
Solution approach
Solution approach
-
Paving the Way for Advanced AI Deployments with NVIDIA RAG and Dell Technologies
The successful deployment of NVIDIA RAG on Dell Technologies' infrastructure requires a strategic approach that carefully balances hardware and software considerations to achieve optimal performance, scalability, and efficiency. A critical aspect of this deployment involves the management of containerized workloads and services, for which we leverage Kubernetes—an open-source platform renowned for its portability, extensibility, and comprehensive support for declarative configurations and automation.
Figure 1: High-level diagram
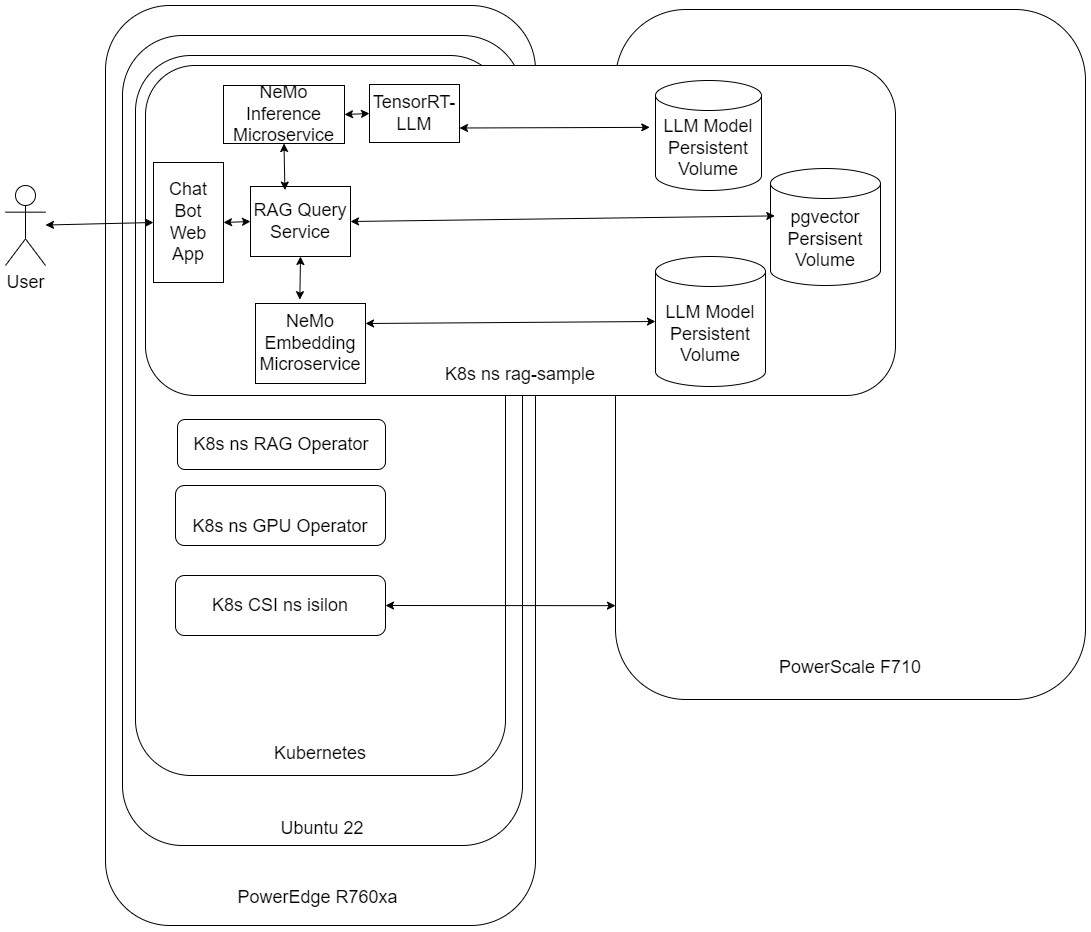
Kubernetes: Orchestration and Management
Kubernetes is an open-source container orchestration platform that offers several compelling reasons for enterprise adoption. It has simplified deployment and scaling, improved resource utilization, allowed fault tolerance, self-healing, service discovery, and load balancing, and provided application portability to avoid vendor lock-in. These benefits lay the groundwork for a robust deployment strategy, ensuring that the technical requirements of NVIDIA RAG applications are met with efficiency and scalability at the forefront.
Dell CSI PowerScale for Kubernetes: Optimized Storage for Containerized Environments
Central to our deployment strategy is integrating the pivotal feature from Kubernetes that our solution capitalizes with the Persistent Volume (PV) storage subsystem. This subsystem abstracts the details of storage provisioning and consumption, enabling applications like NVIDIA RAG to efficiently access the persistent storage they require for content, databases, and AI models. This is where Kubernetes' ability to allow users to request storage using Persistent Volume Claims (PVC) becomes invaluable, mainly when using Storage Classes for tailored specific needs.
We harness the capabilities of Dell Technologies Container Storage Modules (CSM) to enable a simple and consistent integration with Kubernetes Container Storage Integration (CSI) with PowerScale OneFS. This leverages the hardware's robustness and scalability to meet the demanding storage requirements of NVIDIA RAG applications. The Container Storage Interface (CSI) driver for Dell PowerScale is essential, facilitating seamless integration and optimized management, provisioning, and scaling of persistent storage within Kubernetes clusters. This ensures our solution benefits from high-performance and scalable storage, highlighting the operational simplicity and consistency Kubernetes' storage management capabilities provide.NVIDIA Cloud Native Stack and NVIDIA AI Application Framework: Comprehensive AI Platform
Complementing this sophisticated storage and orchestration framework is NVIDIA AI Enterprise, an end-to-end, cloud-native software platform designed to accelerate data science pipelines and streamline the development and deployment of production-grade AI applications.
NVIDIA Cloud Native Stack (formerly Cloud Native Core) is a collection of software designed to run cloud-native workloads on NVIDIA GPUs. The foundation and components are based on Ubuntu, Kubernetes, Helm, NVIDIA GPU, and Network Operator. NVIDIA actively contributes to open-source projects and communities, including container runtimes, Kubernetes operators, and monitoring tools. Applications developed using NVIDIA Cloud Native technologies are cloud-native and enterprise-ready. This includes GPU operators to automate the life cycle management of software required to expose GPUs on Kubernetes. It enhances GPU performance, utilization, and telemetry, allowing organizations to focus on building applications.
NVIDIA AI Enterprise, the software layer of the NVIDIA AI platform, offers 100+ frameworks, pre-trained models, and development tools to accelerate data science and streamline the development and deployment of production AI, including generative AI, computer vision, and speech AI. Its integration into our deployment strategy speeds up time to value with enterprise-grade security, stability, manageability, and support while mitigating the risk of open-source software, ensuring business continuity and a reliable platform for running mission-critical AI applications.
Together, these components create a robust ecosystem to facilitate the rapid deployment and effective scaling of NVIDIA RAG on Dell Technologies' infrastructure. By strategically leveraging Kubernetes for orchestration, Dell Technologies for optimized storage, and NVIDIA for comprehensive AI platforms, organizations can fully leverage AI to drive their mission forward, ensuring a seamless, scalable, and efficient deployment strategy that meets the advanced requirements of modern AI applications.
Large Language Models
The decision to use LLMs was driven by their ability to understand context, generate relevant responses, and interact in a manner that is almost indistinguishable from a human. This level of sophistication allows us to provide users with a more engaging and efficient service.
Why Llama-2-13B-Chat Model?
Among the various LLMs available, deploying with the Llama-2-13B-Chat model was based on several key factors:
- Performance: The Llama-2-13B-Chat model has superior performance in tests, outperforming open-source chat models on most benchmarks. Its performance is on par with popular closed-source models like ChatGPT and PaLM.
- Optimization for Dialogue: Unlike many LLMs, the Llama-2-13B-Chat model is fine-tuned explicitly for dialogue use cases. This means it can provide accurate and contextually relevant responses in a conversational setting.
- Advanced Training Techniques: The model uses supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF), aligning it closely with human preferences for helpfulness and safety.
Deploying Different Inference Models
While we have chosen the Llama-2-13B-Chat model, it is important to note that organizations can deploy different inference models based on their specific needs from your organization and team NGC Private Registry. The choice of model can be influenced by factors such as the task's nature, the required accuracy level, and the computational resources available. Additional models can be found in NVIDIA's NGC Private Registry at https://registry.ngc.NVIDIA.com/models.
Document Ingestion
The first function of a RAG pipeline is to populate a repository with information from enterprise data sources. A large language model can only answer questions from the data used to train it. RAG supplements an LLM's foundational information with a database of additional knowledge that is more up to date, more relevant, or proprietary to the data owner.
Popular LLM programming frameworks such as LlamaIndex and LangChain provide connectors to many familiar enterprise data sources. This example pipeline uses an unstructured connector to input unstructured data such as text documents and PDFs.
A preprocessor prepares the data before it is added to the RAG database. Data preprocessing often determines the quality and relevancy of the data retrieved from the database to respond to a query. The preprocessor in this example splits the data into chunks based on sentence length. Other preprocessing activities include anonymization, deduplication, or toxicity filtering.
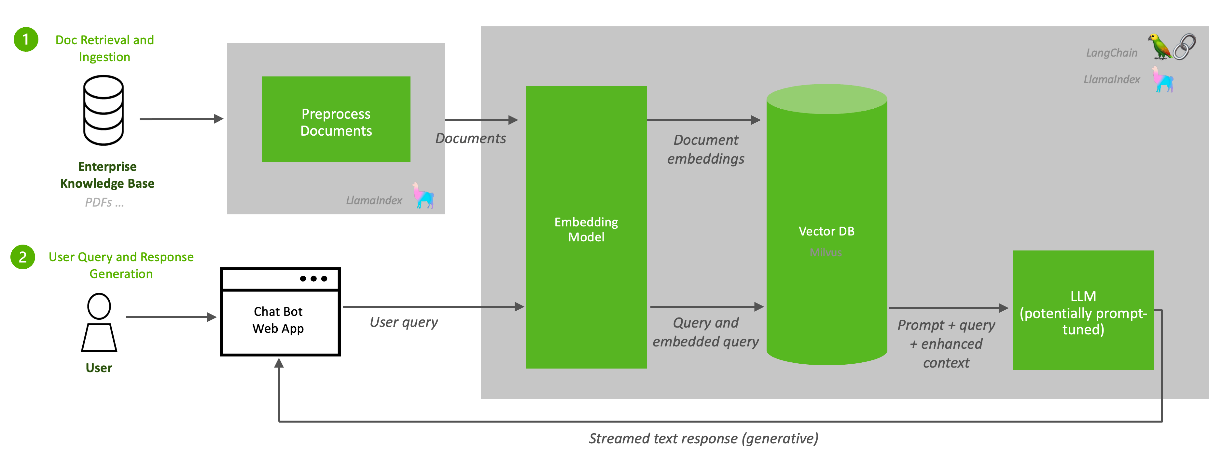 The processed data is then sent to the embedding microservice. Embedding converts data chunks into vector representations that can be efficiently searched and retrieved. This example uses the NV-Embed-QA embedding model, developed by NVIDIA, for efficient, GPU-accelerated document embedding.
The processed data is then sent to the embedding microservice. Embedding converts data chunks into vector representations that can be efficiently searched and retrieved. This example uses the NV-Embed-QA embedding model, developed by NVIDIA, for efficient, GPU-accelerated document embedding.The embeddings are then stored in a vector database for efficient search and retrieval through indexing. Many commercial and open-source vector databases have various cost/performance/reliability tradeoffs. This example pipeline uses PGvector, a vector database implementation of the popular Postgres SQL database. PGvector supports several standard vector search and vector indexing approaches.
The PGvector database deployed in this reference design is backed by Dell PowerScale Network Attached Storage (NAS) for data persistence. The volume is exposed to the PGvector pod as a Kubernetes persistent volume claim from the Isilon storage class.
While PGvector is not GPU accelerated, the reference design supports using several GPU-accelerated vector databases such as Milvus, FAISS, and Redis.
Also note that, although it is not shown in this reference design, RAG administrators should implement a process for regular or continuous data ingestion to keep the database up to date.
Response Generation
Response generation is the RAG function that answers user queries once the pipeline is deployed into production. The Nemo Inference Microservice (NIM) generates the responses through LLM inference. The NIM uses the Llama-2-13b model in this example pipeline to create responses.
Next, the LLM initiates a search and retrieves relevant data from the vector database to enhance its response. In this design, the user query is vectorized using the same NV-Embed-QA model used during the document ingestion phase.
Vectorizing the query with the same embedding model facilitates efficient similarity search of the data embeddings. A critical distinction between RAG and traditional keyword search is that the vector database performs a semantic search to retrieve vectors that most closely resemble the intent of the user's query. The vectors are returned to the LLM as context to enhance the response generation. The LLM generates an answer streamed to the user and citations to the retrieved data chunks.
Although not implemented in this reference design, the pipeline supports prompt tuning to enhance retrievals' accuracy and relevance.