
HPL-MxP (also known as HPL-AI) benchmark demonstrates the convergence of HPC and AI workloads by solving a system of linear equations using innovative mixed-precision algorithms. See HPL-MxP for more information.
HPL-MxP performance improves with larger matrix sizes, optimizing the use of computational resources. In most cases, the benchmark is configured to maximize GPU memory utilization by adjusting the global matrix size. Fine-tuning these parameters depends on the specific hardware setup. For instance, on NVIDIA GPUs, adjusting matrix dimensions, block size, and process grid dimensions is crucial to achieving optimal performance tailored to the system's architecture.
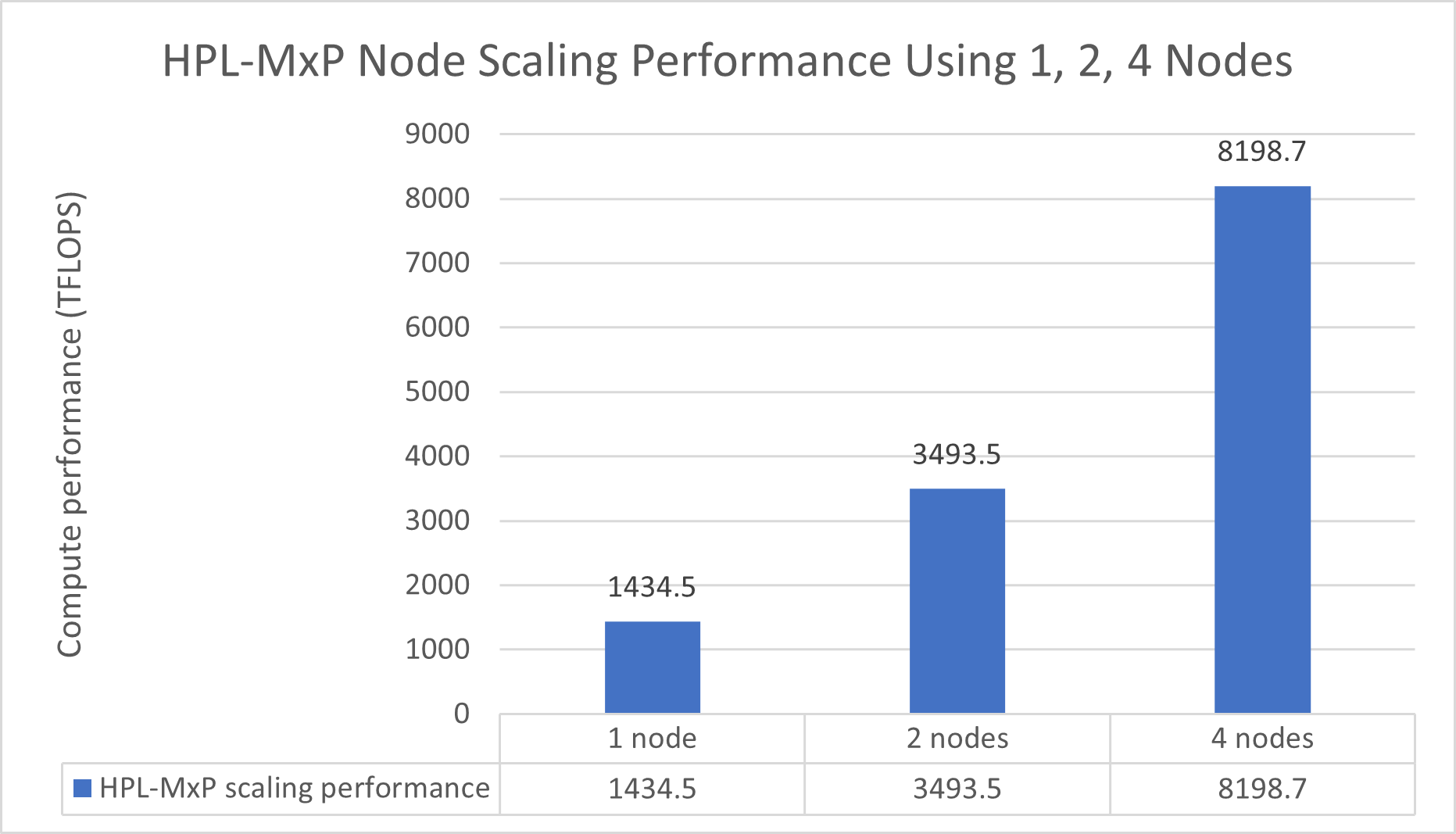
| Benchmark (TFLOPS) | One node | Two nodes | Four nodes |
| NVIDIA HPL | 368 | 752 | 1489 |
| NVIDIA HPL-MxP | 1435 | 3494 | 8199 |
| SPEEDUP: HPL-MxP/HPL | 3.90 | 4.65 | 5.51 |
The HPL-MxP benchmark integrates HPC and AI workloads by solving systems of linear equations using innovative mixed-precision algorithms. This benchmark provides a more realistic representation of mixed-precision tasks for modern deep learning and large language models. Table 4 illustrates the speedup that is achieved when transitioning from a pure 64-bit (FP64) workload to the HPL-MxP mixed-precision workload.