
Use case 2: Data preparation for analytics
Use case 2: Data preparation for analytics
-
In this use case, we describe preparing the data for performing data analytics.
Parquet
Parquet is an Apache open-source column-oriented datafile format that is designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Parquet is designed to be a common interchange format for both batch and interactive workloads.
OPENROWSET
OPENROWSET is a lightweight function that allows SQL engine to access data outside SQL Server, either a file or another database.
The OPENROWSET function can be referenced in the FROM clause of a query as if it were a table name. The OPENROWSET function can also be referenced as the target table of an INSERT, UPDATE, or DELETE statement.
We can use OPENROWSET to validate that the data located in Dell ObjectScale is reachable.
SQL Server 2022 T-SQL enables the conversion of a .csv file into Parquet file format by using Create External Table as Select (CETAS) with OPENROWSET syntax. This is a powerful option to join relational data in SQL and non-relational data on object storage, such as Dell ECS. CETAS can also be used to create external datasets directly, without ever landing within SQL, directly to a parquet file format.
The following example shows how to create an external table using OPENROWSET and CETAS and converting .csv files to parquet files.
Query description: The following query converts wind_speed table in .csv file format to parquet file format and stored in specified location in Delta Lake.
CREATE EXTERNAL TABLE ext_wind_speed
WITH
(
LOCATION = '/demo/tpcds/sf1/delta/customer_demographics/wind-Speed.parquet',
DATA_SOURCE = s3_ds,
FILE_FORMAT = ParquetFileFormat
) AS
SELECT City
FROM (
SELECT *
FROM OPENROWSET
(
BULK '/weatherdata/weather/csv/wind_speed.csv',
FORMAT = 'CSV',
DATA_SOURCE = 's3_ds'
,
FIRSTROW=2
)
WITH ( [datetime] datetime, Vancouver float, Portland float, [San_Francisco] float, Seattle float,[Los_Angeles] float, [San_Diego] float, [Las_Vegas] float, Phoenix float, Albuquerque float, Denver float, [San_Antonio] float, Dallas float, Houston float, [Kansas_City] float, Minneapolis float, [Saint_Louis] float, Chicago float, Nashville float, Indianapolis float, Atlanta float, Detroit float, Jacksonville float, Charlotte float, Miami float, Pittsburgh float, Toronto float, Philadelphia float,[New_York] float, Montreal float, Boston float, Beersheba float, [Tel_Aviv_District] float, Eilat float, Haifa float, Nahariyya float, Jerusalem float )
AS Test1
) AS A;
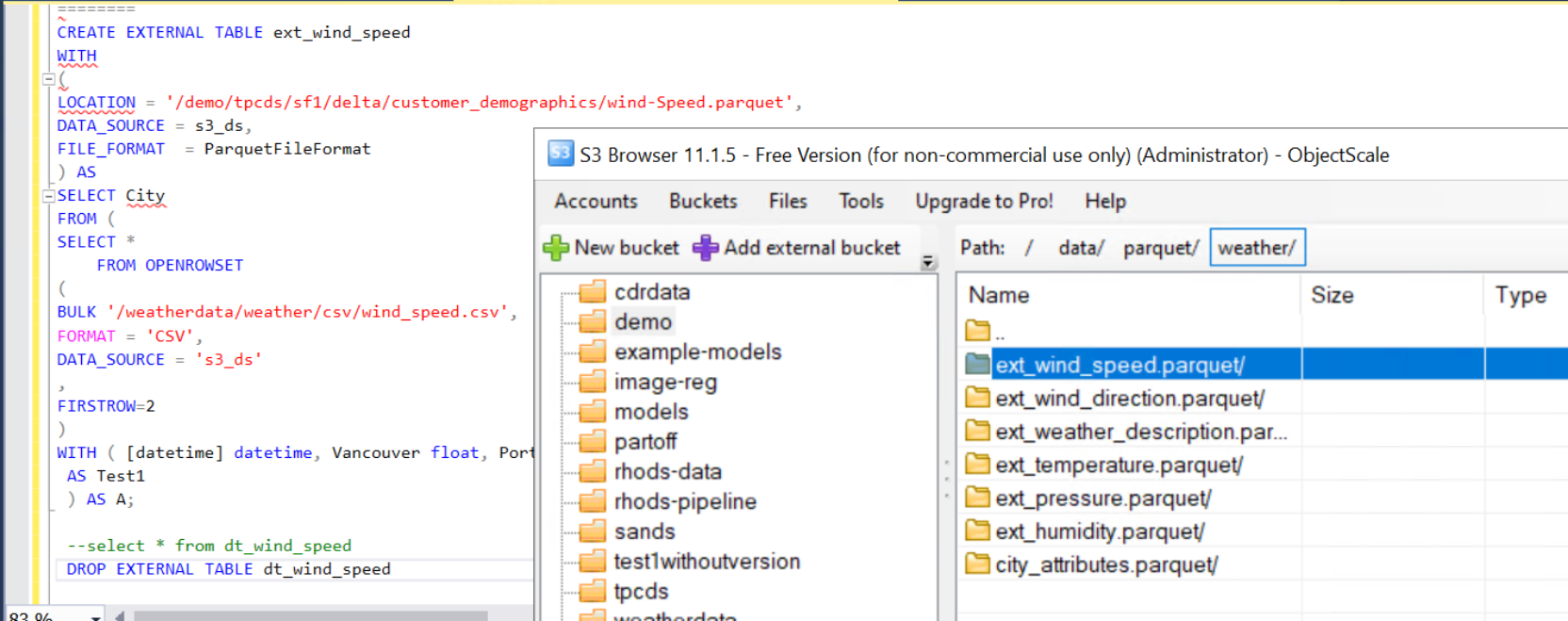
Figure 23. External table ext_wind_speed backed by parquet file.
PySpark
We can also use PySpark to convert files from one format to another. In our case, we will be using PySpark to convert .csv file formats directly to delta file format and Parquet file formats to delta file format.
./bin/pyspark --packages io.delta:delta-core_2.12:1.1.0,org.apache.hadoop:hadoop-aws:3.2.3 \
--conf spark. delta.logStore.class=org.apache.spark.sql.delta.storage.S3SingleDriverLogStore \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql. catalog. spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" \
--conf spark.hadoop.fs.s3a.endpoint=https://10.**.**.** \
--conf spark.hadoop.fs.s3a.access.key=************** \
--conf spark.hadoop.fs.s3a.secret.key=********************************* \
--conf spark.hadoop.fs.s3a.path. style.access=true \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider
Import Required Packages:
import sys
import pyspark
from delta import *
from pyspark.sql import functions as F
from pyspark.sql.functions import udf, concat, col, lit
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import IntegerType, ArrayType
from pyspark.sql.types import StringType, DoubleType
from pyspark.sql.types import DateType, TimestampType
#Read data in Parquet format and Write data in to Delta Format
df1=spark.read.format('parquet').option('header', False).load("s3a://weatherdata/weather/parquet/city_attributes.parquet/")
df1.write.mode('overwrite').format('delta').save("s3a://weatherdata/weather/delta/city_attributes")
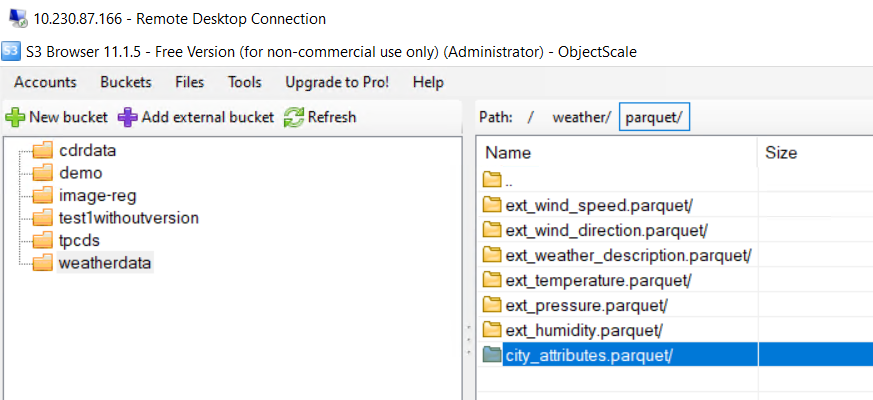
Figure 24. Result of city_attributes file created in S3 browser view
Conversion process for CSV to Delta Format, using PySpark
- Define a schema based on the datafile, as shown in the following sample script:

2. After the schema is created, we can load the data into PySpark data frame as shown in the following script:

3. Save this data frame as Delta Lake format on ObjectScale bucket, as shown in the following script:

4. Verify the data in Delta Lake format by using S3 Browser.
Figure 25. S3 browser bucket view