
Dell EMC SRDF/Metro
Dell EMC SRDF/Metro
-
SRDF/Metro simplifies Oracle Extended RAC deployment
SRDF/Metro is based on synchronous storage replication. It does not compete with the database for I/Os and CPU resources. It can leverage optional “cross-links” in the deployment. Cross-links allow each cluster node to have visibility to both storage systems. If a node loses connectivity to its nearest storage system, it can continue processing transactions using the remote storage system. To keep the configuration simple, cross-links are not required and the nodes only need visibility to the closest storage system.
With SRDF/Metro, both source (R1) and target (R2) devices have full read/write data access while synchronized. To accomplish this, the storage replicates writes in both directions and services reads from the storage closest to the requesting node.
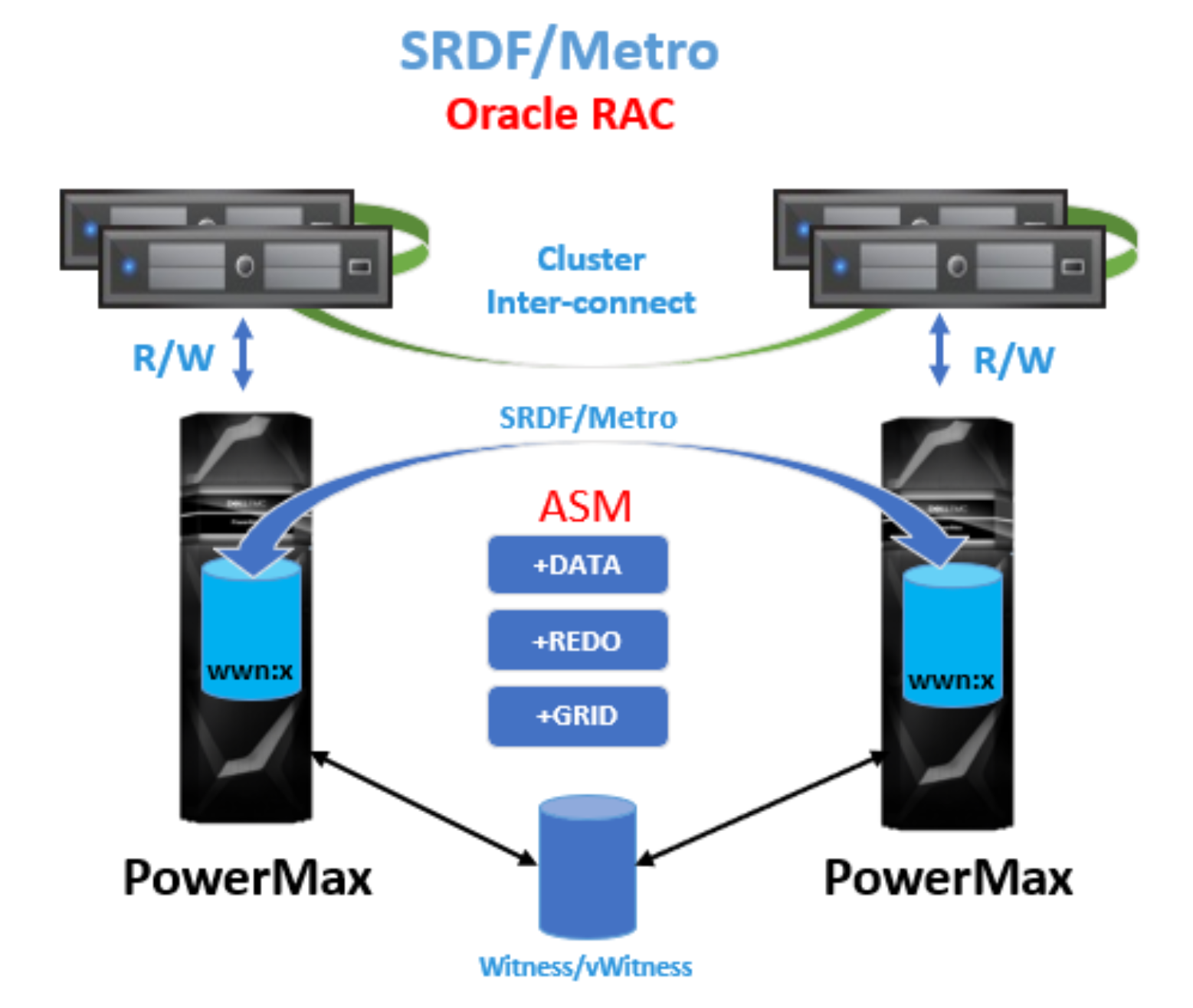
Figure 1. Dell EMC SRDF/Metro with Oracle Extended RAC
SRDF/Metro achieves this true active/active storage replication in the following way. Each PowerMax storage device has two SCSI personalities — internal (their initial WWN and geometry), and external (which usually matches the internal, but can be ‘spoofed’ to match another device). When SRDF/Metro paired devices are synchronized, the R2 devices’ external SCSI personality is set to match the R1 devices’ SCSI personality. As a result, to the database server, each synchronized R1 and R2 device simulates multiple paths to a single local storage device.
Since all cluster nodes see the replicated devices as paths to what they consider local shared storage, there is no need for an “agent” or mirroring software on the database servers. The multipathing software manages these paths just like any other path. If the optional cross-links are used, Dell EMC PowerPath software can set them to ‘auto-standby’ so they are used only if all the main paths to the nearest storage system have failed. The server I/Os will not be doubled and I/O latencies will remain minimal as I/Os are directed to the nearest storage system while it is available.
The overall management of the solution is simplified because we only need to monitor the replication health across the two storage systems. There is no need for agents on every database server. Also, by making the R1 and R2 devices seem identical to the database servers, the Oracle Grid Infrastructure (GI) software is not even aware that the storage is extended or stretched. As a result, during GI setup we do not need to worry where quorum files are located.
Another challenge of any cluster is to prevent “split-brain” and to determine the surviving site in the case of a disaster. When two or more nodes in a cluster can’t communicate with their peers, and yet continue to write to the storage, they can cause data corruption. This situation is called a “split-brain”. SRDF/Metro takes a deterministic approach to protect against a “split-brain” and determines the surviving site based on two complimentary methods: Bias rules, and Witness rules. These methods are discussed in more detail in the section SRDF/Metro protection from a “split-brain” situation.
The interaction between SRDF/Metro and Oracle Grid Infrastructure
If there is an unexpected interruption in replication, both the R1 and R2 devices hold all I/Os temporarily while SRDF/Metro determines which side of the replication is allowed to resume I/Os. Since we only have the two storage systems to deal with, this process takes only a few seconds.
SRDF/Metro doesn’t require an integration with Oracle Grid Infrastructure. By simply stopping I/Os on one storage system, and allowing them to resume on the other, Oracle RAC will reconfigure on its own accordingly — nodes that can perform I/Os to the quorum files remain up and running, and nodes that can not will be removed from the cluster. It is essential that SRDF/Metro resumes I/Os faster than the Oracle RAC disk timeout interval to avoid a race condition. If Oracle RAC determines that its quorum files can not be reached anywhere across the cluster before the storage resumes I/Os, then all the cluster nodes will go down. Since SRDF/Metro resumes I/Os in a matter of seconds after a replication failure and Oracle RAC disk timeout interval value is default to 200 seconds, this race condition does not occur.
As a safety measure to prevent data corruption, the SRDF/Metro devices on the side that resumes I/Os become (or remain) R1 devices, take a RW state (read/write state, making them available for database server read and write I/O operations), and maintain the same external SCSI personality they had during active/active replication. The SRDF/Metro devices on the side that stopped servicing I/Os become (or remain) R2 devices, take a WD state (write disabled state), and do not maintain the same external SCSI personality as they did during replication.
ASM disk group redundancy choice when using SRDF/Metro
In general, it is recommended to use ASM external redundancy (no ASM mirroring) for ASM disk groups that use PowerMax as their storage. With external redundancy, PowerMax provides storage protection and resiliency for the ASM disks, and there is no need to use ASM mirroring in addition.
The only exception is that when using Oracle RAC, it is recommended to use ASM normal redundancy (two failure groups, or ASM mirroring) for the Grid Infrastructure ASM disk group alone. This ASM disk group is very small as it doesn’t contain any user data. Therefore, whether using external redundancy (no ASM mirrors), or normal redundancy (two ASM mirrors) for the Grid Infrastructure ASM disk group, the overall capacity difference is negligeable.
However, when using external redundancy for the Grid Infrastructure ASM disk group, Oracle RAC creates a single quorum file for the cluster, and when using normal redundancy, Oracle RAC creates three quorum files. Therefore, the reason for this exception is simply so that Oracle RAC will have three quorum files instead of one.
This exception is meant for systems with high IOPS and many cluster nodes. In that case, if Oracle RAC performs reconfiguration, three quorum files are easier to reach by all the nodes than just one.
However, for small Oracle RAC configurations, such as two-node RAC, it is fine to use external redundancy for the Grid Infrastructure ASM disk group, and therefore, use a single quorum file for the cluster. In such Oracle RAC configurations, a single quorum file can be easily reached from both cluster nodes and there is no need for the exception. As a result, all ASM disk groups, including Grid Infrastructure, can use external redundancy.
SRDF/Metro performance benefits in Oracle Extended RAC deployment
Performance is one of the main concerns in maintaining consistent data across distance. SRDF/Metro helps to maintain high performance in a few ways:
- It utilizes the closest storage system to the Oracle cluster node for all I/Os. Even if cross-links are used, they are in passive (standby) mode, as long as the paths to the local storage system are working.
- It optimizes database read I/O latencies, as PowerMax has a large capacity cache. When the required data is in the PowerMax cache, reads are satisfied directly from the cache. Otherwise, the data is fetched from the local storage NVMe flash media, utilizing features such as Optimized Read Miss to make the transfer even faster.
- It optimizes database write I/O latencies, as writes are sent to the local storage system’s cache. Since PowerMax cache is considered persistent, there is no need to wait for writes to be flushed to the NVMe storage. Instead, the writes are immediately replicated synchronously from the local storage system cache to the remote storage system cache and acknowledged to the database server.
As a result, SRDF/Metro is well-suited for Oracle Extended RAC deployments. It is quickly deployed and easy to use.
SRDF/Metro protection from a “split-brain” situation
A “split-brain” happens when two or more nodes in a cluster can’t communicate, and yet, believe that they are the only survivor and should keep writing to storage, essentially corrupting the data. SRDF/Metro takes a deterministic approach to not allow a “split-brain” to occur when the two storage systems can’t communicate. Two complimentary methods are used to protect against a “split-brain”: SRDF/Metro Bias rules and SRDF/Metro Witness rules.
SRDF/Metro Bias rules
Under Bias rules, one side of the SRDF/Metro paired devices (where the R1 devices are) has the ‘Bias’, and therefore it is pre-determined to “win”, or resume I/Os, if replication stopped unexpectedly. The other side (where the R2 devices are), is pre-determined to immediately stop servicing I/Os.
SRDF/Metro synchronized device-pairs protected by Bias rules alone show a state of ‘ActiveBias’.
While using Bias rules is an incontestible method for preventing a “split-brain” (only one side can ever resume I/Os), it is not flexible, as a “disaster” may then occur where the Bias side is, requiring manual intervention to make the non-Biased side available. To protect against this situation, SRDF/Metro uses Witness rules in addition to Bias rules.
Note: Starting with PowerMaxOS 5978 Q3 2019 release, SRDF/Metro regularly takes additional factors into account to determine the Bias side, such as which of the storage systems has an active SRDF/A protection, available storage directors, etc. That means that the Bias may change dynamically during SRDF/Metro replication to reflect these factors.
SRDF/Metro Witness rules
Under Witness rules an added component called a Witness, serves as a real-time arbitrator when an active/active SRDF group unexpectedly stop replicating. SRDF/Metro, with the help of the Witness, quickly determines in real-time which storage system is deemed best to continue servicing I/Os for that SRDF group, based on the situation and failure conditions.
These factors are important for working with Witness:
- A Bias is still automatically set for every SRDF group in an SRDF/Metro configuration, even if a Witness is used. That is in case the Witness is removed or can’t be reached. However, if a Witness is configured, it overrides the Bias.
- A Witness can be array-based (“physical” Witness). In that situation, another VMAX or PowerMax storage system’s SRDF links are used just for the purpose of health communication (no data is sent across them). A Witness can also be Virtual (vWitness). In that situation, one or more VMware virtual appliances (vApps) communicate with SRDF/Metro over IP about the cluster’s health. The Solutions Enabler or Unisphere for VMAX or PowerMax vApps include a vWitness component.
- You should configure multiple Witnesses, but only one Witness can be in effect at a time. SRDF/Metro will only start using a Witness when both storage systems can reach it and agree to use it. If both physical and virtual Witnesses are configured, the physical Witness takes precedence.
- As SRDF/Metro replication granularity is at an SRDF group level (a collection of paired R1 / R2 devices), also the choice of a Witness is done at that granularity — per SRDF group. Therefore, different SRDF groups in active/active state may use different Witnesses, or a single Witness may serve multiple SRDF groups.
- As mentioned earlier, if a Witness is not configured, or communication with the last Witness is lost while SRDF/Metro is already in active/active state, SRDF/Metro reverts to using Bias rules.
SRDF/Metro synchronized device-pairs protected by Witness rules show a state of “ActiveActive”.