
Model customization validation
Model customization validation
-
The goal of our validation is to ensure the reliability, optimal performance, scalability, and interoperability of the system. Model customization yields an LLM that incorporates domain-specific knowledge. We validated our design to ensure the functionality of model customization techniques available in the NeMo framework. Our goal in this validation was not to train a model to convergence. The following list provides the details of our validation setup:
- Foundational models—We validated 7B, 13B, and 70B Llama 2
- Model customization techniques—We used the following techniques:
- Prompt engineering—The following section shows the prompt engineering results.
- SFT, P-Tuning, and LoRA—The next sections show the results of these fine-tuning methods. Appendix A shows the Slurm scripts that we used to launch the jobs.
- Cluster configuration—We used both Slurm and Kubernetes clusters.
- Dataset—We used two datasets for this validation:
- Dolly dataset from Databricks (databricks-dolly-15k) is an open-source dataset of instruction-following records generated by thousands of Databricks employees in several of the behavioral categories outlined in the InstructGPT paper. The categories include brainstorming, classification, closed QA, generation, information extraction, open QA, and summarization.
- Alpaca is a dataset of 52,000 instructions and demonstrations generated by OpenAI's text-davinci-003 engine. This instruction data can be used to conduct instruction-tuning for language models and make the language model follow instructions better.
- Time for training—Usually, data scientists train a model until it reaches convergence, a point influenced by factors like the dataset, model complexity, and chosen hyperparameters. Our aim was not to achieve convergence for every scenario, as it is specific to our chosen dataset and parameters, offering limited insight into a customer's needs. To maintain a consistent metric across all scenarios, we conducted training jobs for a minimum of 50 steps.
Prompt engineering validation
The following table provides examples of prompt engineering results from our validation work and how the response from the model can be shaped using specific prompts:
Table 10. Examples of prompt engineering for describing the earth[4]
Prompt
Response from Llama 2 70B model
In a sentence can you creatively describe the planet earth to a five-year-old?
I’m not sure I can do it in a sentence, but I’ll give it a try.
The Earth is a big, round ball that is covered with water and land.
How would you concisely describe planet earth to a high school senior?
I would say that the Earth is a planet that is the only one in the solar system that has life on it. It is the third planet from the Sun and is the largest of the terrestrial planets.
Can you write a multiline poem to describe the planet earth?
The earth is a beautiful place,
With its mountains and valleys,
And its oceans and seas.
It’s a place of wonder and awe,
Where life can be found in abundance,
And where the sun shines bright.
The earth is a place of mystery,
With its secrets yet to be discovered,
And its beauty yet to be seen.
It’s a place of hope and promise,
Where dreams can come true,
And where the future is bright.
The earth is a place of love,
Where people can come together,
And where peace can be found.
[4] The results are from the Llama 2 70B model with the following parameters: top_k=1, top_p=0.1, and temperature=0.5.
SFT and PEFT validation
The following table summarizes the scenarios we validated and the configuration that we used.
Note: In the table, TP refers to Tensor Parallelism and PP refers to Pipeline Parallelism.
Table 11. Validated scenario configuration
Llama 2 7B
Llama 2 13B
Llama 2 70B
Validated on one to four PowerEdge R760xa servers with L40S
SFT
Number of GPUs: 4, 8, 16
TP: 8
PP: 1
Maximum number of steps: 100
Number of GPUs: 4, 8, 16
TP: 8
PP: 1
Maximum number of steps: 100
N/A
P-Tuning
Number of GPUs: 4, 8, 16
TP: 2
PP: 1
Maximum number of steps: 100
Number of GPUs: 4, 8, 16
TP: 2
PP: 1
Maximum number of steps: 100
Number of GPUs: 16
TP: 8
PP: 1
Maximum number of steps: 100
LoRA
Number of GPUs: 4, 8, 16
TP: 1
PP: 2
Maximum number of steps: 100
Number of GPUs: 4, 8, 16
TP: 1
PP: 4
Maximum number of steps: 100
Number of GPUs: 16
TP: 1
PP: 8
Maximum number of steps: 100
Validated on a single PowerEdge XE9680 server or two PowerEdge XE8640 servers (multinode)
SFT
Number of GPUs: 8
TP: 2
PP: 1
Maximum number of steps: 50
Number of GPUs: 8
TP: 4
PP: 1
Maximum number of steps: 50
N/A
P-Tuning
Number of GPUs: 4,8
TP: 1
PP: 1
Maximum number of steps: 1000
Number of GPUs: 4,8
TP: 2
PP: 1
Maximum number of steps: 1000
Number of GPUs: 8
TP: 8
PP: 1
Maximum number of steps: 1000
LoRA
Number of GPUs: 4,8
TP: 1
PP: 1
Maximum number of steps: 1000
Number of GPUs: 4,8
TP: 2
PP: 1
Maximum number of steps: 1000
Number of GPUs: 8
TP: 8
PP: 1
Maximum number of steps: 1000
Validated on two PowerEdge XE9680 servers (multinode)
SFT
Number of GPUs: 16
TP: 2
PP: 1
Maximum number of steps: 50
Number of GPUs: 16
TP: 4
PP: 1
Maximum number of steps: 50
N/A
P-Tuning
Number of GPUs: 16
TP: 1
PP: 1
Maximum number of steps: 1000
Number of GPUs: 16
TP: 2
PP: 1
Maximum number of steps: 1000
Number of GPUs: 16
TP: 8
PP: 1
Maximum number of steps: 1000
LoRA
Number of GPUs: 16
TP: 1
PP: 1
Maximum number of steps: 1000
Number of GPUs: 16
TP: 2
PP: 1
Maximum number of steps: 1000
Number of GPUs: 16
TP: 8
PP: 1
Maximum number of steps: 1000
To illustrate the validation, we provided a few example results. To see the Slurm batch file that initiates the model customization job, see Appendix A.
The following figure illustrates the training loss for Llama 2 70B on a single node 8-GPU run. Note that the graphs show the validation of model customization, and not necessarily the optional hyperparameter configuration (such as learning rate):
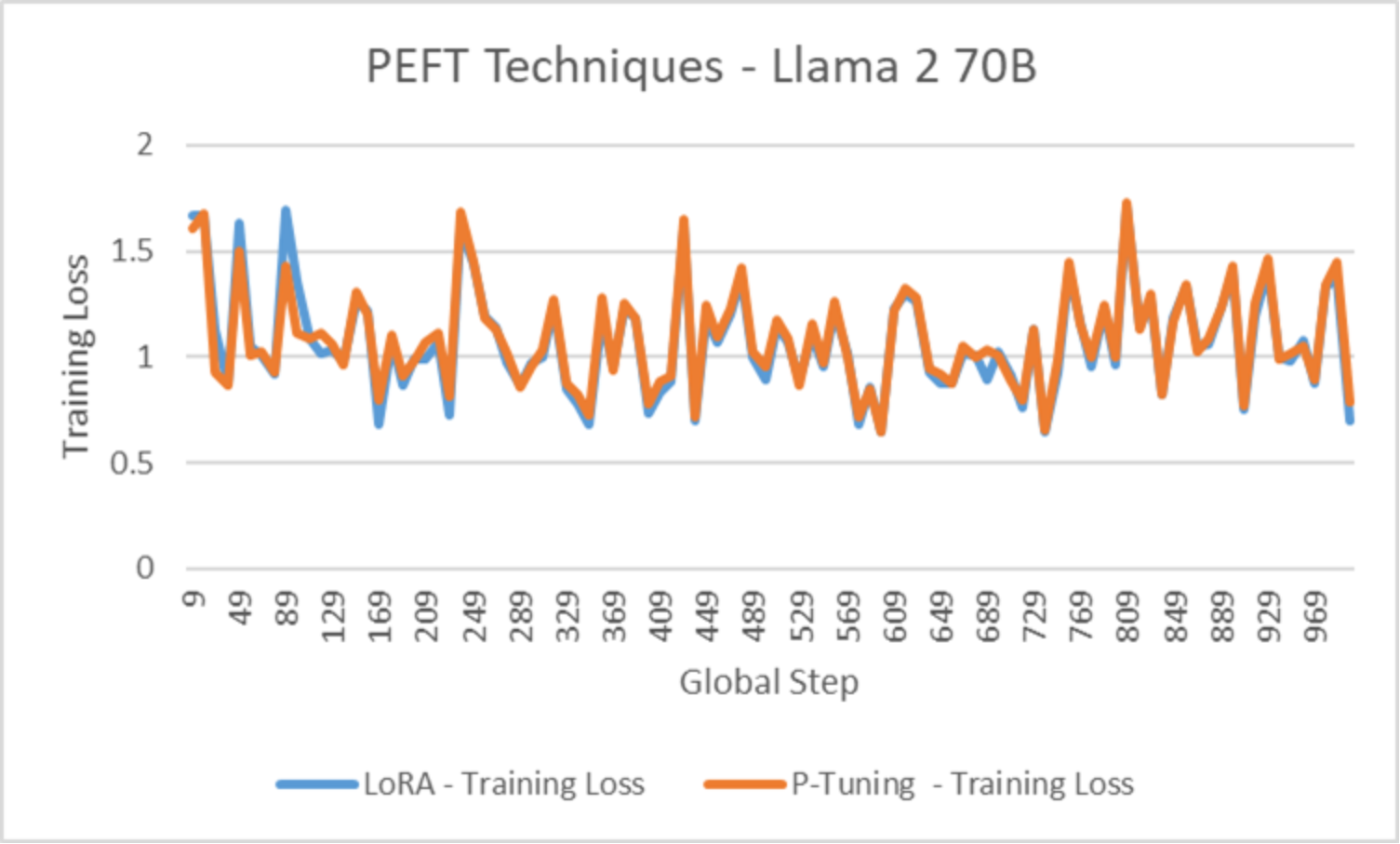
Figure 7. Training loss for Llama 2 70BFor the same experiments, the following figure shows how the learning rate adapted during model customization:
Figure 8. Learning rate adapted during model customization