
PowerEdge R750 Sequential IOR Performance N clients to 1 file
PowerEdge R750 Sequential IOR Performance N clients to 1 file
-
Sequential N clients to a single shared file performance was measured with IOR version 3.3.0, with OpenMPI 4.1.4rc1 to run the benchmark over the 16 compute nodes. The tests that we ran varied from single thread up to 512 threads because there are not enough cores for 1024 threads (the 16 clients have a total of 16 x 2 x 20 = 640 cores) and oversubscription overhead slightly affected results at 1024 threads.
We minimized caching effects by setting the GPFS page pool tunable to 32 GiB on the clients and 96 GiB on the servers, and using a total data size of 8 TiB, twice the RAM size from servers and clients combined. We used a transfer size of 16 MiB for this performance characterization. For a complete explanation, see Sequential IOzone performance N clients to N files.
The following commands were used to run the benchmark, where the Threads variable is the number of threads used (1 to 512 incremented in powers of 2), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes. The FileSize variable has the result of 8192 (GiB)/Threads to divide the total data size evenly among all threads used.
mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –mca btl_openib_allow_ib 1 –mca pml ^ucx –oversubscribe –prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -I 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -w -s 1 -t 16m -b ${FileSize}G
mpirun–-allow-run-as-root -np $Threads–-hostfile my_hosts.$Threads–-mca btl_openib_allow_ib 1–-mca pml ^ucx–-oversubscribe–-prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -r -s 1 -t 16m -b ${FileSize}G
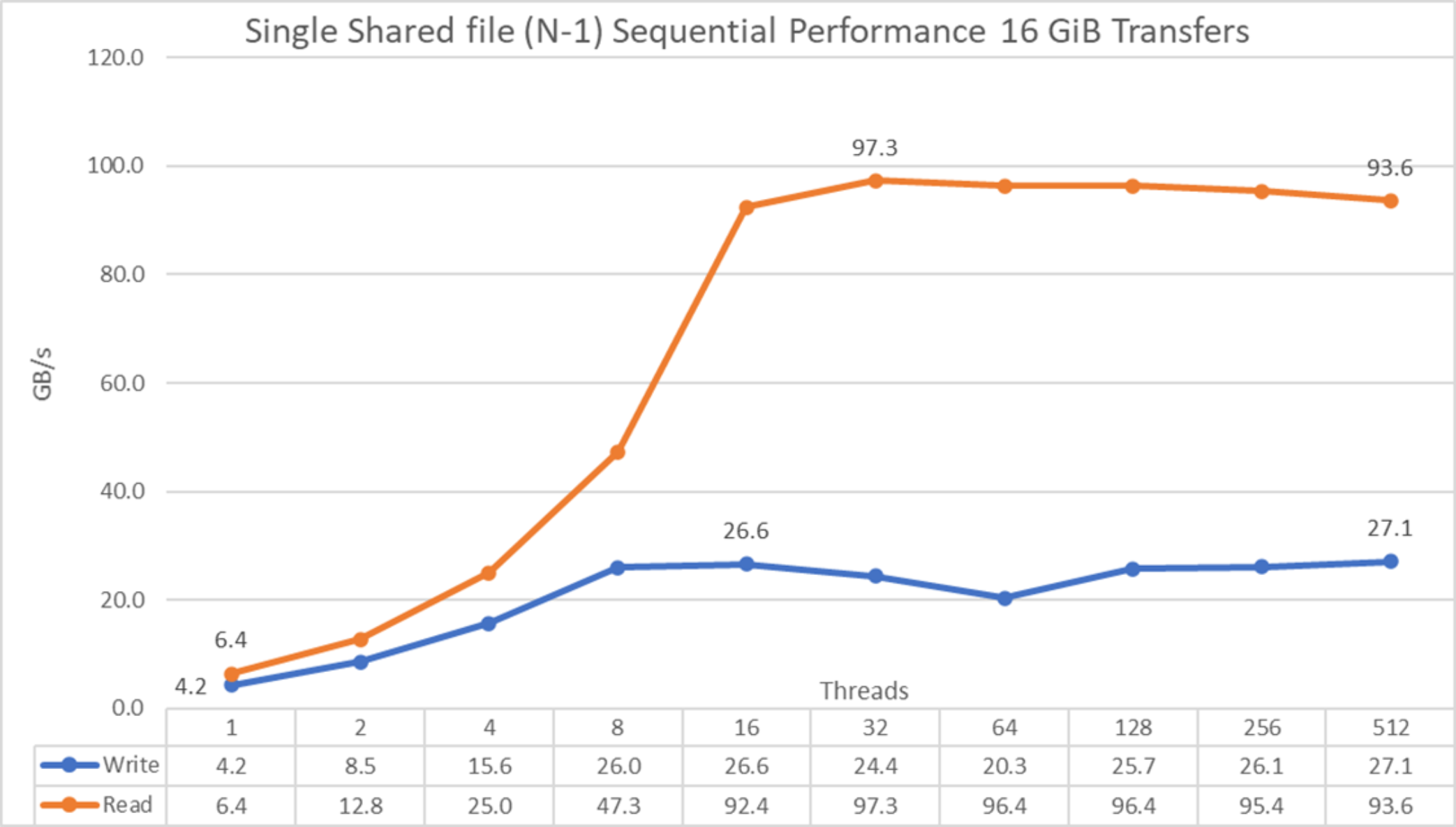
Figure 36. N to 1 sequential performance
From the results, we see that performance rises quickly with the number of clients used and then reaches a plateau for read operations at approximately 16 threads and for write operations at eight threads, and remain with only a small drop for read operations as the number of threads increases. The maximum read performance was 97.3 GB/s at 32 threads and for writes 27.1 GB/s at 512 threads. Note that performance rises faster compared to N-N tests, which might be due to having six more devices per server (compared to PowerEdge R650 servers) to distribute data, MPI plus IOR accesses being more efficient for write operations compared to IOzone, or some other reason that is not obvious. More investigation is needed to for this behavior.