Test results
Test results
-
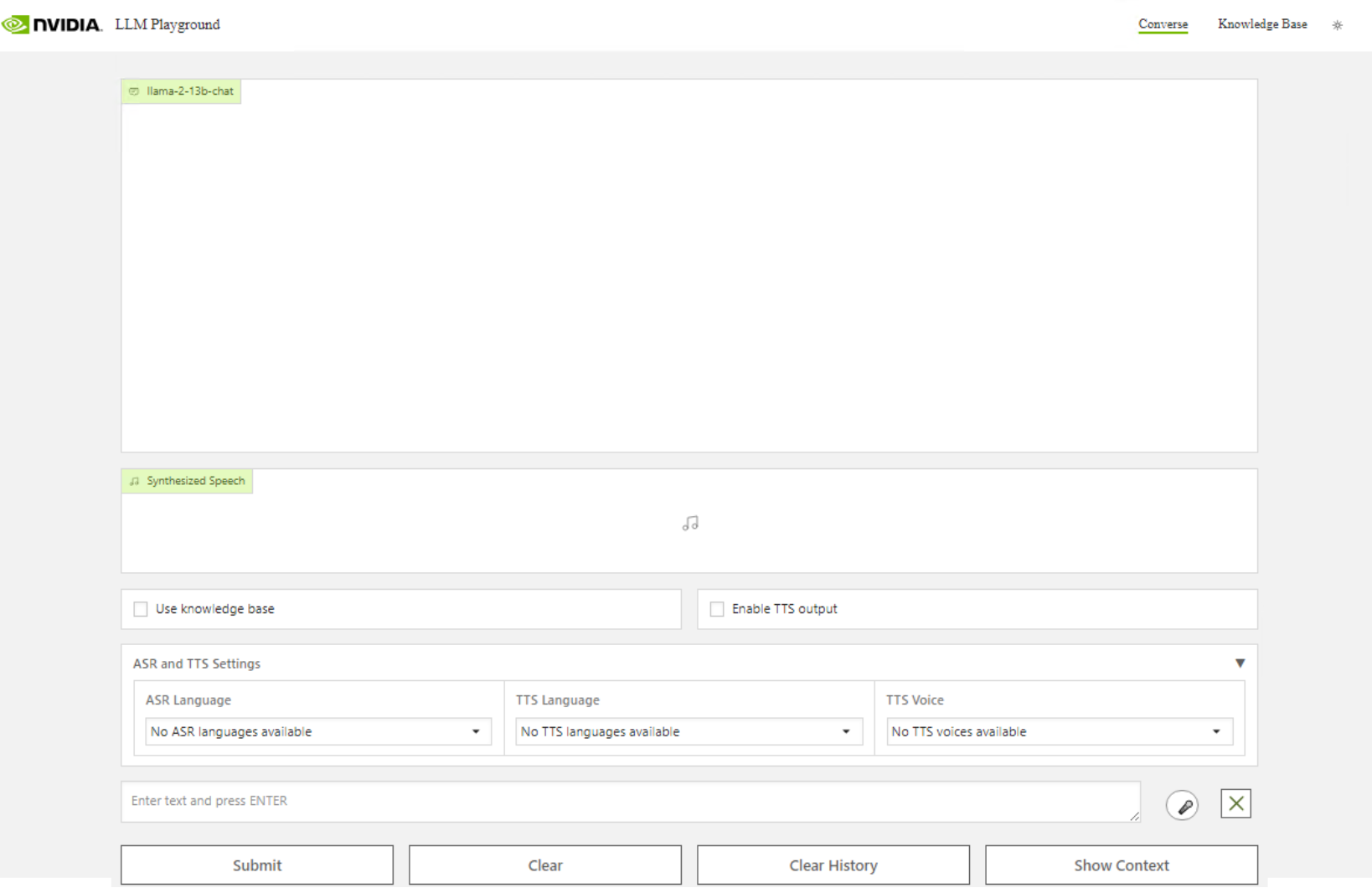
We can now view the front end of the RAG LLM Playground. We have Llama-2-13b-chat running on-premises. We can ingest documents for queries.
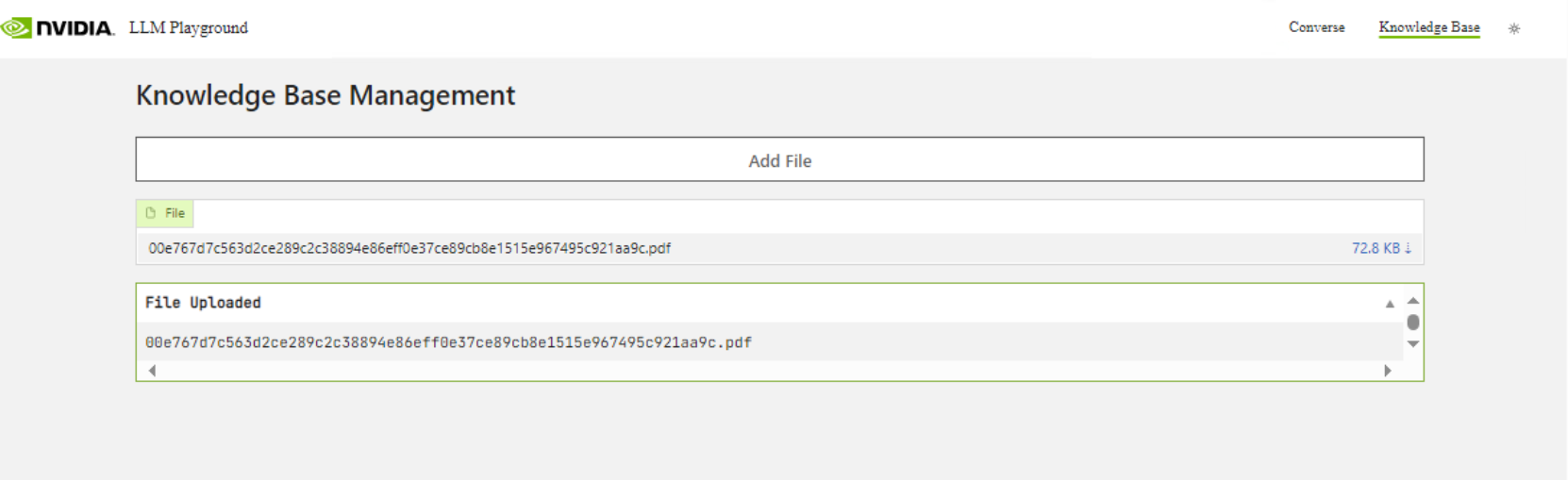
To add documents to be queried by the LLM, Select Knowledge Base.
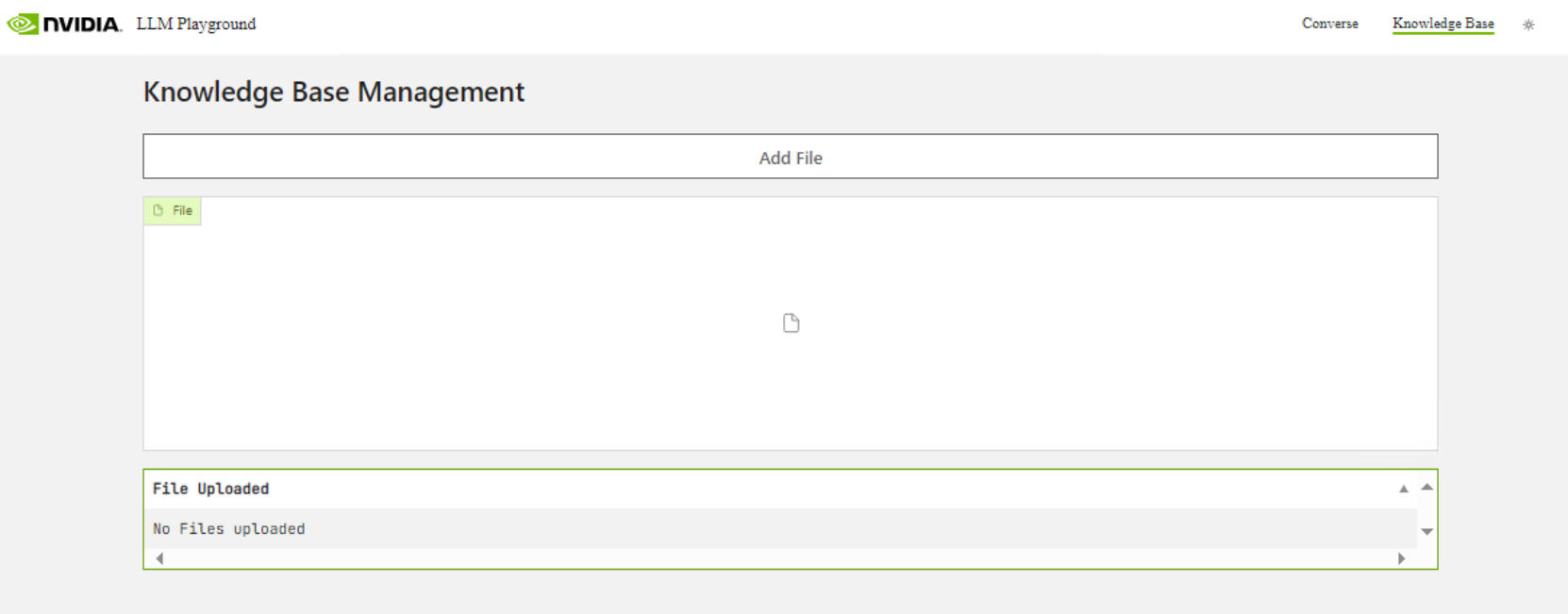
Select Add File to add PDFs to the RAG LLM.
Output:
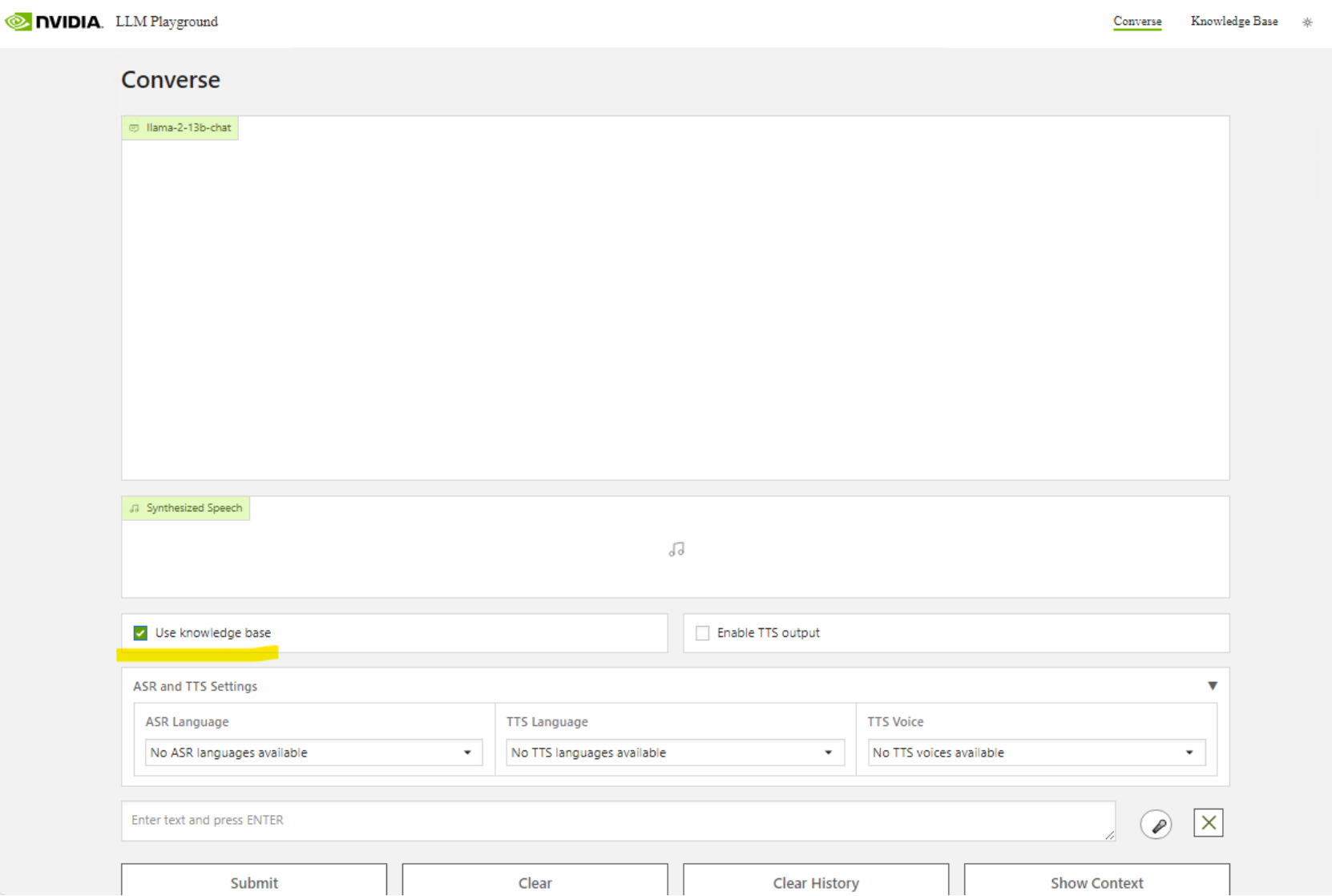
Select Converse and begin to ask it questions about your data by selecting the checkbox for "Use Knowledge Base."We can now ask the LLM about the information contained within our documents.
Note: You can also import documents by installing python notebook or through the FASTAPI.
Python Notebook:
Install Python Notebook (pip install notebook)
Jupyter Notebook Link:
https://github.com/NVIDIA/GenerativeAIExamples/blob/main/notebooks/05_dataloader.ipynb
Copy the contents of the dataloader notebook into your notebook file. Then, put your PDFs in a data folder or edit the path to the data in the notebook.
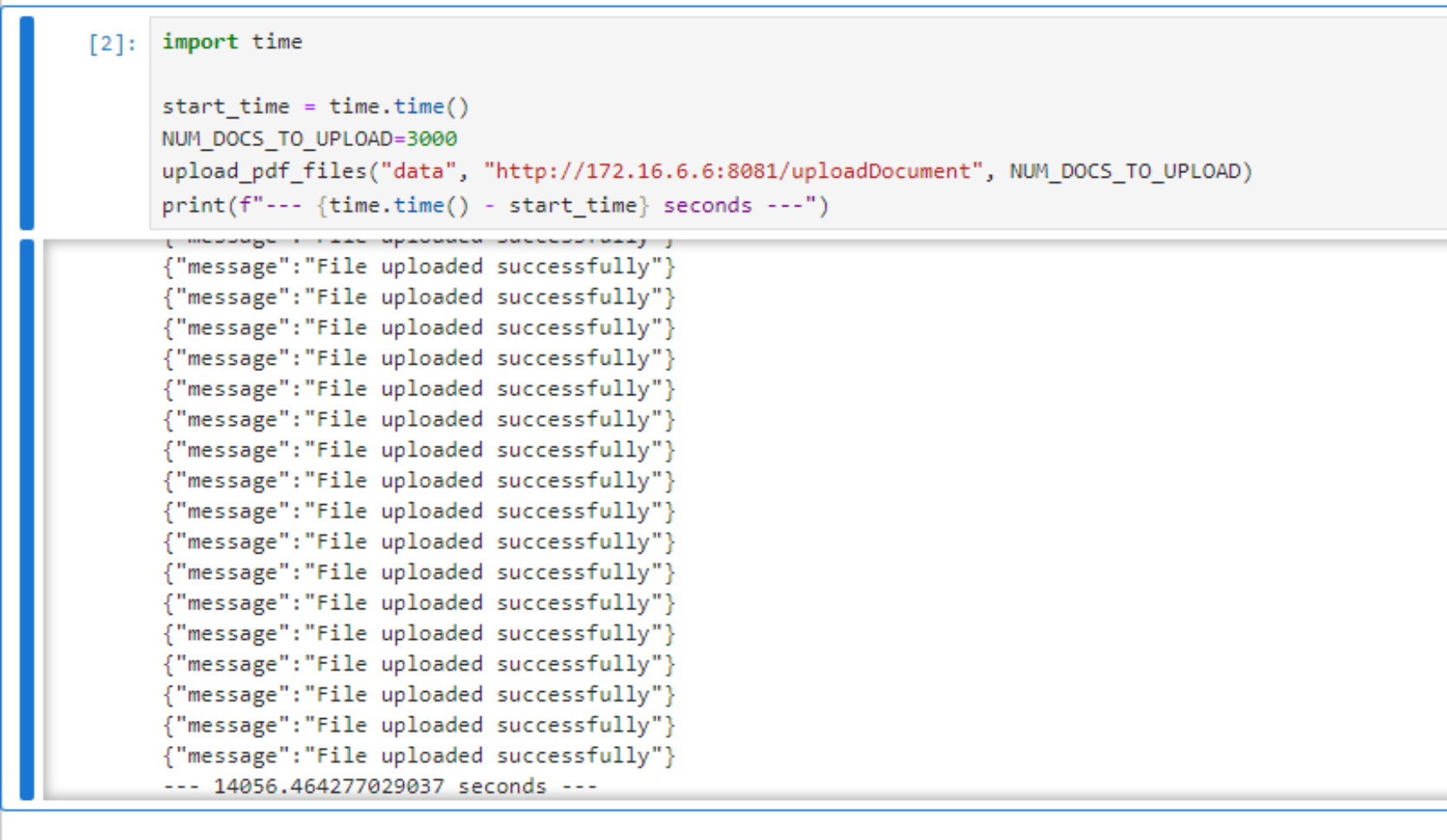
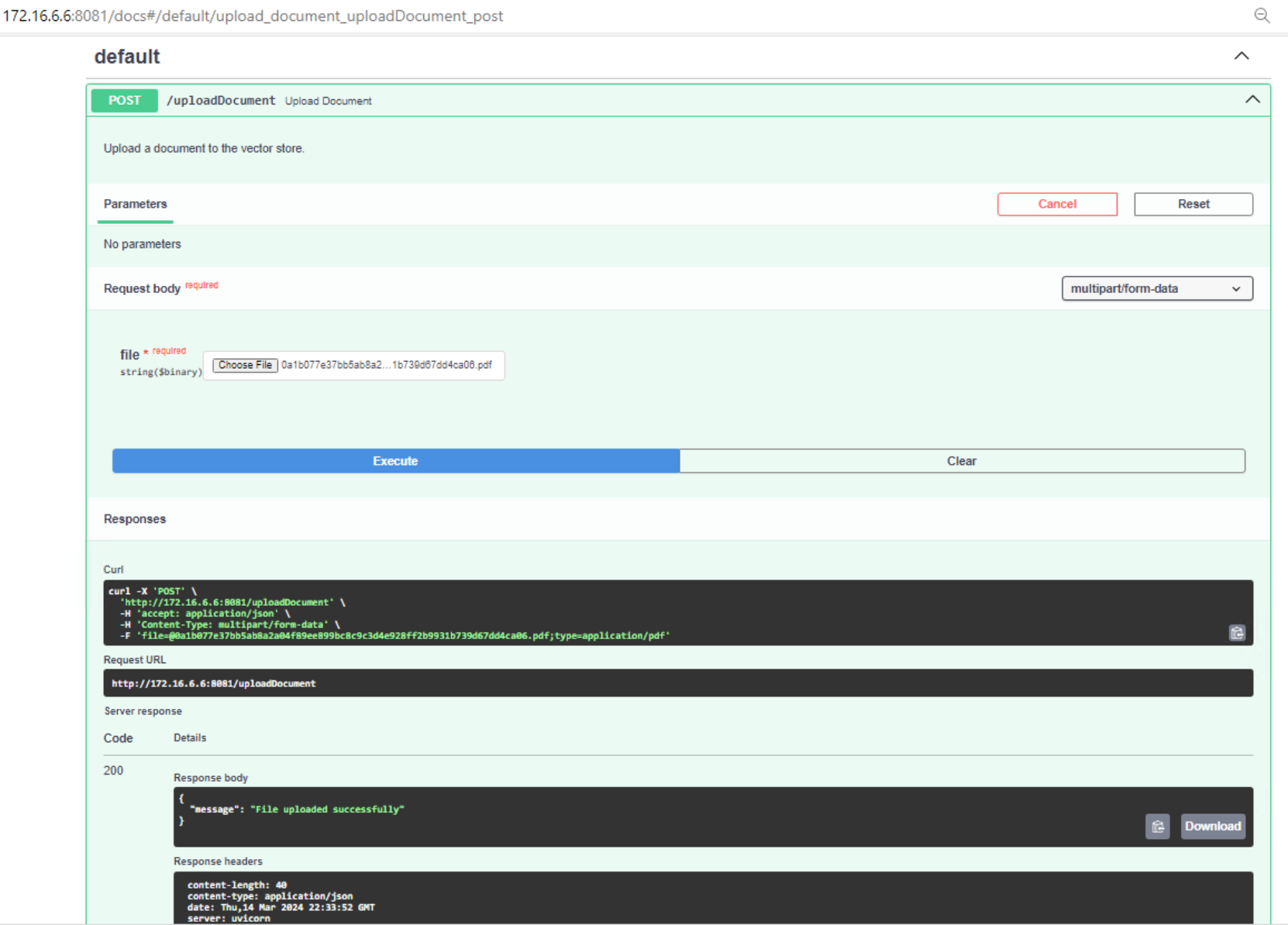
To use the FASTAPI method to ingest documents, do a port forward on the query router.