
LLM load testing
LLM load testing
-
Overview
To determine the optimal user load for a single instance of the Llama 2 model served with vLLM runtime, we developed a methodology to conduct user load tests and provide relevant performance metrics.
LLM load test is one such open-source tool from Red Hat, which is designed to perform load testing on LLMs running in different runtimes or behind different APIs. See LLM load testing GitHub repository for more information.
Load test configuration
The following is the configuration of our instance used for validation.
Number of replicas: 1
CPU: 6 vCPU
Mem: 12 GB
GPU: 1 x NVIDIA L40s
Below are the parameters and its values from config.yaml (LLM load test) used during our validation with variation in concurrency to simulate different sets of user loads:
output:
format: "json"
dir: "./output/"
file: "output.json"
warmup: False
warmup_options:
requests: 10
timeout_sec: 60
storage: # TODO
type: local
dataset:
file: "datasets/openorca_large_subset_011.jsonl"
max_queries: 1000
min_input_tokens: 0
max_input_tokens: 1024
max_output_tokens: 256
max_sequence_tokens: 1024
load_options:
type: constant #Future options: loadgen, stair-step
concurrency: 15
duration: 600# In seconds. Maybe in future support "100s" "10m", etc...
plugin: "openai_plugin"
plugin_options:
streaming: True
model_name: "/mnt/models/"
host: "https://newllama13b.apps.<your namespace domain> "
endpoint: "/v1/chat/completions"
extra_metadata:
replicas: 1
Findings
Based on our test result, we have observed that in every run workload gets offloaded to the GPU, so there is minimal CPU and memory utilization on the instance. GPU overall utilization remains between 92 to 95 percent, and GPU memory utilization remains between 95 to 100 percent.
The graphs below highlight the matrices values for different user load.
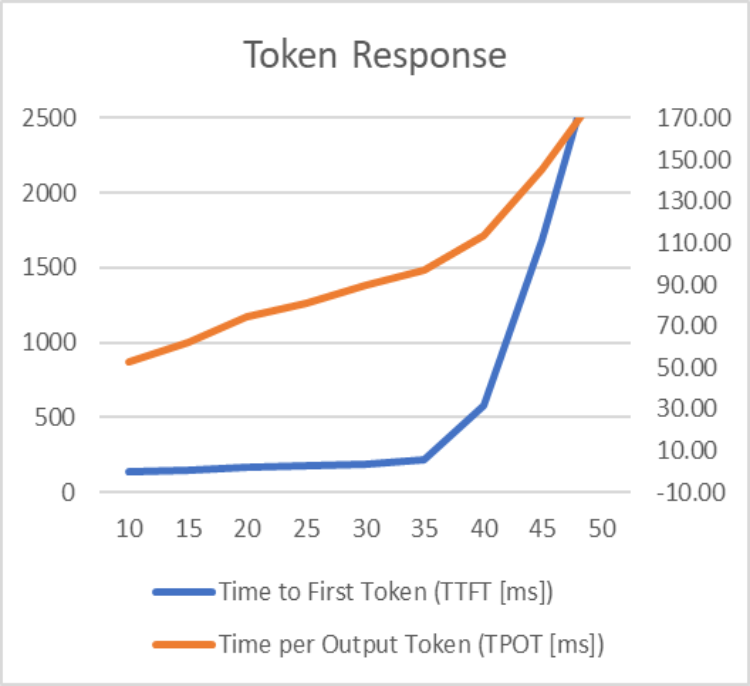
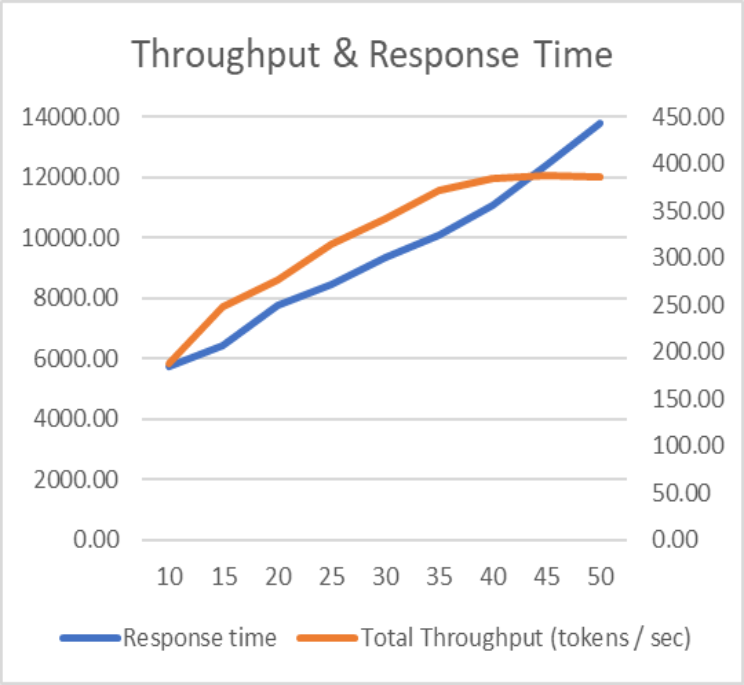
Matrices:
- Time to First Token (TTFT): The time taken for the first token to be generated and streamed to each user.
- Time per Output Token (TPOT): Average time to generate an output token for each user.
- Response Time: An LLM's response time provides a measure of how much time taken to generate a complete response from the time the query is submitted.
- Total Throughput: An LLM's throughput provides a measure of how many requests it can process or how much output it can produce in a given time span.
As per the graph, 35 concurrent users are the optimal load on a single replica of Llama 2 model served with vLLM serving runtime. Once the user load increases beyond 35, the token response time increases exponentially, and throughput remains constant.
In our validation we have tested a single replica of a model serving with a single GPU. Our cluster is equipped with two GPUs per node; based on the requirement, we could deploy more than single replica to handle an even larger number of users.