
Advanced settings
Advanced settings
-
SyncIQ Advanced Settings provide several options to configure a SyncIQ policy, as displayed in the following figure.
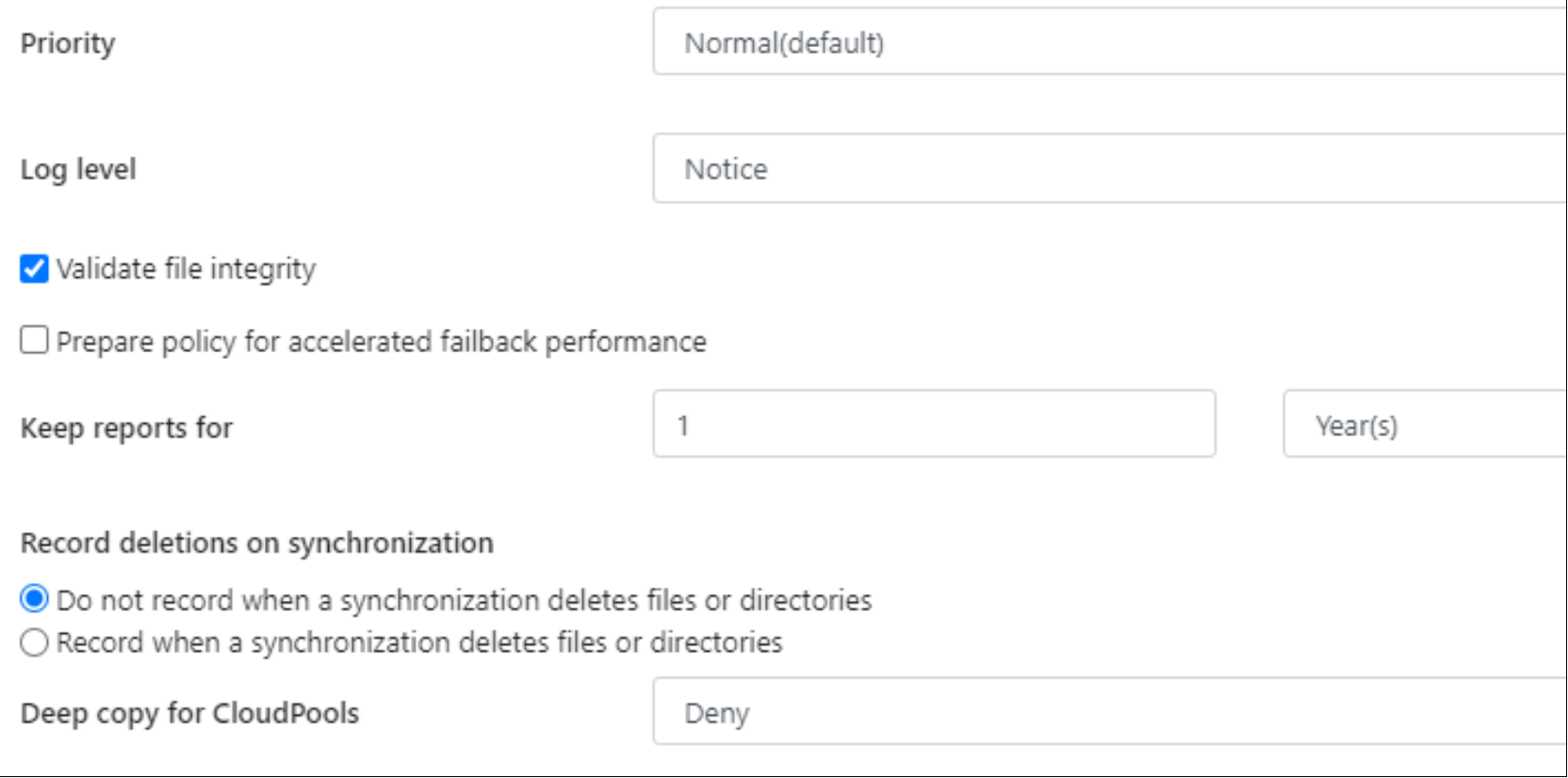
Figure 23. SyncIQ Policy Advanced Settings
Priority
From the Priority drop-down, as displayed in Figure 23, select a priority level for the SyncIQ policy. PowerScale SyncIQ provides a mechanism to prioritize particular policies. Policies can optionally have a priority setting – policies with the priority bit set will start before unprioritized policies. If the maximum number of jobs are running, and a prioritized job is queued, the shortest running unprioritized job will be paused by the system to allow the prioritized job to run. The paused job will then be started next.
Alternatively, to set the priority bit for a job from the CLI, use --priority 1 on the isi sync policies create or modify command, which maps to High in the web interface. The default is 0, which is unprioritized, which maps to Normal in the web interface.
Log Level
From the Log Level drop-down, as displayed in Figure 23, specify a level of logging for this SyncIQ policy. The log level may be modified as required during a specific event.
SyncIQ logs provide detailed job information. To access the logs, connect to a node and view its /var/log/isi_migrate.log file. The output detail depends on the log level, with the minimal option being Fatal and the maximum logging option being Trace.
Note: Notice is the default log level and is recommended for most SyncIQ deployments. It logs job-level and process-level activity, including job starts and stops, as well as worker coordination information. Debug and Trace options should only be used temporarily as they create a significant number of logs.
Validate file integrity
The Validate File Integrity checkbox, as displayed in Figure 23, provides an option for OneFS to compare checksums on SyncIQ file data packets pertaining to the policy. In the event a checksum value does not match, OneFS attempts to transmit the data packet again.
Prepare policy for accelerated failback performance
The checkbox Prepare policy for accelerated failback performance (Figure 23) enables you to expedite failback to the source cluster after the failover to the target cluster. For more information, see Failover and failback.
The failback to the source cluster is accelerated when you run the DomainMark job in advance of the actual failback. The checkbox Prepare policy for accelerated failback performance prepares the source cluster for failback under normal operation, before a failback, by allowing the DomainMark job to run the next time the policy runs. Alternatively, from the CLI, set the --accelerated-failback true flag to enable accelerated failback.
After you complete a failover to the target cluster and new data is written to the target cluster, a failback to the source cluster requires a resync-prep action to accept the intervening changes from the target cluster. The resync-prep action requires the original source cluster to temporarily function as a target cluster, where the original target cluster is now writing data to the original source cluster. During this process, before the original target cluster can write data to the original source cluster, is when the DomainMark job must run on the original source cluster. However, by selecting the checkbox Prepare policy for accelerated failback performance, the DomainMark job ran before the failback, minimizing the failback duration.
Conversely, if you do not select this checkbox, the failback process consumes more time because the DomainMark job runs during the failback rather than in advance.
Alternatively, to manually run the DomainMark job, rather than the next time the policy runs, use the following command:
isi job start DomainMark --root=<path> --dm-type=synciq
Note: As a best practice, select the checkbox Prepare policy for accelerated failback performance during the initial policy configuration. This action minimizes downtime during an actual outage where time is of the essence. If an existing policy does not have this checkbox selected, you may select it retroactively. Otherwise, to avoid extending the failback time, you must run the above manual CLI command before the first failover.
After you select the checkbox, the DomainMark job runs only once for the policy. Depending on the policy and dataset, it can take several hours or more to complete. When you select the checkbox, it does not require any further configuration, irrespective of the failover duration and how the dataset on the target cluster has changed.
Note: Selecting the checkbox Prepare policy for accelerated failback performance increases the overall runtime of the next sync job. After that sync, SyncIQ performance is not affected.
Hard links and DomainMark
If a policy contains hard links outside of the policy's base path, the DomainMark job fails on the source cluster. The failure may occur during a failback to the source cluster, or the next time a policy runs after you have selected the checkbox Prepare policy for accelerated failback performance.
Note: As a best practice, ensure the source cluster base path does not contain hard links outside of the base path. Otherwise, the DomainMark job fails, and then the failback to the source cluster fails.
For more information about hard links and SyncIQ, see Hard links and SyncIQ.
Keep reports duration
The Keep Reports option, as displayed in Figure 23, defines how long replication reports are retained in OneFS. When the defined time has exceeded, reports are deleted.
Record deletions on synchronization
Depending on the IT administration requirements, a record of deleted files or directories on the target cluster may be required. By default, OneFS does not record when files or directories are deleted on the target cluster. However, the Record Deletions on Synchronization option, as displayed in Figure 23, can be enabled if it is required.
Deep copy for CloudPools
PowerScale clusters that are using CloudPools to tier data to a cloud provider have a stub file, known as a SmartLink. The file is retained on the cluster with the relevant metadata for retrieval of the file at a later time. Without the SmartLink, a file that is tiered to the cloud, cannot be retrieved. If a SmartLink is replicated to a target cluster, the target cluster must have CloudPools active with the same configuration as the source cluster, to be able to retrieve files tiered to the cloud. For more information about SyncIQ and CloudPools, see SyncIQ and CloudPools.
Deep Copy is a process that retrieves all data that is tiered to a cloud provider on the source cluster, allowing all the data to be replicated to the target cluster. Depending on if the target cluster has the same CloudPools configuration as the source cluster, Deep Copy could be required. However, in certain workflows, Deep Copy may not be required, as the SmartLink file allows for the retrieval of files tiered to the cloud.
The Deep copy for CloudPools drop-down, as displayed in Figure 23, provides the following options:
- Deny: This setting, which is the default, allows only the SmartLinks to be replicated from the source to the target cluster, assuming the target cluster has the same CloudPools configuration.
- Allow: This option also replicates the SmartLinks from the source to the target cluster. However, this option also checks the SmartLinks versions on both clusters. If a mismatch is found between the versions, the complete file is retrieved from the cloud on the source, and then replicated to the target cluster.
- Force: This option requires CloudPools to retrieve the complete file from the cloud provider on to the source cluster and replicates the complete file to the target cluster.
Note: Deep Copy takes significantly more time and system resources when enabled. It is recommended that Deep Copy only be enabled if it is required for a specific workflow requirement.