
None
None
-
The Dell Validated Design for Generative AI Inferencing is a reference architecture designed to address the challenges of deploying LLMs in production environments. LLMs have shown tremendous potential in natural language processing tasks but require specialized infrastructure for efficient deployment and inferencing.
This reference architecture serves as a blueprint, offering organizations guidelines and best practices to design and implement scalable, efficient, and reliable AI inference systems specifically tailored for generative AI models. While its primary focus is generative AI inferencing, the architecture can be adapted for discriminative or predictive AI models, as explained further in this section.
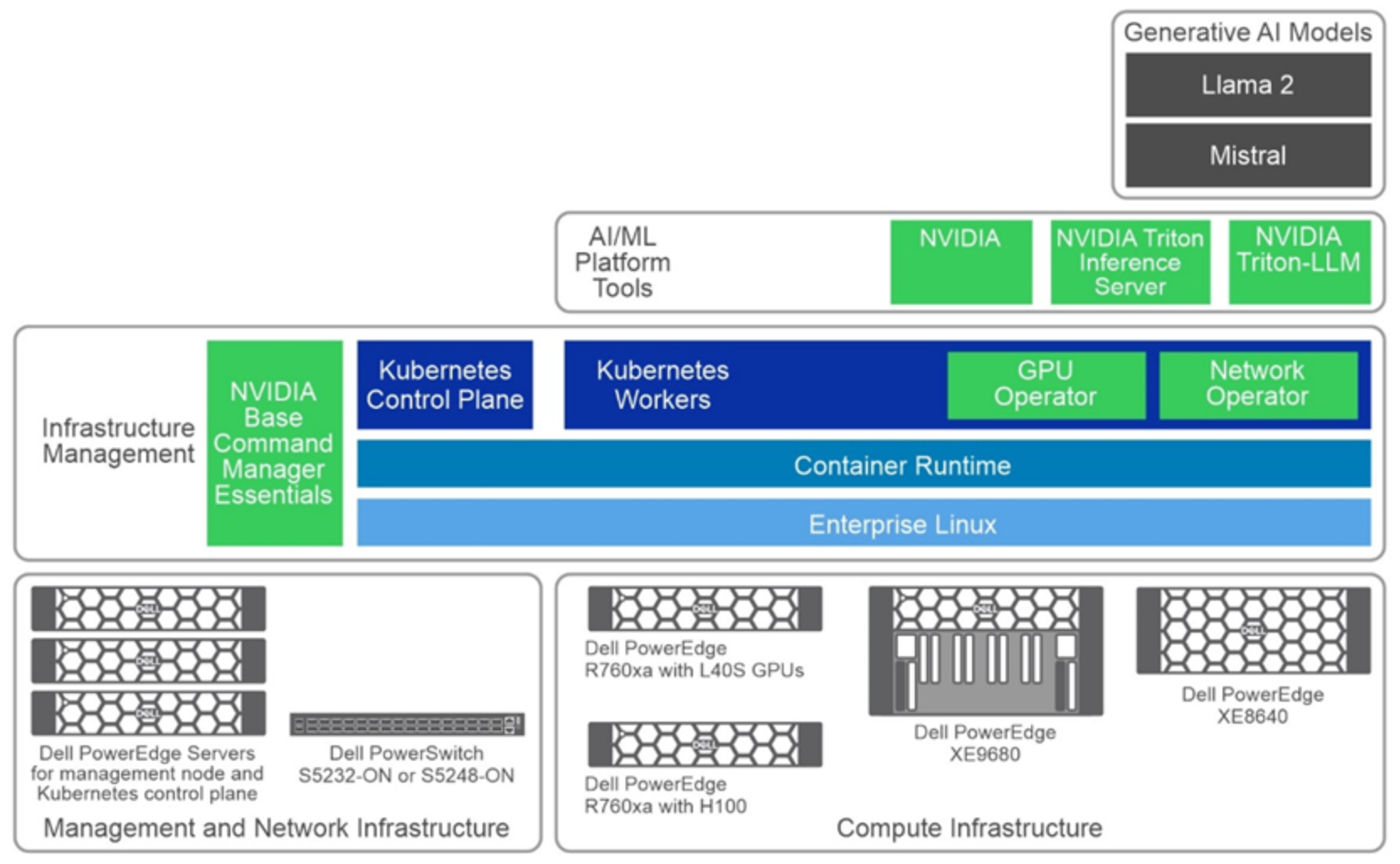
Figure 2. High-level solution architectureThe following sections describe the key components of the reference architecture.
Compute infrastructure
The compute infrastructure is a critical component of the design, responsible for the efficient execution of AI models. Dell Technologies offers a range of acceleration-optimized servers, equipped with NVIDIA GPUs, to handle the intense compute demands of LLMs. The following server models with GPU options were validated as compute resources for deploying LLM models in production:
- PowerEdge XE9680 server equipped with eight NVIDIA H100 SXM GPUs with NVSwitch
- PowerEdge XE8640 server equipped with four NVIDIA H100 SXM GPUs with NVLink
- PowerEdge R760xa servers supporting up to four NVIDIA H100 PCIe GPUs with NVLink Bridge.
- PowerEdge R760xa servers supporting up to four NVIDIA L40S PCIe GPUs
Network infrastructure
Organizations can choose between 25 Gb or 100 Gb networking infrastructure based on their specific requirements. For LLM inferencing tasks using text data, we recommend using existing network infrastructure with 25 Gb Ethernet, which adequately meets text data's bandwidth demands. To future-proof the infrastructure, a 100 Gb Ethernet setup can be used. PowerSwitch S5232F-ON or PowerSwitch S5248F-ON can be used as the network switch. PowerSwitch S5232F-ON supports both 25 Gb and 100 Gb Ethernet, while PowerSwitch S5248F-On is a 25 Gb Ethernet switch. ConnectX-6 Network adapters are used for network connectivity. They are available in both 25 Gb and 100 Gb options.
The scope of the reference architecture only includes AI models in production that can fit in a single PowerEdge server. It does not include models that span multiple nodes and require high-speed interconnect.
Management infrastructure
The management infrastructure ensures the seamless deployment and orchestration of the AI inference system. NVIDIA Base Command Manager Essentials performs bare metal provisioning, cluster deployment, and ongoing management tasks. Deployed on a PowerEdge R660 server that serves as a head node, NVIDIA Base Command Manager Essentials simplifies the administration of the entire cluster.
To enable efficient container orchestration, a Kubernetes cluster is deployed in the compute infrastructure using NVIDIA Base Command Manager Essentials. To ensure high availability and fault tolerance, we recommend that you to install the Kubernetes control plane on three PowerEdge R660 servers. The management node can serve as one of the control plane nodes.
Storage infrastructure
Local storage that is available in PowerEdge servers is used for operating system and container storage. Kubernetes, deployed by NVIDIA Base Command Manager Essentials, deploys the Rancher local path Storage Class that makes local storage available for provisioning pods.
The need for external storage for AI model inference depends on the specific requirements and characteristics of the AI model and the deployment environment. In many cases, external storage is not strictly required for AI model inference, as the models reside in GPU memory. In this design, external storage in not explicitly required as part of the architecture.
However, PowerScale storage can be used as a repository for models, model versioning and management, model ensembles, and for storage and archival of inference data, including capture and retention of prompts and outputs when performing inferencing operations. This practice can be useful for marketing and sales or customer service applications where further analysis of customer interactions may be desirable.
The flexible, robust, and secure storage capabilities of PowerScale offer the scale and speed necessary for operationalizing AI models, providing a foundational component for AI workflow. Its capacity to handle the vast data requirements of AI, combined with its reliability and high performance, cements the crucial role that external storage plays in successfully bringing AI models from conception to application.
Triton Inference Server and TensorRT-LLM
The heart of the AI inference system is the NVIDIA Triton Inference Server with TensorRT-LLM, described earlier, that handles the AI models and processes inference requests. Triton is a powerful inference server software that efficiently serves AI models with low latency and high throughput. Its integration with the compute infrastructure, GPU accelerators, and networking ensures smooth and optimized inferencing operations. TensorRT-LLM is the engine for LLM inference.
AI models
TensorRT-LLM supports the latest LLM models including Llama 2 and Mistral. T Chapter 5 lists the specific models that we validated in this design.
MLOps
Organizations seeking comprehensive model life management can optionally deploy Machine Learning Operations (MLOps) platforms and toolsets, like cnvrg.io, Kubeflow, MLflow, and others.
MLOps integrates machine learning with software engineering for efficient deployment and management of models in real-world applications. In generative AI, MLOps can automate model deployment, ensure continuous integration, monitor performance, optimize resources, handle errors, and ensure security and compliance. It can also manage model versions, detect data drift, and provide model explainability. These practices ensure that generative models operate reliably and efficiently in production, which is critical for interactive tasks like content generation and customer service chatbots.
We have validated the MLOps platform from cnvrg.io as part of this design. cnvrg.io delivers a full-stack MLOps platform that helps simplify continuous training and deployment of AI and ML models. With cnvrg.io, organizations can automate end-to-end ML pipelines at scale and make it easy to place training or inferencing workloads on CPUs and GPUs, based on cost and performance trade-offs. For more information, see the Optimize Machine Learning through MLOPs with Dell Technologies and cnvrg.io design guide.
With all the architectural elements described in this section, organizations can confidently implement high-performance, efficient, and reliable AI inference systems. The architecture's modularity and scalability offer flexibility, making it well suited for various AI workflows, while its primary focus on generative AI inferencing maximizes the potential of advanced LLMs.