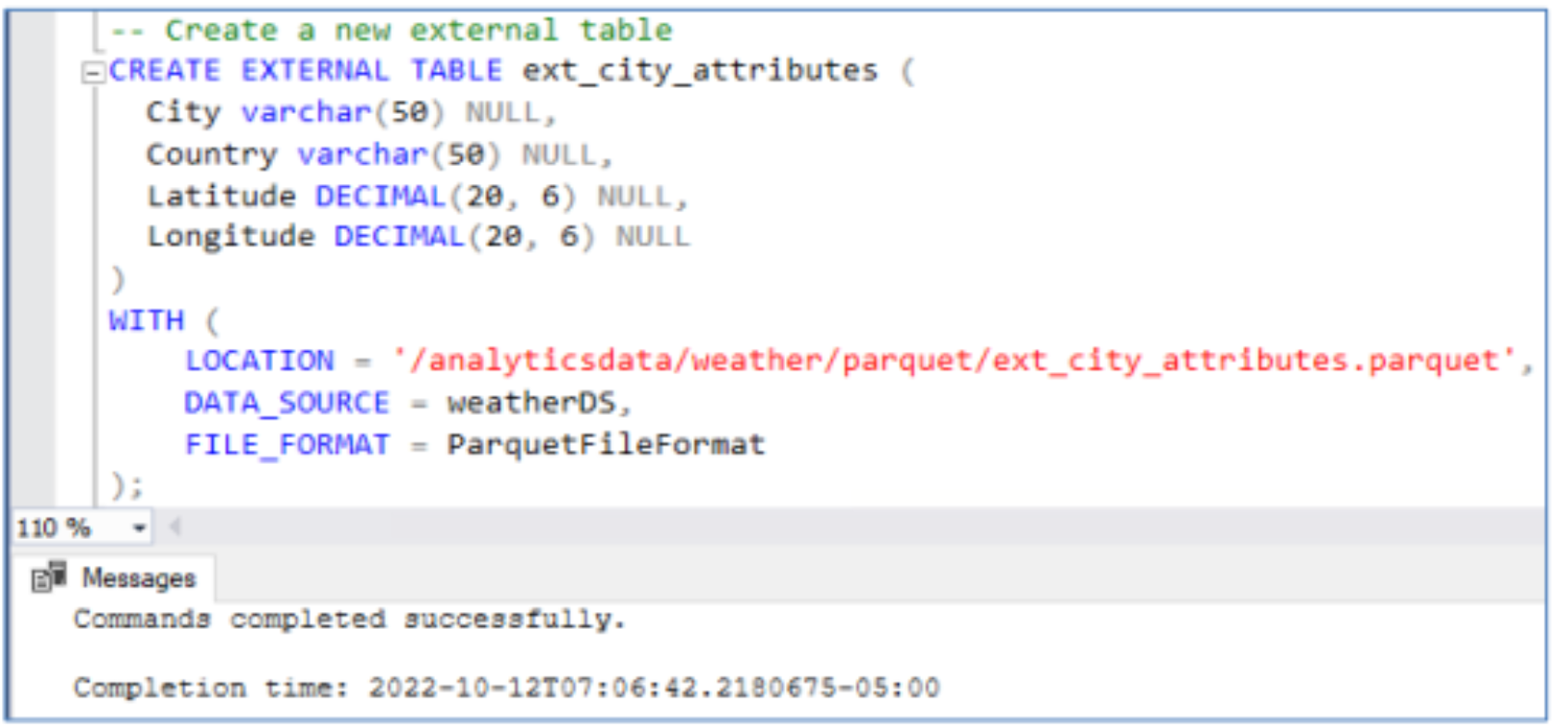
Once the external table has been created, data can be queried.

It is not currently possible to have multicolumn statistics for external data. It is possible to create statistics for singular columns of external tables which can improve performance.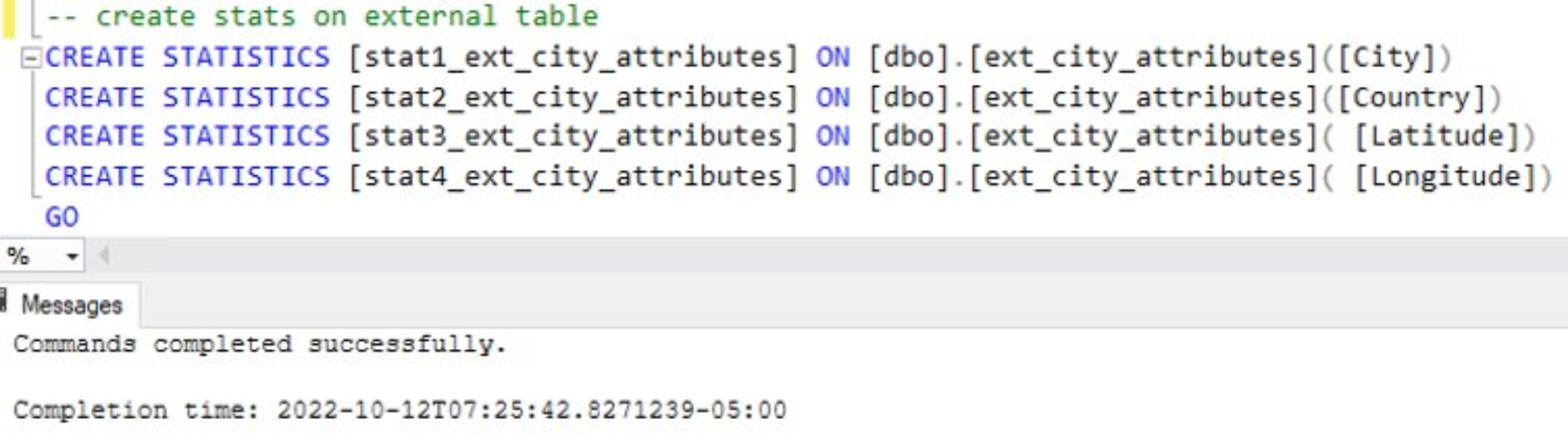
Creating statistics is costly and it is not always practical or necessary to have statistics for all a table’s columns. It is more useful to simply have statistics for fields such as City and Country which would likely need to be accessed more frequently than the other table attributes. This is akin to the rational used for creating indexes. This allows for a more effective use of system resources. It is important to consider cardinality when creating statistics for databases as depending on the cardinality the statistic may provide no benefits for queries that attempt to use it. This is especially true with large volumes of externally stored data where statistics must be manually generated by the user.Data virtualization testing details
The Dell solutions engineering team conducted tests and performed research to determine the feasibility of reading hundreds of millions of records from ECS. This is was an extremely important consideration when evaluating the practical use of external data with Microsoft SQL Server 2022 for data analytics. To validate this, the relational data present in the SalesOrderDetail table from Microsoft’s AdventureWorks database was joined with an external table. The SalesOrderDetail table had 121,000 records and the external table backed up by Parquet files on Dell ECS contained 200 million records. The following is an example of such a query that demonstrates the join completing within seconds.
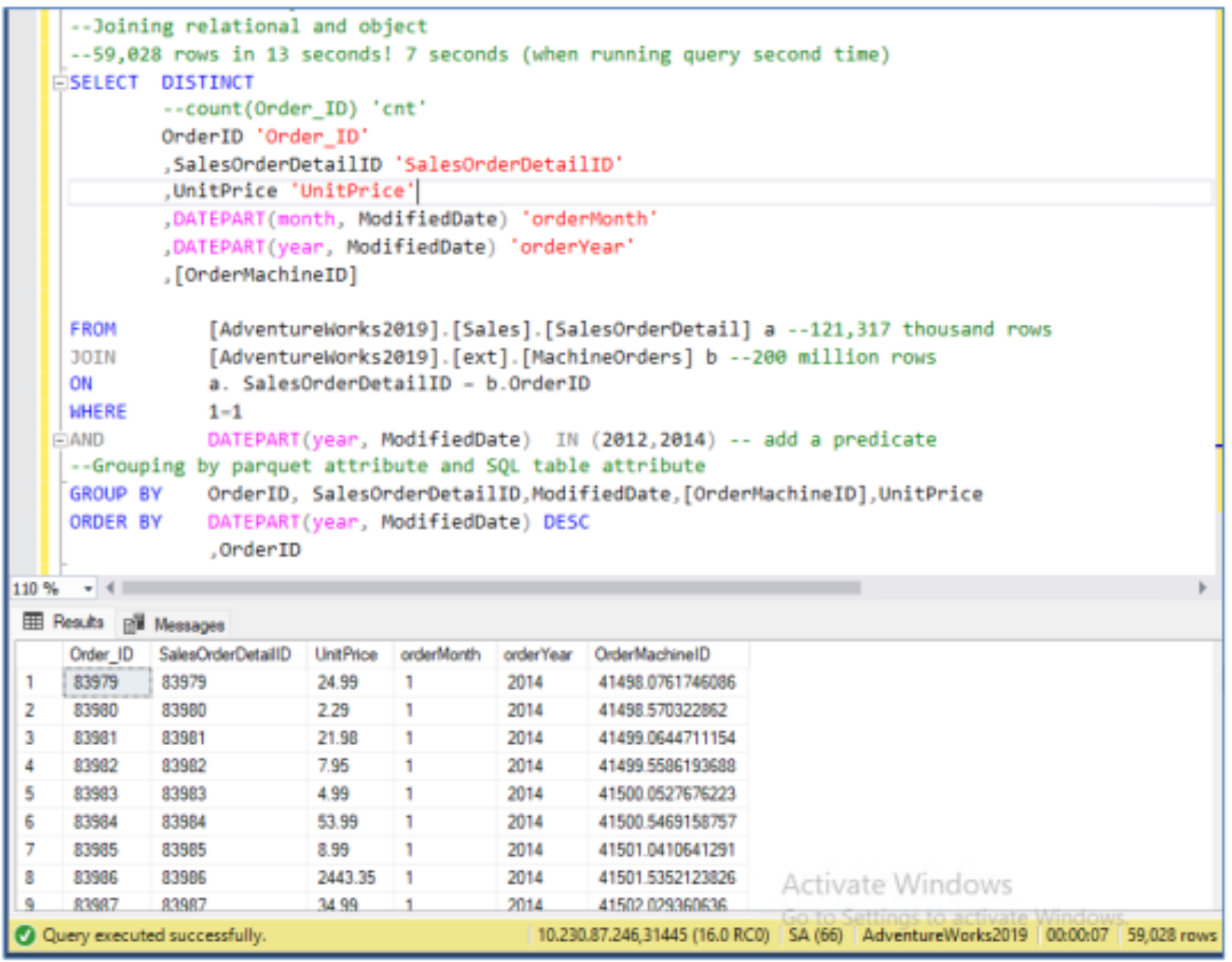
Dell solutions engineers also used Microsoft SQL Server to query data that resided externally on ECS. Two external tables backed up in CSV files were joined. These tables contained one and five million records.
This allows for semi-structured and unstructured data to be kept externally from SQL Server in a more affordable object storage such as Dell ECS without hindering performance. Accessing data this way creates countless opportunities for performing ETL/ELT workflows and offloading the ETL/ELT process altogether.
- Create the encryption key in the SQL Server instance.