
Digital assistant design
Digital assistant design
-
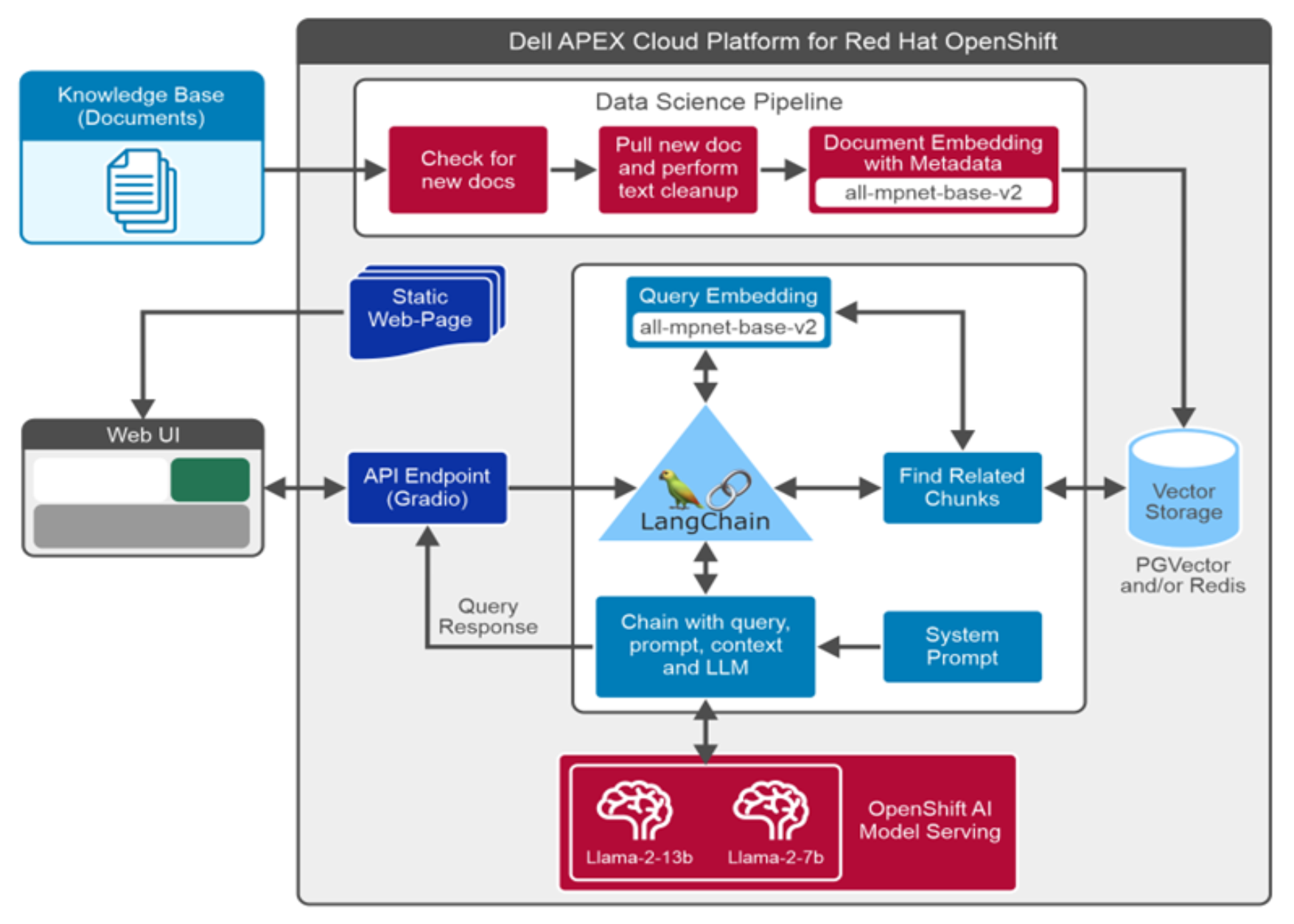 RAG is an AI framework that allows LLMs to access additional domain-specific data and generate better and more accurate answers, without having to be retrained. The following figure describes the RAG based digital assistant architecture design.
RAG is an AI framework that allows LLMs to access additional domain-specific data and generate better and more accurate answers, without having to be retrained. The following figure describes the RAG based digital assistant architecture design.Figure 7. Digital assistant design
The following list outlines digital assistant components and workflow.
- Data Ingestion: The data science pipeline is leveraged to ingest data, which is created and scheduled to run at specific intervals. This pipeline discovers any new files, extracts text, performs data cleanup, stores metadata, create manageable text chunks, create embeddings for the text chunks and store text, metadata, and their embeddings into the PGVector or Redis vector database collection.
- User Interface: Gradio provides a simple and intuitive user interface to interact with the digital assistant. LangChain integrates the Gradio user interface with other components such as LLM and vector store to work together as a digital assistant.
This digital assistant solution is provided with advanced UI features which include choice of different LLMs, vector stores, and catalogs. Digital Assistant UI also provides additional options to users such as maximum sequence length, temperature control, retrieval score threshold, and maximum number of documents retrieved. These additional options allow users to have additional controls on the response from the digital assistant.
- Query processing: When users submit a query using the UI, the query will be first converted to vector embedding. Embedding is a process of converting text chunks to a fixed-sized vector. Semantic search is then performed for the query embedding against the knowledge base vector embeddings stored in the PGVector database. Results from PGVector are ranked and sent to the Llama 2 model along with predefined system prompts, the Llama model generates the response based on retrieved context from PGVector and its pretrained capabilities.