
Test Case 1: Moving a shared disk resource to another node
Test Case 1: Moving a shared disk resource to another node
-
In this scenario we will demonstrate how an application will continue to run as a shared disk resource (in CSV or non CSV case) is moved between cluster nodes. Because SRDF/Metro provides high availability for shared disk resources, the application will continue to function without any disruption. There might be some minor performance degradation as the Windows failover cluster moves the chosen disk resource to another node, but the application will continue to function normally. Note that in this test, the SQL Server role continues to run on the same node throughout the test. Therefore, the application I/Os are serviced by the R1 system throughout the test. Only disk resources used by Windows Server failover feature a change in ownership.
Step 1: SQL Server running normally on all shared resources
In this test, SQL Server is running on all CSVs that are distributed on both available Windows failover cluster node as far as the ownership is concerned. Even though disk resources are owned by different cluster nodes, host I/O will be performed on the local node where SQL Server role is running. The PowerMax storage system on the R1 side of SRDF/Metro will service all the I/Os, while the remote side of SRDF/Metro continuously remains synced with the R1 side. The application is started and the number of transactions per minute (TPM) is captured. In this step, SQL Server reported a TPM of 945K.
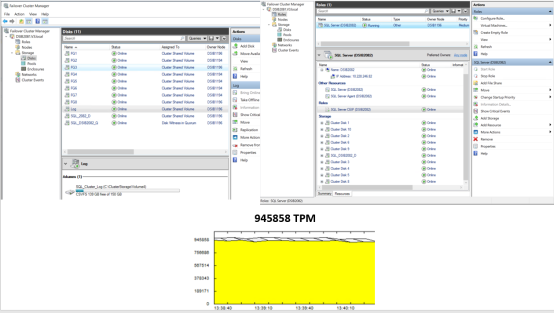
Figure 32. SQL Server running normally on all shared resources
Step 2: Some of the shared disks are moved to another cluster node
In this step of the test, some of the SQL Server disk resources are moved to another node. To move resources, choose Move Available Storage (1) from the Action tab on the failover cluster node and select the node to which the storage should be moved. SQL Server role continues to run on the original node. The PowerMax system on the R1 side will continue to service all the I/Os. There might be some brief degradation of performance from the application’s standpoint when the disk resources are moved, but the application will continue to run.
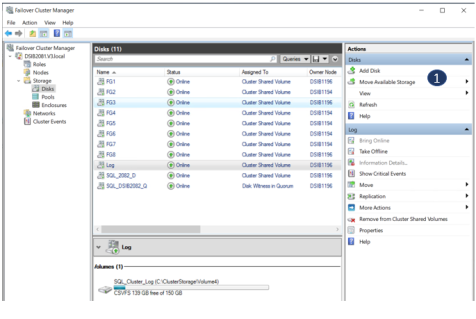
Figure 33. Move storage from one cluster node to another
Step 3: SQL Server continues to run even after disk resources are moved
The application continues to run while the disk resources are moved. TPM information is continuously captured. As shown in the figure below, other than brief degradation during the disk resource movement from one node to another, performance is quickly restored once that move completes. SQL Server reported a consistent performance of 913K TPM after the resources came back up on the new node. The slightly lower TPM is due to the node ownership change resulting in additional cluster coordination work by the Windows Server failover cluster.
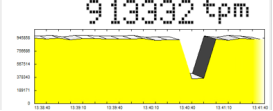
Figure 34. Application performance before, during, and after the disk resources moved