
None
None
-
Dell Technologies provides a diverse selection of acceleration-optimized servers with an extensive portfolio of accelerators featuring NVIDIA GPUs. In this design, we showcase three Dell PowerEdge servers with several GPU options tailored for generative AI purposes:
- PowerEdge R760xa server, capable of supporting up to four NVIDIA H100 GPUs or four NVIDIA L40S GPUs
- PowerEdge XE8640 server, supporting four NVIDIA H100 GPUs
- PowerEdge XE9680 server, supporting eight NVIDIA H100 GPUs
In this section, we describe the configuration and connectivity options for NVIDIA GPUs, and how these server-GPU combinations can be applied to various LLM use cases.
NVIDIA GPUs configurations
This design for inferencing supports several options for NVIDIA GPU acceleration components. The following table provides a summary of the GPUs used in this design:
Table 2. NVIDIA GPUs – Technical specifications and use cases
NVIDIA H100 SXM GPU
NVIDIA H100 PCIe GPU
NVIDIA L40S PCIe GPU
Supported latest PowerEdge servers (and maximum number of GPUs)
PowerEdge XE9680 (8)
PowerEdge XE8640 (4)
PowerEdge R760xa (4)
PowerEdge R760xa (4)
GPU memory
80 GB
80 GB
48 GB
Form factor
SXM
PCIe (dual width, dual slot)
PCIe (dual width, dual slot)
GPU interconnect
900 GB/s PCIe
600 GB/s NVLink Bridge supported in PowerEdge R760xa
128 GB/s PCIe Gen5
None
Multi-instance GPU support
Up to 7 MIGs
Up to 7 MIGs
None
Max thermal design power (TDP)
700 W
350 W
350 W
NVIDIA AI Enterprise
Add-on
Included with H100 PCIe
Add-on
Most applicable use cases
Generative AI training
Large scale distributed training
Discriminative/Predictive AI Training and Inference
Generative AI Inference
Discriminative/Predictive AI Inference
Gen AI Inferencing
GPU connectivity
NVIDIA GPUs support various options to connect two or more GPUs, offering various bandwidths. GPU connectivity is often required for certain multi-GPU applications, especially when higher performance and lower latency are crucial. LLMs often do not fit in the memory of a single GPU and are typically deployed spanning multiple GPUs. Therefore, these GPUs require high-speed connectivity between them.
NVIDIA NVLink is a high-speed interconnect technology developed by NVIDIA for connecting multiple NVIDIA GPUs to work in parallel. It allows for direct communication between the GPUs with high bandwidth and low latency, enabling them to share data and work collaboratively on compute-intensive tasks.
The following figure illustrates the NVIDIA GPU connectivity options for the PowerEdge servers used in this design:
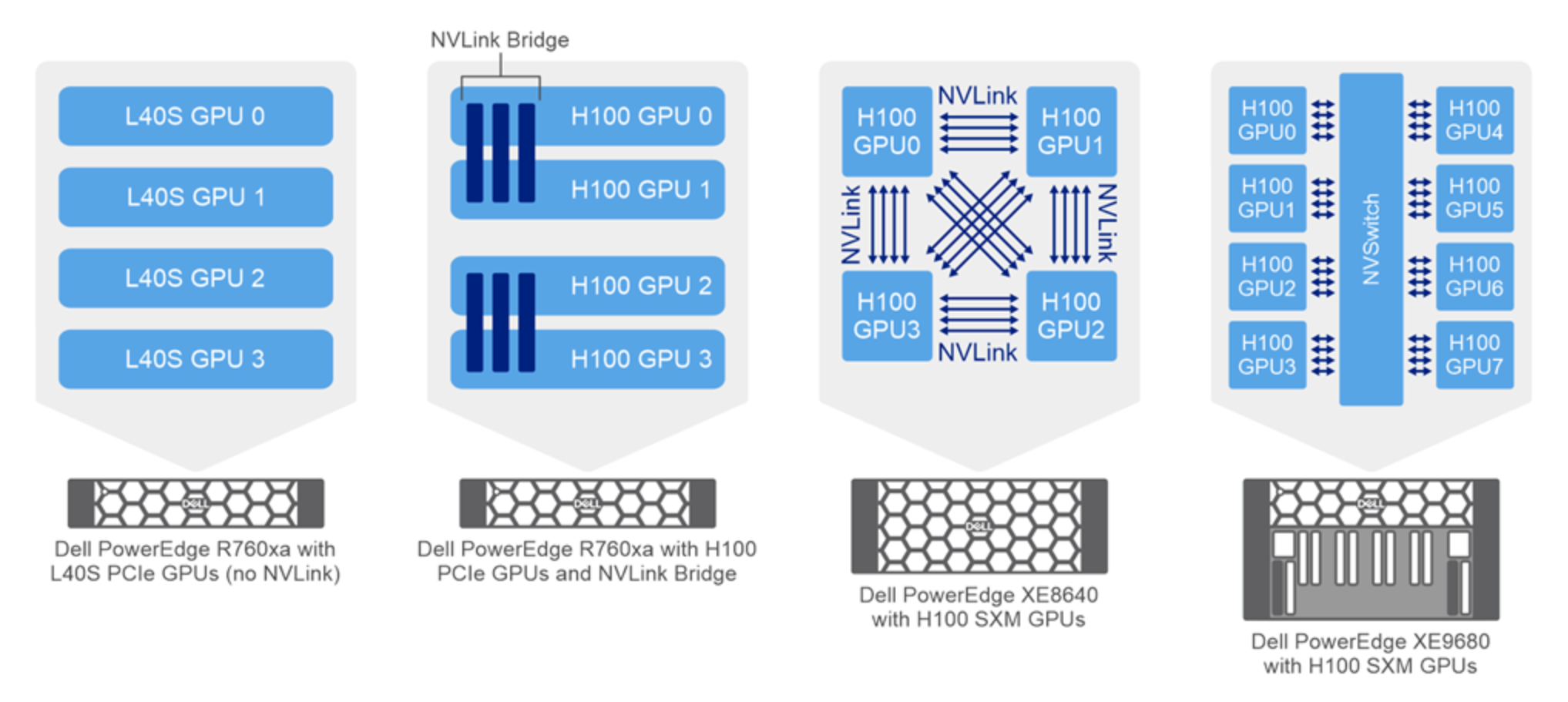
Figure 1. NVIDIA GPU connectivity in PowerEdge servers
PowerEdge servers support several different NVLink options:
- PowerEdge R760xa server with NVIDIA H100 GPUs and NVLink Bridge—NVIDIA NVLink is a high-speed point-to-point (P2P) peer transfer connection. An NVLink bridge is a physical component that facilitates the connection between NVLink-capable GPUs. It acts as an interconnect between the GPUs, allowing them to exchange data at extremely high speeds.
The PowerEdge R760xa server supports four NVIDIA H100 GPUs; NVLink bridge can connect each pair of GPUs. The NVIDIA H100 GPU supports an NVLink bridge connection with a single adjacent NVIDIA H100 GPU. Each of the three attached bridges spans two PCIe slots for a total maximum NVLink Bridge bandwidth of 600 Gbytes per second.
- PowerEdge XE8640 server with NVIDIA H100 SXM GPUs and NVLink—The PowerEdge XE8640 server incorporates four H100 GPUs with NVIDIA SXM5 technology. NVIDIA SXM is a high-bandwidth socket solution for connecting NVIDIA Compute Accelerators to a system.
The NVIDIA SXM form factor enables multiple GPUs to be tightly interconnected in a server, providing high-bandwidth and low-latency communication between the GPUs. NVIDIA's NVLink technology, which allows for faster data transfers compared to traditional PCIe connections, facilitates this direct GPU-to-GPU communication. The NVLink technology provides a bandwidth of 900 GB/s between any two GPUs.
- PowerEdge XE9680 server with NVIDIA H100 GPUs and NVSwitch—The PowerEdge XE9680 server incorporates eight NVIDIA H100 GPUs with NVIDIA SXM5 technology. The server includes NVIDIA NVSwitch technology, which is a high-performance, fully connected, and scalable switch technology. It is designed to enable ultrafast communication between multiple NVIDIA GPUs. NVIDIA NVSwitch facilitates high-bandwidth and low-latency data transfers, making it ideal for large-scale AI and high-performance computing (HPC) applications. The NVSwitch technology provides a bandwidth of 900 GB/s between any two GPUs.
PowerEdge R760xa server with NVIDIA L40S do not support NVLink. The communication between GPUS is through the PCIe bus.