
Single server performance
Single server performance
-
The performance metrics for three of the benchmarks on a single server are shown in the following table:
Table 6. Single node benchmark results
HPL (TFLOPs)
HPCG (GFLOPs)
STREAM (MB/s) Triad Avg
8.15
117.90
626478.50
The OSU benchmarks consist of a suite of tests conducted on two servers connected by a single NVIDIA Mellanox QM9790 NDR Edge Switch. The Point-to-Point benchmarks include latency (osu latency), bandwidth tests (both unidirectional and bi-directional), and MPI (multiple bandwidth or message rates).
In this two-socket system, one CPU has direct access to the network interface card (NIC) through a local PCI slot, while the other CPU accesses the NIC remotely by the first CPU, which is directly connected to the NIC.
Figure 3 represents local and remote latencies with various message sizes ranges from 1 B to 4 MB. Similarly, unidirectional and bi-directional bandwidths are illustrated in Figures 4 and 5.
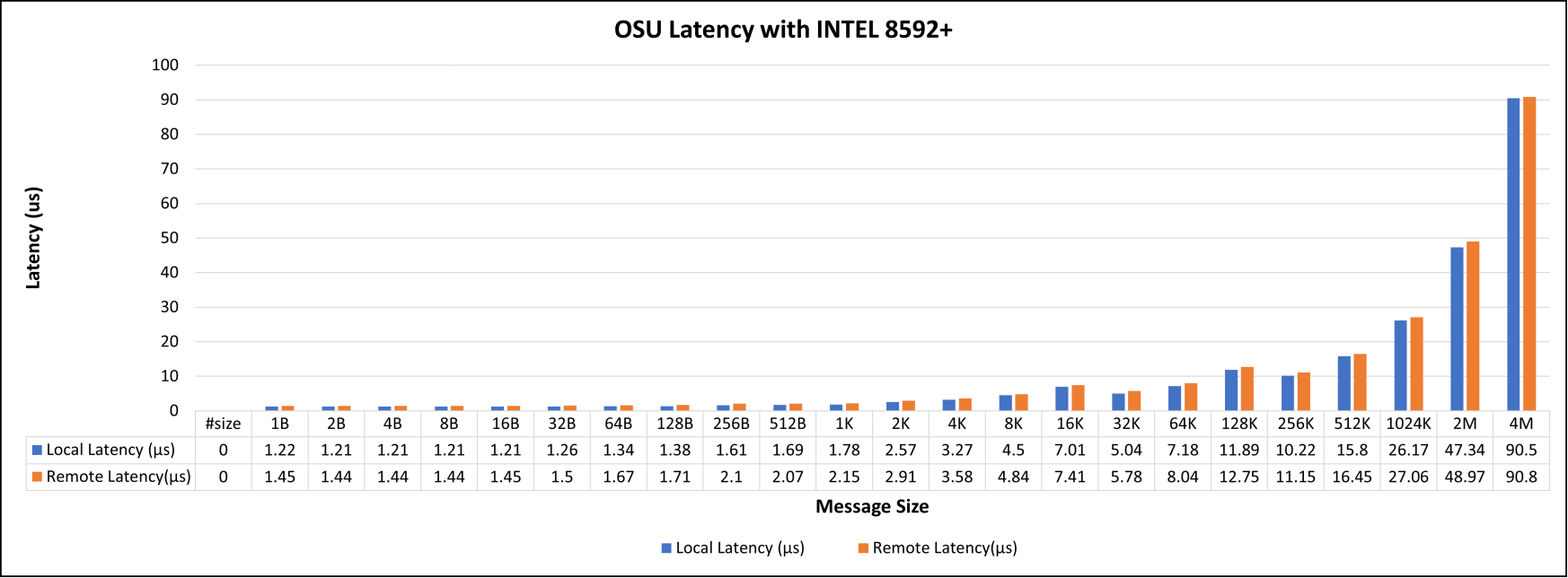
Figure 3. OSU local and remote latency tests with Intel 8592+
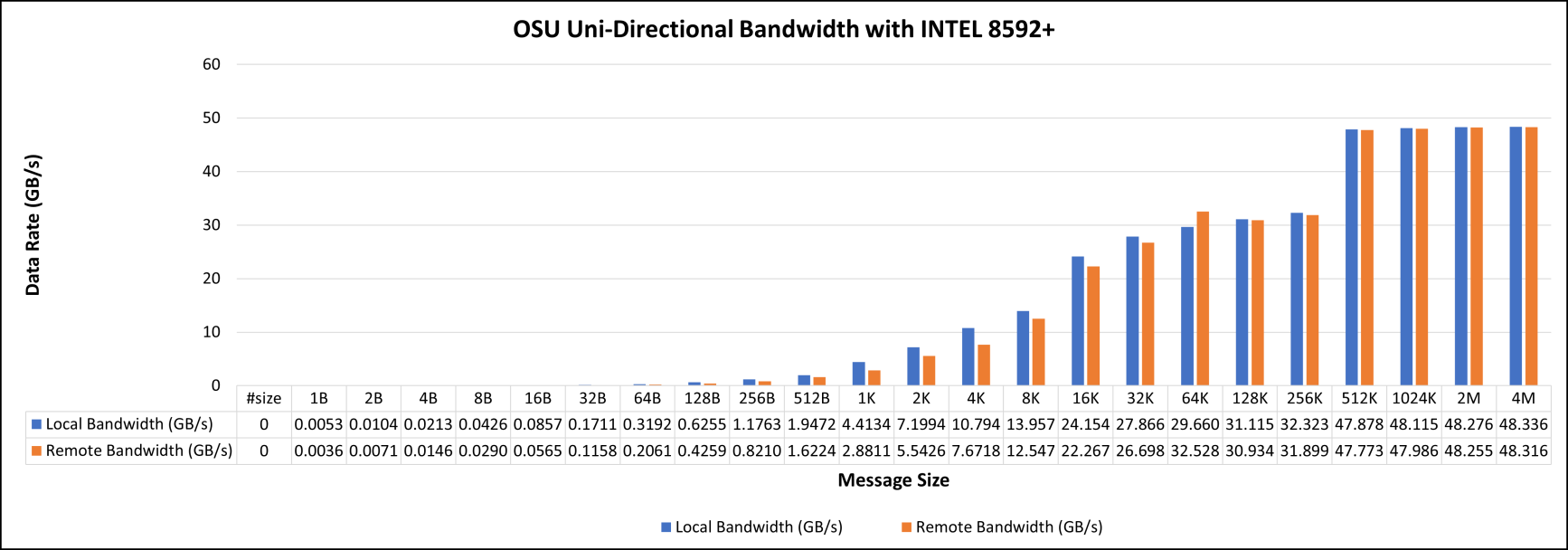
Figure 4. OSU Uni-Directional Bandwidth with Intel 8592+
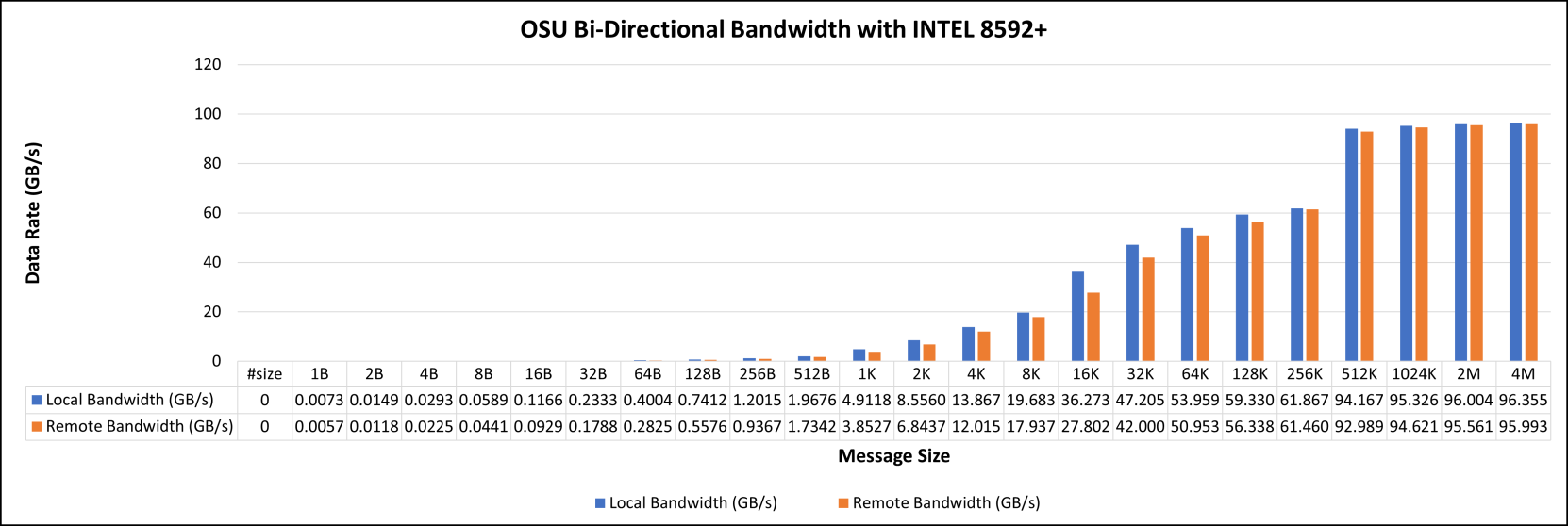
Figure 5. OSU bi-directional bandwidth with Intel 8592+
Message bandwidth and rate with various message sizes are illustrated in Figure 6.
Tag Matching (TM) technology causes a notable behavior change at the message size of 1 K. TM is the process of finding the corresponding buffer from the matching list to a given message. TM Offload (TMO) pushes the head of the matching list to the NIC to perform TM on it. The threshold for using TMO is set to 1 K in the tested compute nodes. The smaller than 1 K buffers will not be posted to the NIC, and hence SW will complete the TM. Therefore, two groups of messages go through different message processes and show different characteristics of bandwidth.
Hardware TM offload is disabled by default in the adapter, which you can enable by setting UCX_RC_TM_ENABLE=y.
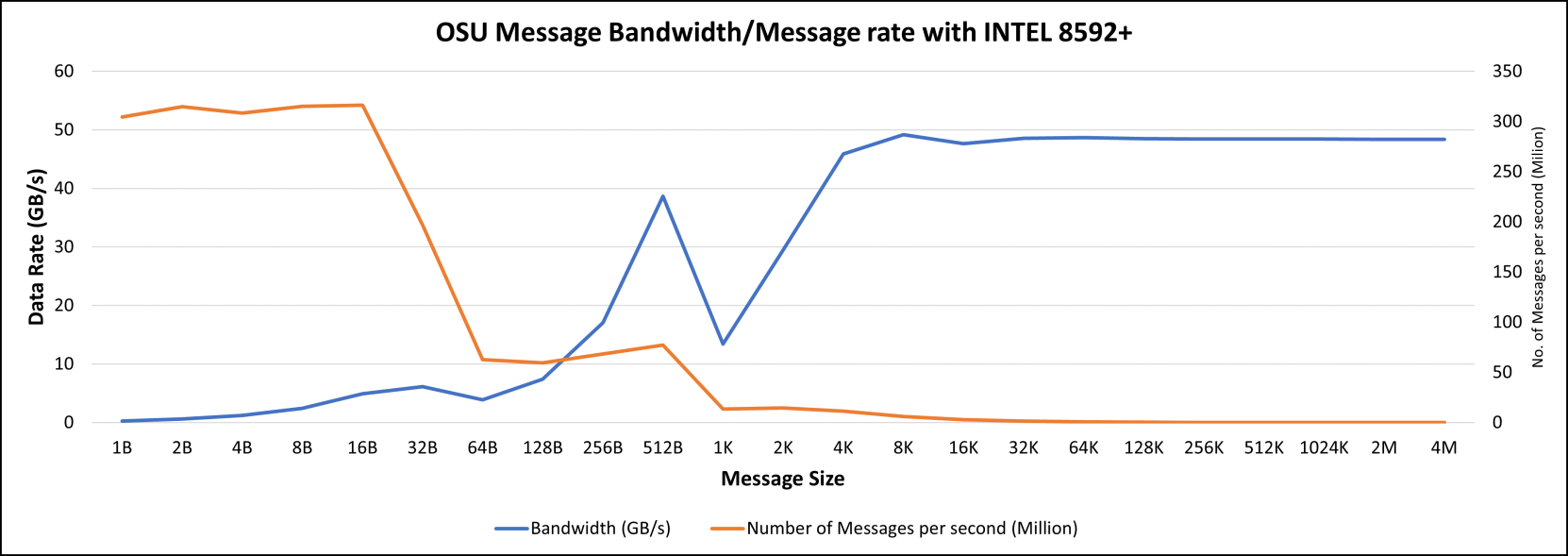
Figure 6. OSU message bandwidth and message rate with Intel 8592+