
Overview
Overview
-
This chapter describes the architecture of the Dell Red Hat Pacemaker cluster solution for SAP HANA.
SAP services
SAP solutions consist of multiple components and services that interact with one another to form a comprehensive network of functions, including:
- ABAP SAP Central Services (ASCS)
- Enqueue Replication Server (ERS)
- Primary Application Server (PAS)
For more information, see Table 1.
For normal operation, only the ASCS instance is needed. In a failover scenario, the newly started ASCS instance receives the status from the ERS instance, and the normal operation can continue within seconds. Without the ERS, restarting the ASCS instance results in the loss of all database table locks, and the same object can become editable by two people simultaneously, potentially resulting in data loss. When one side fails, the service is automatically started on the other server. The service switches back as soon the failed node is back online. For more information, see SAP ASCS High Availability using ERS explained.
In a data center failover scenario, the targeted workload of the servers must be below 50 percent capacity; otherwise, your servers will be overloaded when one side fails. In a single data center scenario, the remaining application servers must be able to handle the load of the failed server. The target load for peak operation can be calculated using the formula 1-1/N, where N is the number of application servers in the data center. System administrators must monitor this load during normal operations and add additional hardware when the load of the servers is higher.
It can also be beneficial to separate the cluster nodes geographically for protection against site-wide or regional disasters. A clustering solution allows failover between cluster nodes on different cloud subnets or in geographically separated locations.
Monitoring
To be effective, an HA solution must monitor the health of all these services. If a service fails or does not perform as expected, the HA solution takes the necessary action to recover that service as quickly as possible. The solution brings services online in the secondary nodes and in the correct order to ensure that SAP functions resume quickly, and that data is not corrupted. Failover clustering protection ensures a minimal downtime of services and thus minimal impact to end users. In parallel, the database is protected by the replication of its data to a secondary node in the same HA cluster, eliminating the SAN single point of failure.
Dell Technologies recommends using a monitoring solution to ensure that the cluster is kept in a state in which it can fulfill its main function of protecting against failures. Tools such as Prometheus and Grafana enable you to view and report on the status of the cluster and its resources.
Cluster architecture
The SAP landscape consists of three components:
- One highly available SAP HANA cluster (active/passive)
- One highly available ACSC/ERS cluster
- At least two application servers, split between two data centers (active/active). The instances are split between data centers in active/active or active/passive configurations, as shown in the following figure:
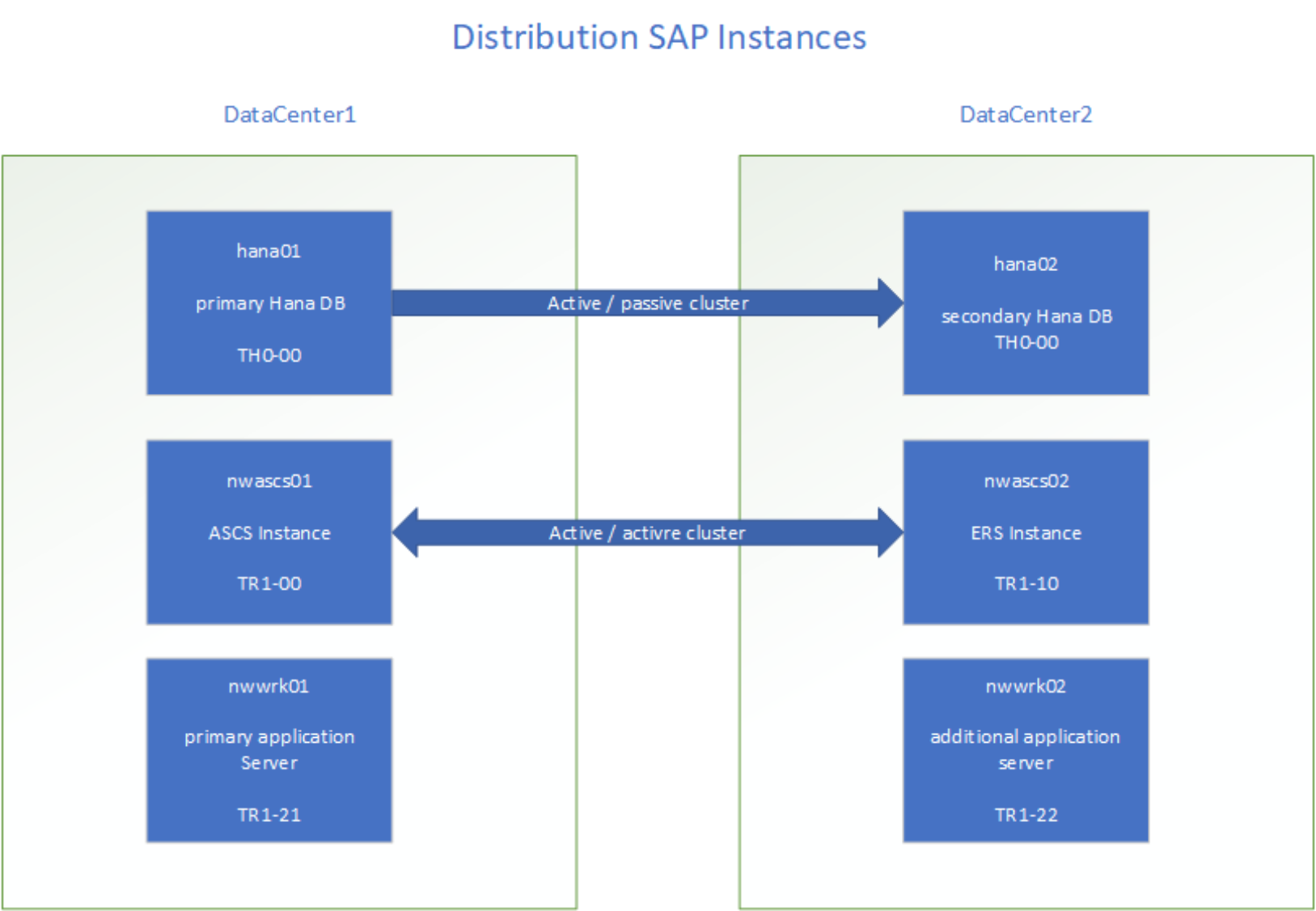
Figure 1. Cluster architecture
Several availability concepts protect against disasters. Dell SAP engineering used a two-node SUSE Enterprise Linux Server pacemaker cluster with SAP HSR instead of switching a single database instance over to the secondary host. The availability needs of your system determine the best option for your environment.
By using the “syncmem” replication mode, the Dell team achieved failover times in the order of seconds. These times were faster than a complete database startup that would require transferring the data disks to the other host.
Note: The described cluster is not a replacement for a classic backup. This configuration does not prevent data loss when data in the database is deleted by mistake.