
PowerEdge R660
PowerEdge R660
-
PowerEdge R660 Random small blocks IOzone Performance N clients to N files
Random N clients to N files performance was measured with IOzone version 3.492. The tests that we ran varied from one up to 1024 threads, using 4 KiB blocks for emulating small blocks traffic. We minimized caching effects by setting the GPFS page pool tunable to 12 GiB on the clients and 128 GiB on the servers (four PowerEdge R660 nodes) and using total data size of 1 TiB.
Because this test requires more clients, eight additional C6525 clients were added, all with the CPUs EPYC 7452 32 cores @ 2.35 GHz. The rest of the clients’ characteristics are the same as the four AMD clients described in Table 2.
The following command was used to run the benchmark in random IO mode for both read and write operations, where the Threads variable is the number of threads used (from 1 to 1024 incremented in powers of 2), and threadlist was the file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes.
./iozone -i0 -c -e -w -r 16M -s ${Size}G -t $Threads -+n -+m ./threadlist
./iozone -i2 -O -w -r 4K -s ${Size}G -t $Threads -+n -+m ./threadlist
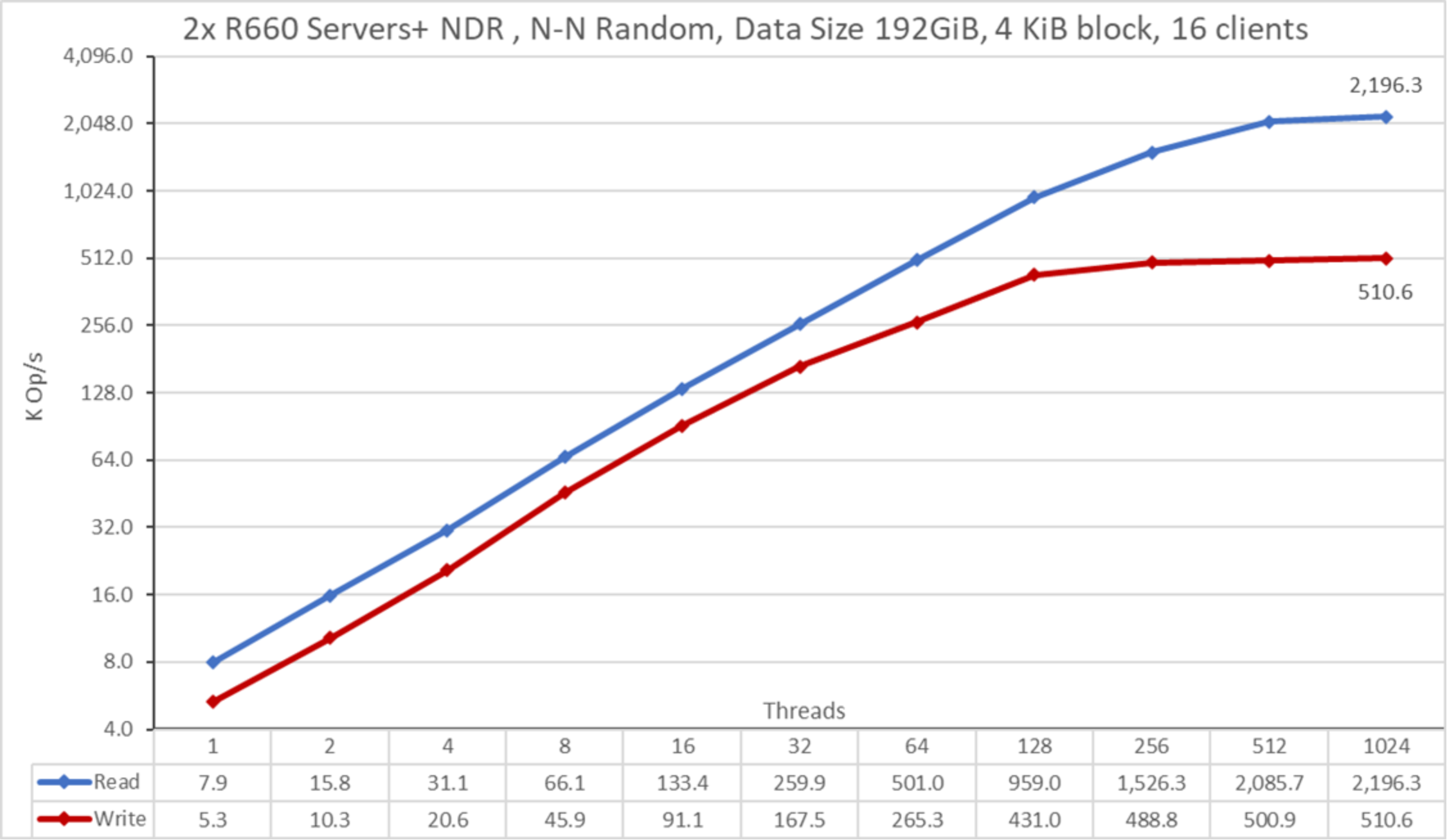
Figure 16. N to N Random PerformanceThe scale chosen was logarithmic with base 10 to allow comparing operations that have differences of several orders of magnitude; otherwise, some of the operations appear like a flat line close to 0 on a normal graph. A log graph with base 2 is more appropriate, because the number of threads are increased by powers of 2. Such a graph looks similar, but people tend to perceive and remember numbers based on powers of 10 better.
From the results, we see that write performance starts at a high value of approximately 5.3K IOPS and rises to a plateau of 500 KIOPS at approximately 256 threads and to the maximum of 510.6K IOPS at 1024 threads. Read performance starts at 7.9 KIOPS and increases performance with the number of clients used until it reaches the maximum performance of 2,196.3K IOPS at 1024 threads with signs of approaching a plateau.
The results are not much higher than the previous release, as expected from the higher number of drives and the improved specifications for NVMe Gen5 drives and NDR. These results might be related to several factors, such as the selection of the block and subblock size, as described in the PowerEdge R660 NVMe benchmarking section. Future investigation on these servers might include using 16KiB subblocks (512 divisions/block, requiring modification to the metadata block/subblock sizes as the number of subdivisions must match those subdivisions used for data).
As previously explained, using more threads on the current 16 compute nodes than the total number of cores (768) might incur more context switching, which can limit peak performance. A future test with more physical compute nodes can check the random read performance that can be achieved with 1024 threads on IOzone. Also, FIO or IOR with more nodes (cores) can be used to investigate the behavior with more than 1024 threads.