Splunk services like Streaming, Visualization, Smart Ingest, and Deep Learning Tools (DLTK) shape predictive maintenance outcomes. The first three services are packaged as Splunk Core Enterprise (SCE) software. DLTK is necessary for predictive maintenance. It includes deep-learning development tools and other machine learning capabilities. Containerized predictive maintenance entails deploying Splunk services on a cloud native environment.
Robin CNP prerequisites
Requirements for deploying Robin Cloud Native Platform (Robin CNP) in a production environment include:
At least one administration node for miscellaneous services such as HAProxy
Three control plane nodes across all production deployment sizes
One routable network
One management network
At least one cluster data network
At least two Dell PowerEdgeworker nodes with x86_64 CPU architecture
SSDs in the worker nodes sized per the use case requirement
Container design
Containerized Splunk is deployed on the Dell Validated Design for Analytics — Data Lakehouse which is based on the Robin Cloud Native Platform (Robin CNP). The approach that this design takes is to:
Install containerized Splunk into the Dell Validated Design for Analytics — Data Lakehouse with bundled Splunk Core Enterprise (SCE) services.
Deploy peripheral services like Deep Learning Toolkit (DLTK) on which predictive maintenance intellectual property is developed.
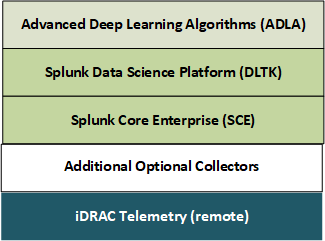
Predictive analytics intellectual property is described elsewhere. It includes processing live telemetry from iDRACs attached to servers, for Anomaly Detection (AD) and Forecasting to capture the substrate fault map. You can leverage this fault map to write custom schedulers that shape your substrate needs. Software stack delineation shows the software stack delineation. Image sizes are approximately:
Advanced Deep Learning Algorithms (ADLA)—1 GB
DLTK—10 GB
SCE—1 GB
Figure 8. Software stack delineation
Splunk Core Enterprise
Splunk Core Enterprise (SCE) is a collection of atomic indexers, search heads, and forwarders. Indexers index data, transform raw data into events, and attach them to the index. Search heads serve as the interface for Deep Learning Toolkit (DLTK) applications to use indexed data. Forwarders collect, forward, and load-balance to indexing tiers. External load balancers like HAProxy redirect the flows to multiple forwarders.
The number of indexers is calculated from the use case data rate and the predictive analytics window size. See Splunk Storage Sizing. The indexing caps in the Splunk documentation guide the number of indexers. The number of required search heads is automatically calculated based on Intel benchmarks that show nearly linear growth with a five (indexers)-to-three search heads base. See the Intel document, Intel Select Solutions: Containerized Splunk. The number of forwarders feeding an index cluster is based on the real-time needs of both DLTK and custom scheduling.
Note: Forwarder segmentation is outside the scope of this design.
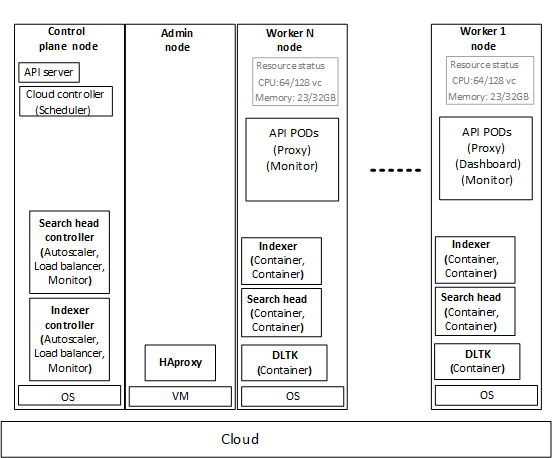
The cloud controller managers reside on the control plane node, and the pods are distributed among the worker nodes.
Note: Calico-based pod networking is not shown.
Splunk DLTK is a collection of open-source tools such as Jupyter, MLflow, Spark, and so on, that are necessary to develop models. DLTK includes Machine Learning Toolkit (MLTK).
Figure 9. Splunk container architecture
The figure above shows an example of how worker nodes resource utilization can be viewed, and is not a snapshot:
64 out of 128 vCores used
23 out of 32 GB RAM used
Container network framework
The Container Network Framework (CNF) holds the resilient and scalable Predictive Maintenance for IT Operations solution together. The Dell Validated Design for Analytics — Data Lakehouse is based on the Robin Cloud Native Platform (Robin CNP). Robin CNP is based on open-source Kubernetes. See the Robin CNP documentation for more details.
Robin CNP adds dynamic, software-defined storage provisioning using:
Robin Cloud Native Storage (Robin CNS)
Authentication capabilities
Industry-standard operators and automation utilities
A standard, medium-size deployment includes:
One administration node
Three Kubernetes fault-tolerant control plane nodes
Two to seven worker nodes to host the replicated application container components
Splunk services except Deep Learning Toolkit (DLTK) are bundled in the Dell Validated Design for Analytics — Data Lakehouse. DLTK is deployed separately because at the time of this publication, it is still a community-supported service.
Container design summary
Dell Technologies made container design choices with the following concepts in mind:
Three control plane nodes are necessary in order to support high availability (HA). This practice is standard in the cloud-native world.
A baseline of two, to a maximum of seven, worker nodes saturate the proposed network architecture. For rare, larger deployments you can include more worker nodes if you add spine switches.
For warm storage, Dell Technologies recommends a five-node ECS EX500 platform. You can scale this platform by increasing the number of drives, or by opting for higher density drives.
Hot SSD storage requirements are calculated on a per-server basis. The exact number of servers in the substrate can vary, but the platform supports hot plug-ins for upscaling.
The cluster includes one administration node to support housekeeping tasks such as HAproxy, DNS management, and so on. Production deployments can optionally include a standby administration node.