
PowerEdge R660
PowerEdge R660
-
PowerEdge R660 Sequential IOzone Performance N clients to N files
We measured Sequential N clients to N files performance with IOzone version 3.492. The tests that we ran varied from a single thread up to 1024 threads.
We used files large enough to minimize caching effects, with a total data size of 8 TiB, twice the total memory size of servers (two R660 nodes) and clients. GPFS sets the tunable page pool to the maximum amount of memory used for caching data, regardless of the amount of RAM that is installed and is free (set to 12 GiB on clients and 128 GiB on servers to allow I/O optimizations). While other Dell HPC solutions use a 1 MiB block size for large sequential transfers, GPFS was formatted with a block size of 8 MiB. Therefore, we use that value or its multiples (16 MiB in this case) on the sequential benchmarks for optimal performance.
The following commands were used to run the benchmark for read and write operations, where the Threads variable is the number of threads used (1 to 1024 incremented in powers of 2), and threadlist was the file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the eight compute nodes. The FileSize variable has the result of 8192 (GiB)/threads to divide the total data size evenly among all threads used. A transfer size of 16 MiB was used for this performance characterization.
./iozone -i0 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
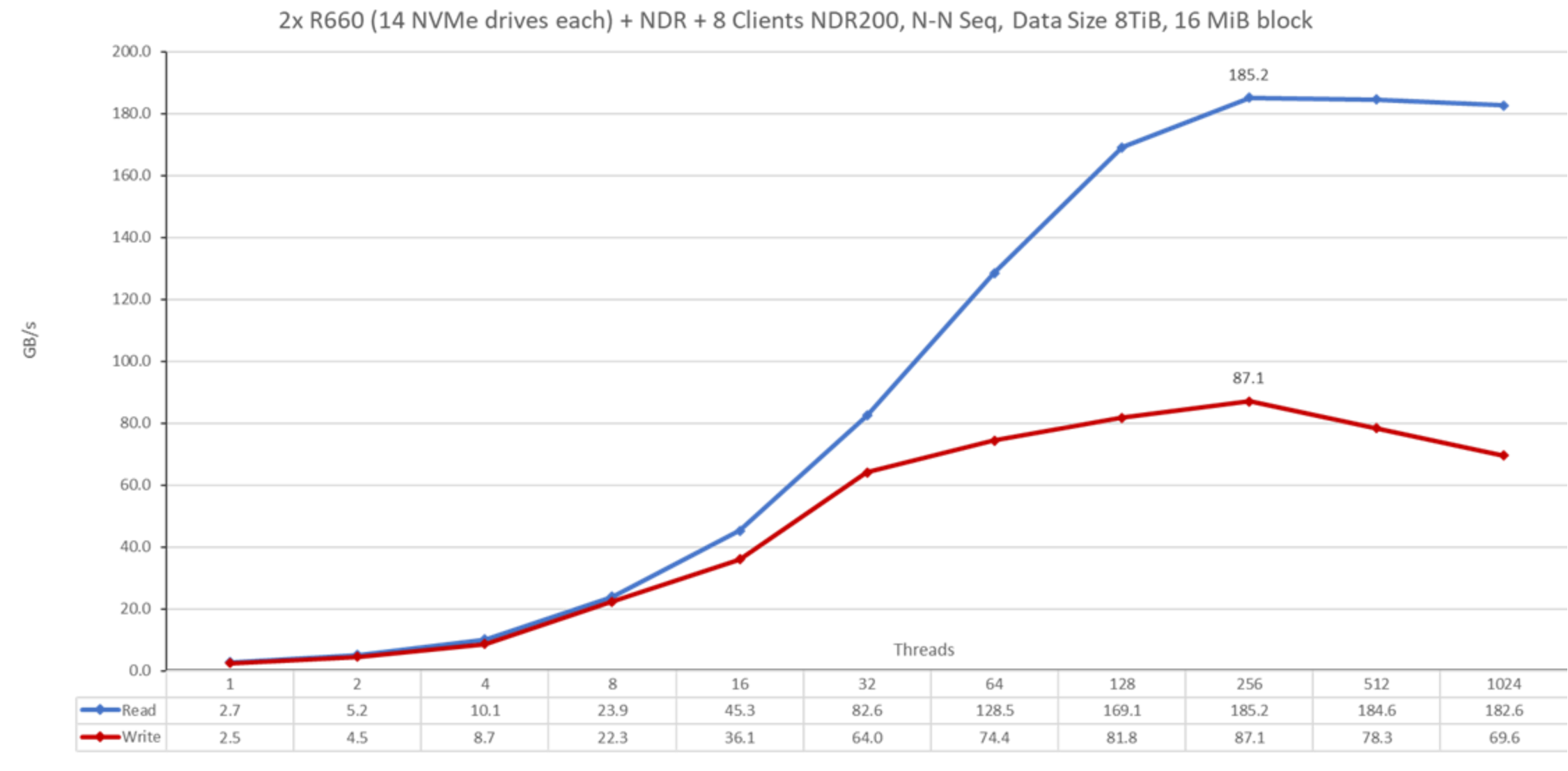
Figure 13. N to N Sequential PerformanceFrom the results, we see that read performance reaches a peak of 185.2 GB/s at 256 threads and then stays in a plateau of approximately 180 GB/s. A considerable increase from the previous generation of PowerEdge R650 servers with NVMe Gen 4 that had a plateau of about 180 GB/s for twice the number of NVMe R650 nodes (four).
The write performance reached a plateau of approximately 70 GB/s at 32 threads, with a peak at 87.1 GB/s at 256 threads. Compared to the previous generation, the peak performance improves substantially, considering that the peak was 40.2 GB/s for four servers. However, PowerEdge R660 servers have a less stable write plateau than PowerEdge R650 servers. It is possibly due to overhead that is caused by the number of threads along with the replication used for write operations; more investigation is needed to determine the cause.
Write performance might look low compared to read performance, however, consider the following factors:
- Replication was used to create a copy for each NVMe device (NSD) on a different server for HA purposes, effectively creating a data mirror.
- Only half of the NVMe drives contribute to write performance, while the other half become required overhead to mirror data.