
Design Guide—Digital Assistant on Dell APEX Cloud Platform for Red Hat OpenShift with Red Hat OpenShift AI
Logical architecture
Logical architecture
-
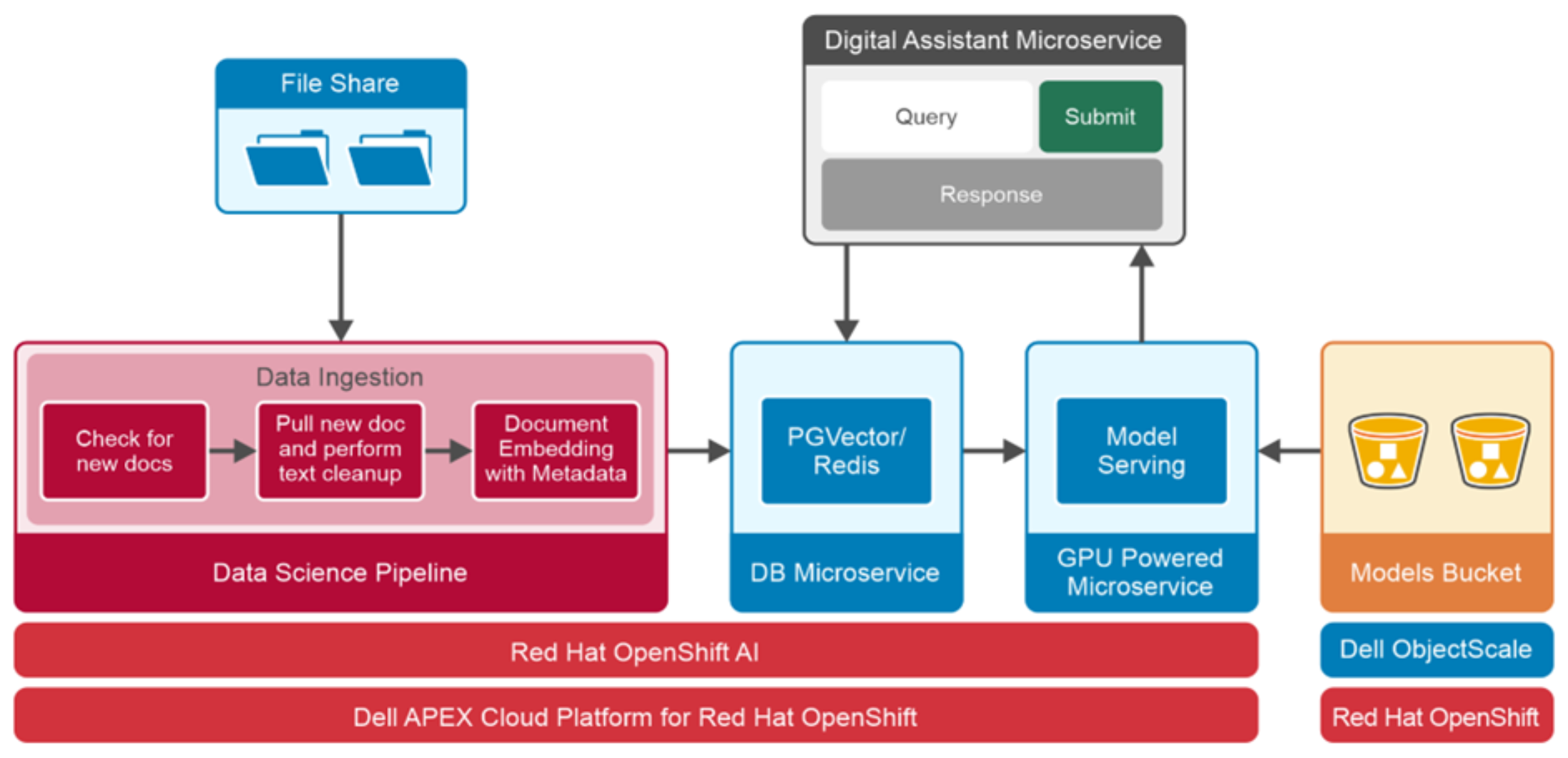 The following figure demonstrates the logical architecture design of the digital assistant deployed on Dell APEX Cloud Platform for Red Hat OpenShift:
The following figure demonstrates the logical architecture design of the digital assistant deployed on Dell APEX Cloud Platform for Red Hat OpenShift:Figure 6. Digital assistant logical architecture
In our validated design, we use Llama 2 model for language processing, LangChain to integrate different tools of the LLM-based application together and to process the PDF files and web pages, Redis or PGVector to store vectors, KServe and vLLM to serve the Llama 2 model, Gradio for user interface and Dell ObjectScale object storage to store language model and other datasets. Solution components are deployed as microservices in the Red Hat OpenShift cluster.
The following list details the roles and responsibilities of each microservice.
- Digital assistant: This microservice runs LangChain, which integrates different components of the LLM-based application together. It also provides the user interface, based on the Gradio UI framework, to interact with the digital assistant.
- Data science pipeline: A data science pipeline is scheduled to run periodically and leveraged to build a data ingestion workflow. Each task within the workflow runs as a separate microservice. This workflow is used to detect recently added or modified documents from file share, extract texts, perform cleanup of data, followed by creating and loading embeddings into PGVector database.
- Vector database: The digital assistant is compatible with both PGVector and Redis as a vector store. In this solution, both PGVector and Redis are deployed as a microservice. Vector store is used to store knowledge base embeddings, and to perform similarity search during context retrieval.
- Model serving: Red Hat OpenShift AI includes a single model serving platform that is based on KServe to serve LLMs. KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. vLLM GPU powered microservice is used as the serving runtime in our solution to serve the Llama 2 model. The Llama 2 model weights and configuration files are copied from the Hugging Face repository and stored in Dell ObjectScale. Storing the models in object storage provides the capability of model versioning and eliminates the need of maintaining multiple copies locally.
- File share: Apache HTTP is deployed as a microservice to host the internal documents, which will be ingested into the vector store through data ingestion pipeline.