
Solution approach
Solution approach
-
Document Ingestion
The first function of a RAG pipeline is to populate a repository with information from enterprise data sources. A large language model can only answer questions from the data used to train it. RAG supplements an LLM's foundational information with a database of additional knowledge that is more up to date, more relevant, or proprietary to the data owner.
Popular LLM programming frameworks such as LlamaIndex and LangChain provide connectors to many familiar enterprise data sources. This example pipeline uses an unstructured connector to input unstructured data such as text documents and PDFs.
A preprocessor prepares the data before it is added to the RAG database. Data preprocessing often determines the quality and relevancy of the data retrieved from the database to respond to a query. The preprocessor in this example splits the data into chunks based on sentence length. Other preprocessing activities include anonymization, deduplication, or toxicity filtering.
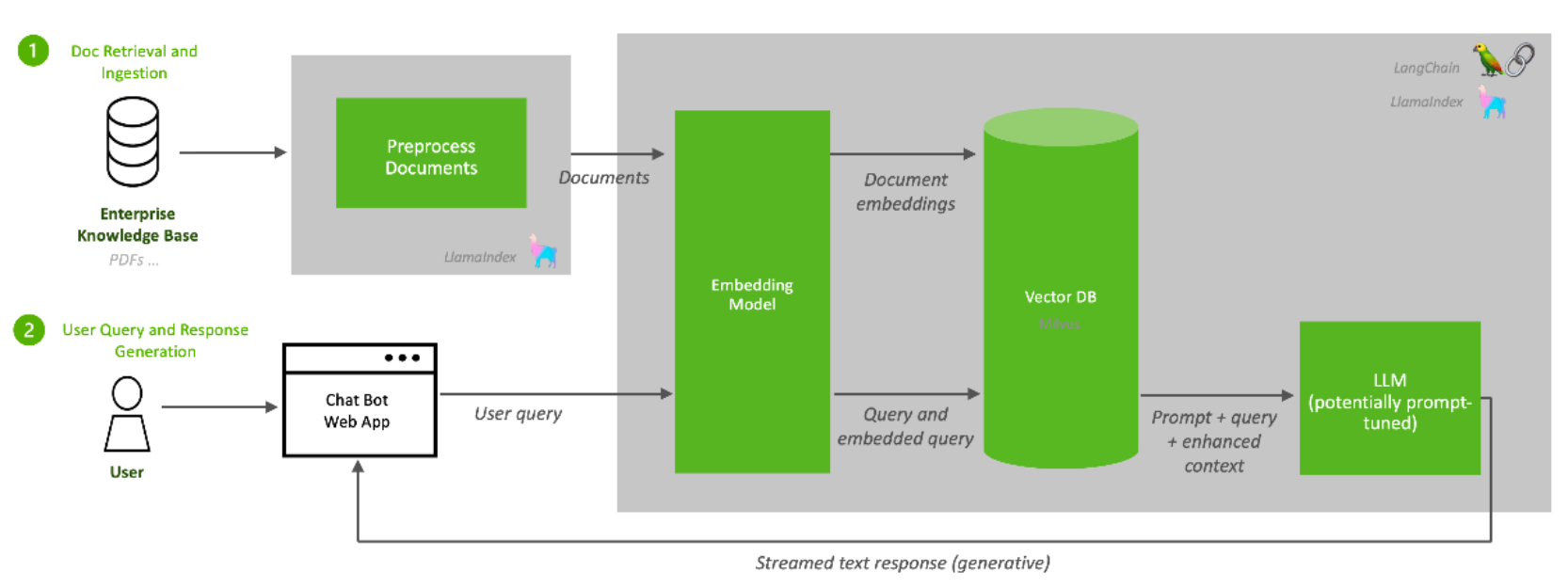
The processed data is then sent to the embedding microservice. Embedding converts data chunks into vector representations that can be efficiently searched and retrieved. This example uses the NV-Embed-QA embedding model, developed by NVIDIA, for efficient, GPU-accelerated document embedding.The embeddings are then stored in a vector database for efficient search and retrieval through indexing. Many commercial and open-source vector databases have various cost/performance/reliability tradeoffs. This example pipeline uses PGvector, a vector database implementation of the popular Postgres SQL database. PGvector supports several standard vector search and vector indexing approaches.
The PGvector database deployed in this reference design is backed by Dell PowerScale Network Attached Storage (NAS) for data persistence. The volume is exposed to the PGvector pod as a Kubernetes persistent volume claim from the Isilon storage class.
While PGvector is not GPU accelerated, the reference design supports using several GPU-accelerated vector databases such as Milvus, FAISS, and Redis.
Also note that, although it is not shown in this reference design, RAG administrators should implement a process for regular or continuous data ingestion to keep the database up to date.