
None
None
-
AI or Solution Software
NVIDIA Enterprise RAG has a modular architecture combining popular open-source LLM programming frameworks like LangChain, LlamaIndex, and Hugging Face with NVIDIA GPU acceleration. This architecture helps enterprises develop and deploy scalable production chatbots quickly and easily without sacrificing open-source innovation.
NVIDIA Cloud Native Stack
A collection of software formerly known as Cloud Native Core, Cloud Native Stack can assist with deploying NVIDIA GPU Operator and has cloud-native workload examples.
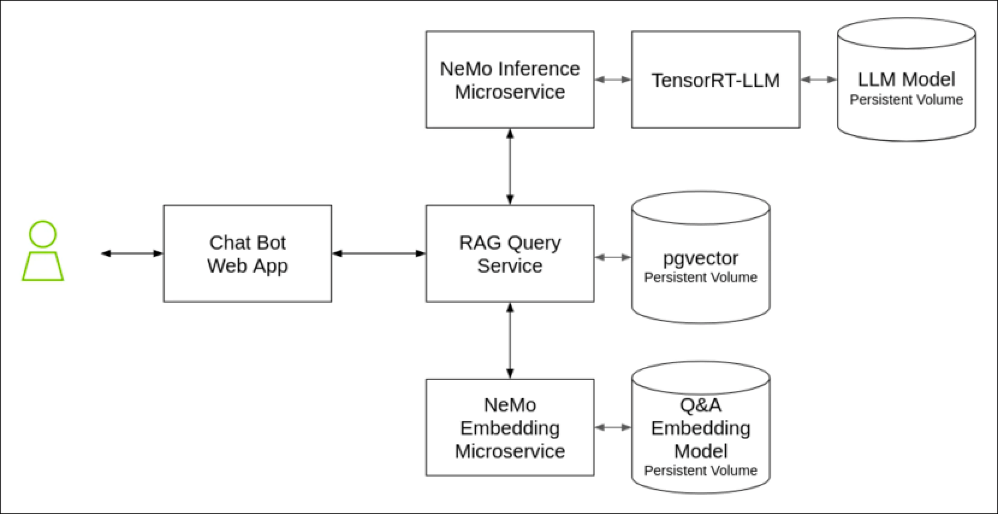 NVIDIA Enterprise RAG Text QA Pipeline Architecture
NVIDIA Enterprise RAG Text QA Pipeline ArchitectureSoftware architecture for the Text QA chatbot RAG pipeline deployed. The NVIDIA RAG LLM Operator also includes sample pipelines for everyday RAG use cases, including Multi-modal QA, Event-driven Agents, Structured Data Processing, and Multi-turn conversation chatbots.
The RAG pipeline includes the following software components:
- Frontend – A sample chatbot web interface implemented in Gradio. It supports text query, document upload, document retrieval, and citation.
- Query router – A sample RAG application implemented as LangChain runnable with LlamaIndex retrieval functions. The query sends API requests to the inference and embedding microservices and is also used for document preprocessing, indexing, and retrieval.
- NVIDIA NeMo LLM Inference microservice (NIM) – built on NVIDIA using TRT-LLM and Triton inference server, NIM delivers best-in-industry performance and scalability for LLM inference. It supports OpenAI-compatible REST APIs for LLM chat and completion. It also supports LLM architectures like Llama, Hugging Face, Gemma, Mistral, and NVIDIA proprietary model formats.
- NeMo Retriever Embedding Microservice (NREM) -- The NeMo Retriever microservices simplify and accelerate the document embedding, retrieval, and querying functions at the heart of a RAG pipeline. This reference design uses the NeMo Embedding microservice to GPU-accelerate vector embedding computations. Future versions of this DRD will incorporate additional NeMo Retriever microservices as they become available.
- PGvector database – PGvector adds vector similarity search to the popular Postgres open-source SQL database. It supports exact and approximate nearest neighbor search, HNSQ, and IVF Flat index types for L2 distance, inner product, and cosine distance vector comparison.
- NVIDIA RAG LLM Operator enables quick and easy deployment of RAG application pipelines into Kubernetes clusters. NVIDIA customers can deploy their pipelines to any on-premises or cloud-based Kubernetes cluster by standardizing RAG pipeline deployment to the Kubernetes operator pattern without modification. This reduces the complexity of life cycle management and enables seamless connection, scaling, and deployment of RAG pipelines without cloud or vendor lock-in.
- NVIDIA API catalog - RAG developers can experience the benefits of GPU acceleration on this NVIDIA-hosted LLM evaluation platform. The API Catalog includes APIs to power every stage of a RAG pipeline that benefits from GPU acceleration. Developers can start developing their RAG applications on the API Catalog and export the required models as NIM containers to deploy them on-premises without rewriting any code.
- Llama-2-13b-chat - The Llama 2 family of LLMs are pretrained and fine-tuned generative text models from Meta. This example uses a 13 billion parameter chat model optimized for dialogue. The model is compiled as a TensorRT engine for efficient inference on NVIDIA GPUs and easy integration with the NVIDIA Triton inference server to support multi-GPU tensor and pipeline parallelism.
Prerequisites
This reference design was tested on the following hardware and software:
Component
Version
NVIDIA GPUs
H100, L40S, A100-80
NVIDIA GPU driver
535.129.03
Operating System
Ubuntu Linux 22.04
Kubernetes
1.26-1.28
Container runtime
contained 1.6, 1.7
Ubuntu
22
Server
R760xa
Storage
PowerScale F710 OneFS 9.7
Network
PowerSwitch Z9664F-ON/S5248F-ON
Dell CSI PowerScale Driver
2.9.1