
pixstor Solution with HDMD (without ME484s capacity expansion)
pixstor Solution with HDMD (without ME484s capacity expansion)
-
For this benchmark, we used results of the large configuration (two PowerEdge R750 servers connected to four ME5084 arrays) with the optional HDMD module (two PowerEdge R650 servers, each with 10 NVMe drives) Table 2 and Table 3 list the software versions used on the servers and clients respectively.
Sequential IOzone performance N clients to N files
Sequential N clients to N files performance was measured with IOzone version 3.492. The tests that we ran varied from a single thread up to 1024 threads.
We used files large enough to minimize caching effects, with a total data size of 8 TiB, more than twice the total memory size of the servers and clients (16 client X 128 GiB of RAM = 2 TiB, and including HDMD servers, 4 server X 256 GiB = 1 TiB, a total of 3 TiB). Note that GPFS sets the tunable page pool to the maximum amount of memory used for caching data, regardless of the amount of RAM that is installed and free (set to 16 GiB on clients and 96 GiB on servers to allow I/O optimizations). While other Dell HPC solutions used the block size for large sequential transfers as 1 MiB, GPFS was formatted with a block size of 8 MiB; therefore, use that value or its multiples on the benchmark for optimal performance. A block size of 8 MiB might seem too large and waste too much space when using small files, but GPFS uses subblock allocation to prevent this situation. In the current configuration, each block was subdivided into 512 subblocks of 16 KiB each.
The following commands were used to run the benchmark for write and read operations, where Threads was the variable with the number of threads used (1 to 1024 incremented in powers of 2), and threadlist was the file that allocated each thread on a different node, using the round robin method to spread them homogeneously across the 16 compute nodes. The FileSize variable has the result of 8192 (GiB)/Threads to divide the total data size evenly among all threads used. A transfer size of 16 MiB was used for this performance characterization.
./iozone -i0 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
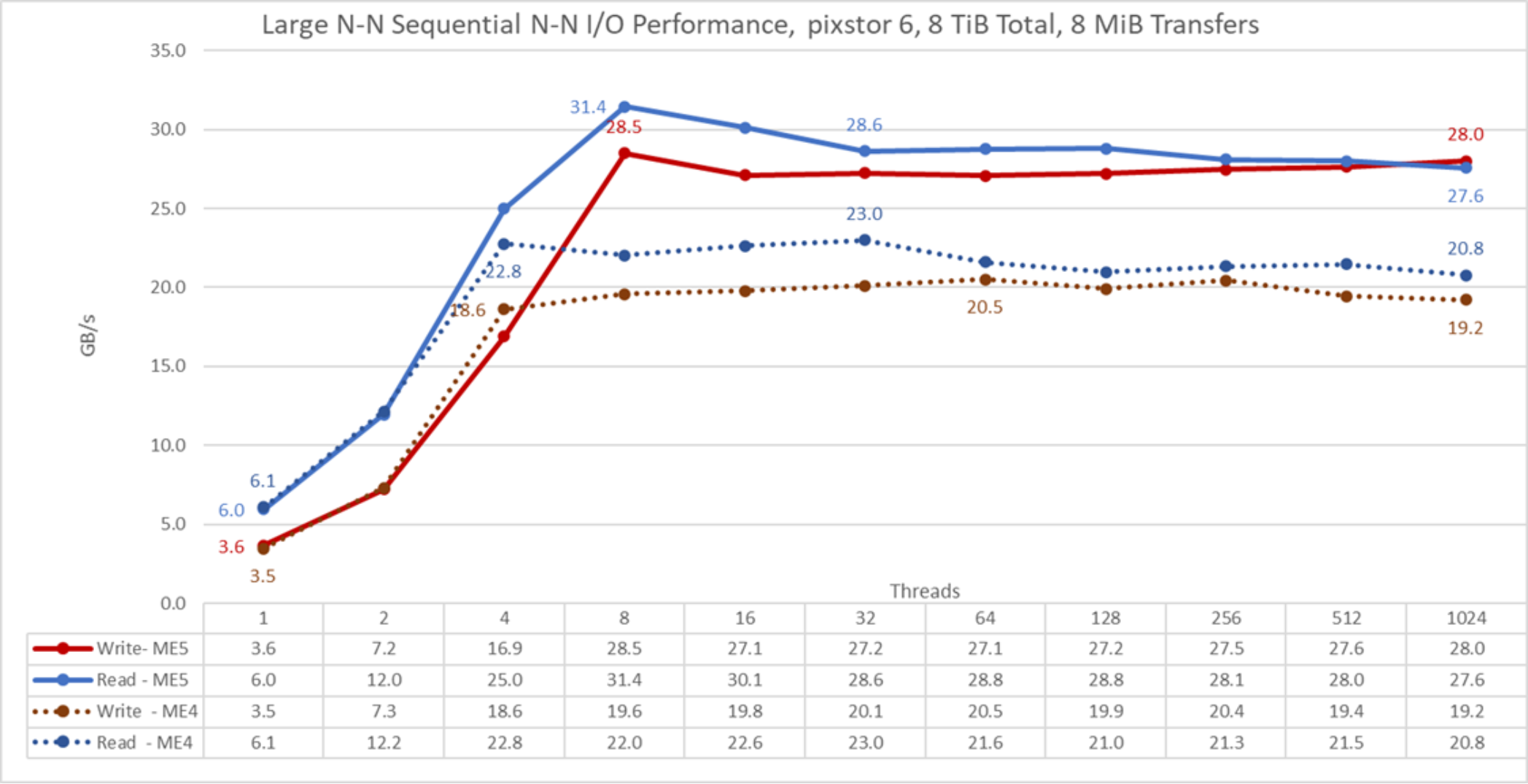
Figure 22. N to N sequential performance
From the results, we see that read performance is higher at low thread counts (>10 %) with a peak of 31.4 GB/s at eight threads where it was about 36.7 percent higher than peak performance with pixstor 6 and ME4 storage arrays. Most data points had an improvement of at least 24 percent and as much as almost 43 percent compared to what we observed with ME4 arrays, and a plateau with more than 27 GB/s. Write performance was almost the same for one and two threads. At eight threads, the write performance peak of 28.5 GB/s was 39 percent higher than ME4 peak write performance, a plateau of approximately 27 GB/s was reached with improvements from 32 percent to 46 percent compared to ME4 storage arrays.
Remember that for GPFS, the preferred mode of operation is scattered, and the solution was formatted to use it. In this mode, blocks are allocated right after file system creation in a pseudorandom fashion, spreading data across the whole surface of each HDD. While the obvious disadvantage is a lower initial maximum performance, performance remains constant regardless of how much space is used on the file system. This result is in contrast to other parallel file systems that initially use the outer tracks that can hold more data (sectors) per disk revolution. Therefore, these file systems have the highest possible performance the HDDs can provide, but as the system uses more space, inner tracks with less data per HDD revolution are used, with the consequent reduction of performance. GPFS also supports that allocation method (referred to as clustered), but it is only used on the pixstor solution as an exception in deployments under special conditions.
Sequential IOR Performance N clients to 1 file
Sequential N clients to a single shared file performance was measured with IOR version 3.4.0, with OpenMPI v4.1 4RC1 to run the benchmark over the 16 compute nodes. The tests that we ran varied from a single thread up to 512 threads because there are not enough cores for 1024 threads (the 16 clients have a total of 16 x 2 x 20 = 640 cores). Also, oversubscription overhead seemed to affect IOR results at 1024 threads.
Caching effects were minimized by setting the GPFS page pool tunable value to 16 GiB on the clients and 96 GiB on the servers, and using a total data size of 8 TiB, more than twice the RAM size from servers and clients combined. A transfer size of 16 MiB was used for this performance characterization. For a complete explanation, see Sequential IOzone Performance N clients to N files.
The following commands were used to run the benchmark, where Threads is the number of threads used (1 to 512 incremented in powers of 2), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes. The FileSize variable has the result of 8192 (GiB)/Threads to divide the total data size evenly among all threads used.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -w -s 1 -t 16m -b ${FileSize}G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -r -s 1 -t 16m -b ${FileSize}G
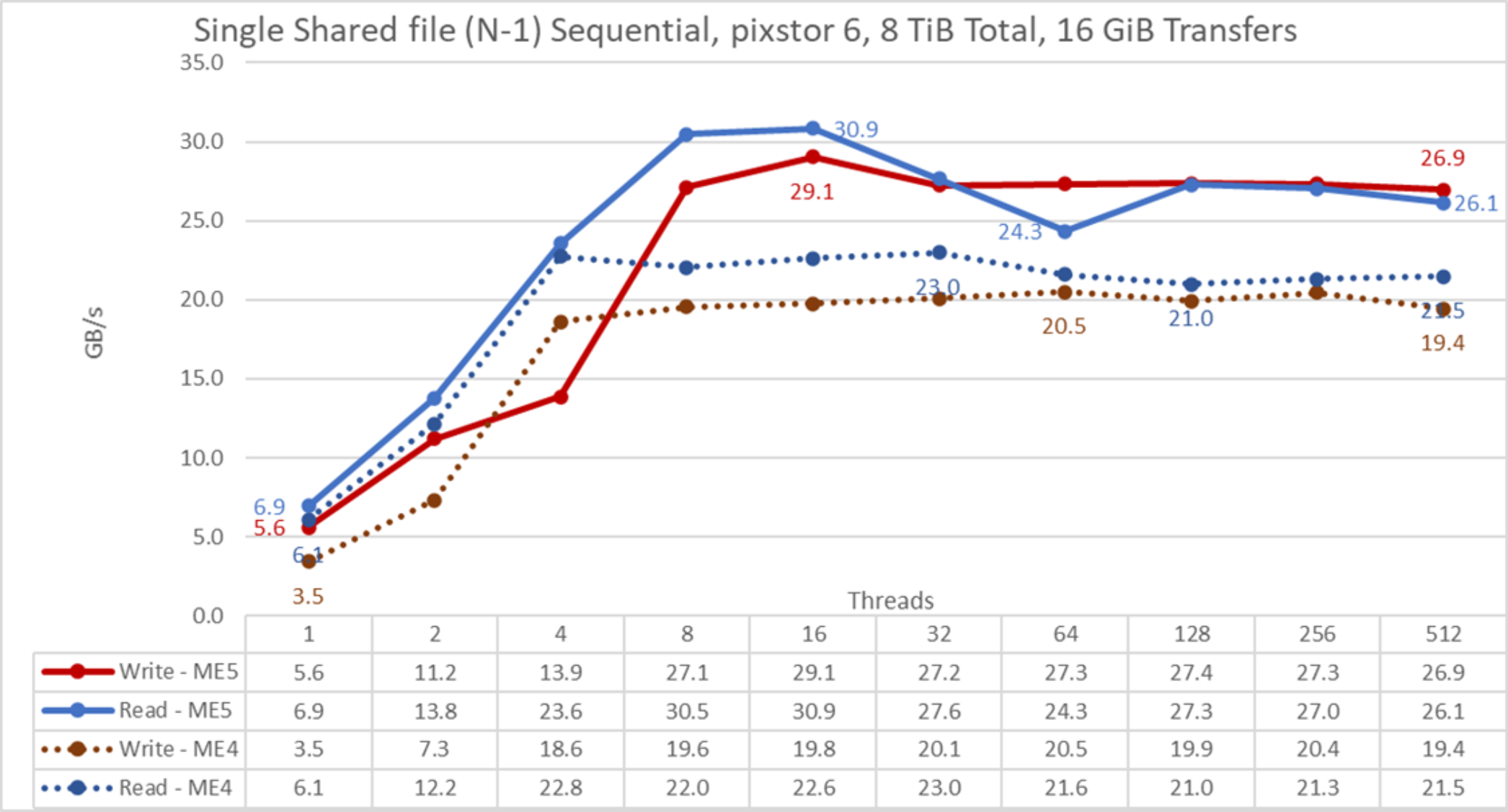
Figure 23. N to 1 sequential performance
From the results, we see that read performance is again higher at low thread counts (>13%) with a peak of 30.9 GB/s at 16 threads, where it was about 34.1 percent higher than peak performance with pixstor 6 and ME4 arrays. Most data points had an improvement between 20 percent and 38 percent compared to what we observed with ME4 arrays, and a plateau of approximately 27 GB/s (except the case with 64 threads, where performance dropped consistently about 3 GB/s, requiring further investigation). Write performance for one and two threads was high compared to ME4 arrays, with 62 percent and 53.6 percent respectively. At 16 threads, the write performance peak of 28.5 GB/s was 41.7 percent higher than ME4 peak write performance, a plateau of approximately 27 GB/s was reached with improvements from 33 percent to almost 47 percent compared to ME4 arrays. The write performance at four threads was consistently lower than expected, requiring more investigation about a possible cause.
Random small blocks IOzone Performance N clients to N files
Random N clients to N files performance was measured with IOzone version 3.492. Tests results varied from 16 up to 512 threads, using 4 KiB blocks for emulating small block traffic. Lower thread counts were not used because they provide little information about maximum sustained performance and random reads execution time can take several days for a single data point (IOzone does not offer an option to run separate random writes from reads). The reason for the low random read performance is because there is not enough I/O pressure to schedule read operations, due to the combined effect of the behavior of the mq-deadline I/O scheduler on the Linux operating system and the internal ME5 array controller software, delaying read operations until a threshold is met.
Caching effects were minimized by setting the GPFS page pool tunable to 16 GiB on the clients and 32 GiB on the servers and using at least files twice that size. Sequential IOzone performance N clients to N files provides a complete explanation about why this methodology is effective on GPFS.
The following command was used to run the benchmark in random IO mode for both writes and reads, where Threads was the variable with the number of threads used (from 16 to 512 incremented in powers of 2), and threadlist was the file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes.
./iozone -i0 -c -e -w -r 16M -s ${Size}G -t $Threads -+n -+m ./threadlist
./iozone -i2 -O -w -r 4K -s ${Size}G -t $Threads -+n -+m ./threadlist
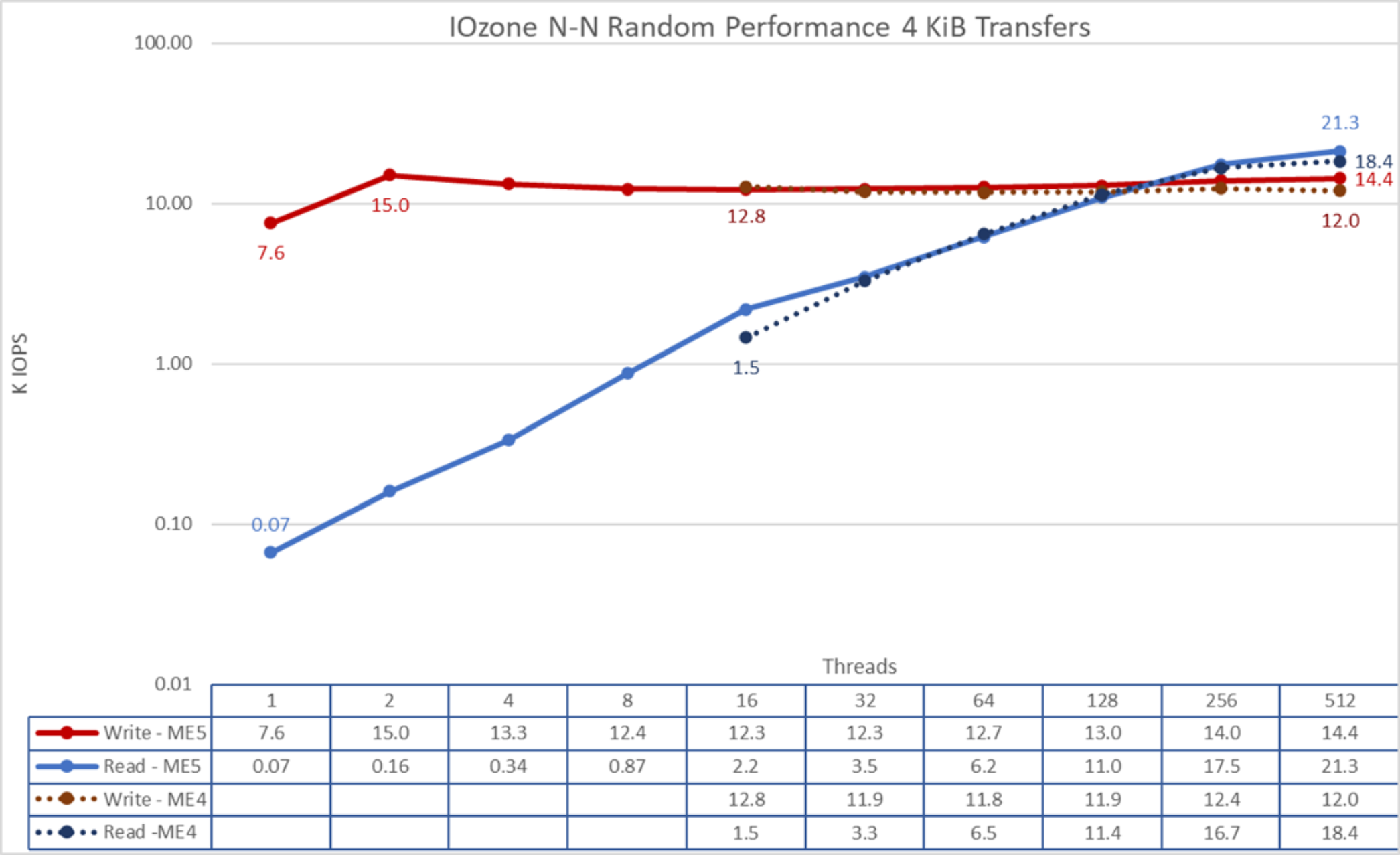
Figure 24. N to N random performance
From the results, we see that write performance starts at a high value of almost 8K IOPS and reached a peak of 15K IOPS at two threads, decreasing into a plateau of about 12K IOPS and reaching a second high value of 14.4K IOPS at 512 threads. Compared to ME4 arrays, write performance was similar for thread counts below 128 (within ±10 percent); ME5 arrays showed an improvement from 12.2 percent at 128 threads to 19.4 percent at 512 threads. Alternately, read performance starts small at 0.07K IOPS and increases performance almost linearly with the number of clients used (note that the number of threads is doubled for each data point) until it reaches the maximum performance of 21.3K IOPS at 512 threads with signs of approaching a maximum. However, using more threads (1024) on the current 16 compute nodes than the number of cores (640) seems to cause overhead, which can limit performance. A future test with more compute nodes can check the random read performance that can be achieved with 1024 threads with IOzone. Also, FIO or IOR can be used to investigate the behavior with more than 1024 threads. Compared to ME4 arrays, read performance was similar (within ± 5 percent), except at 16 and 512 threads, with improvements of 50.7 percent and 15.4 percent respectively.