
Solution Validation
Solution Validation
-
Now that the necessary infrastructure is in place, proceed through all the steps required to install DBT and commence building data pipelines.
Dbt-trino adapter
The dbt-trino adapter utilizes DDAE powered Starburst Trino as its underlying query engine for performing query federation across various data sources. DDAE connects to multiple and diverse data sources through a single dbt connection, executing SQL queries. Transformations specified in dbt are transmitted to DDAE, which processes these SQL transformation queries, translates them to read data, creates tables or views, and manipulates data within the connected data sources.
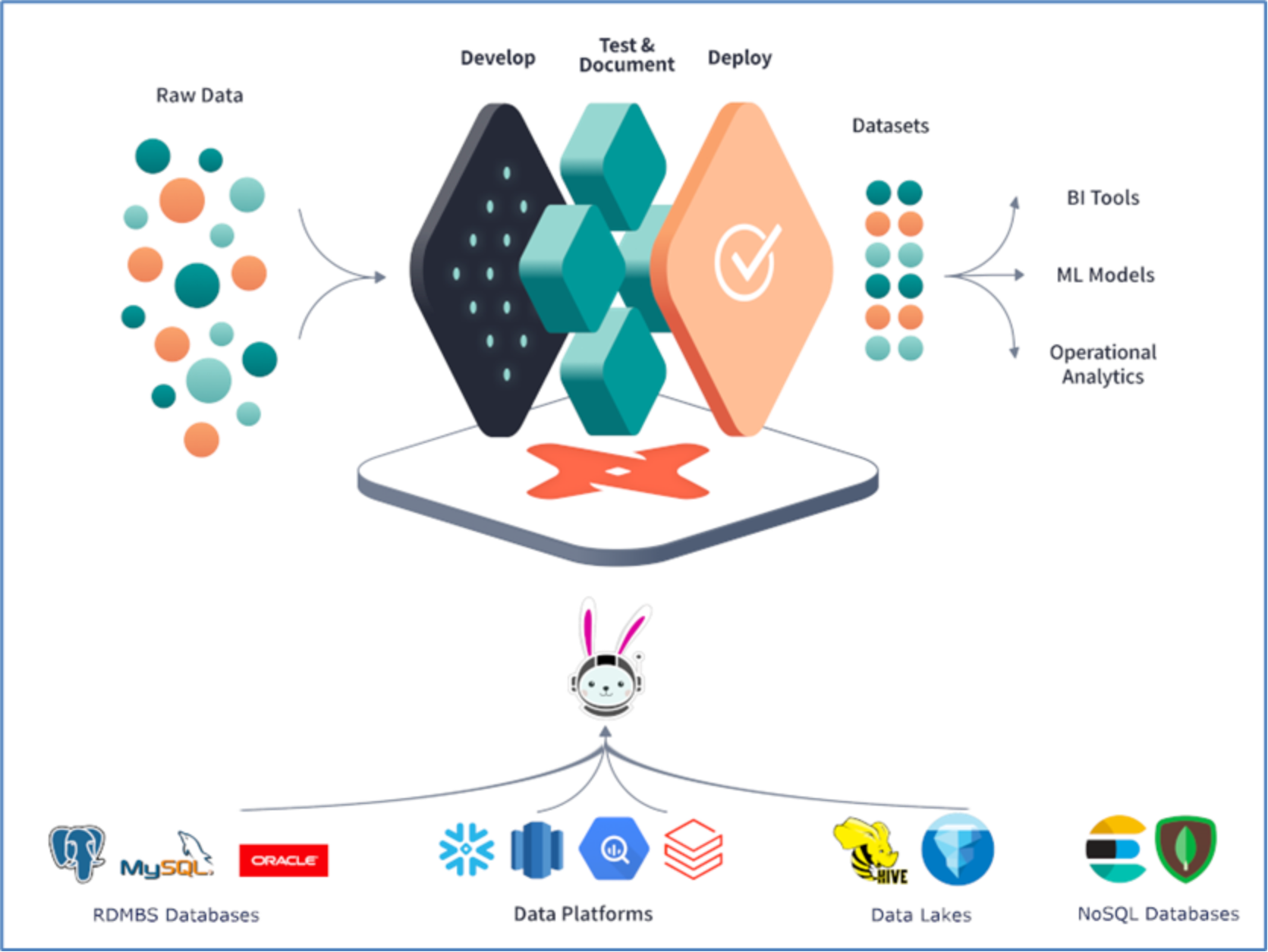
Figure 16. Dbt-trino adapter
Installing dbt and bootstrapping your project
To install dbt, execute "pip install dbt-trino". Ensure that you have Python 3.7+ installed. After installation, verify by running "dbt --version". You should see an output similar to the following:
Core:
- installed: 1.3.0
- latest: 1.3.0 - Up to date!
Plugins:
- trino: 1.3.1 - Up to date!
To bootstrap the dbt project, execute "dbt init". Even if you've cloned or downloaded an existing dbt project, this command helps set up your connection profile for quick start. It prompts for connection information and adds a profile to your local profiles.yml file, creating it if necessary. More about configuring profiles is available from the official dbt documentation.
my_dbt_trino_project:
target: dev
outputs:
dev:
type: trino
method: none
user: admin
database: datalake
host: ddae_host_fqdn
port: 8080
schema: analytics
threads: 1
All profiles.yml configuration options specific to dbt-trino can be found on the dbt-trino GitHub repository.
First model
The fundamental building block of dbt is a model, which is a SQL file within your project's models folder containing a SELECT query. The results of this query materialize in your database as a VIEW or TABLE. For instance, to select all customers from your webshop database, create a src_customers.sql file in your models.
SELECT * FROM webshop.public.customers
When you execute "dbt run", dbt persists a table onto the datalake.analytics schema called src_customers. Running "dbt run" again replaces the existing view with a potential new definition if you change the query. Validate the results of your model by running this query in your favorite database client.
SELECT * FROM datalake.analytics.src_customers;
Adding your data sources
As evident above, directly sourcing from the operational PostgreSQL database is not recommended. To address this, you should define a dbt source. Sources specify all external objects required by your project.
To rectify this issue, add a new sources.yml file in your models folder with the following content:
version: 2
sources:
- name: webshop
database: webshop
schema: public
tables:
- name: customers
In the src_customers.sql file, you can now reference this source instead of the previously hard-coded location. This approach saves us from needing to update these locations everywhere if they change or if you wish to fetch them from a test database instead of the production database. Adding the prefix "src" helps to quickly identify which models are built directly from sources.
SELECT * FROM {{ source('webshop', 'customers') }}
Note: the double curly braces {{ ... }}, which signify that the code fragment within is evaluated by dbt before sending the query to your Trino instance. The source macro or function takes the database and schema from the first argument called source_name, and the name of the object from the second argument called table_name. The end result, which is the compiled query, remains the same as the query above without the source macro.
Adding EL to the T of dbt
Traditionally, dbt is primarily used for database transformations, hence its name as a data transformation tool. It typically leaves the extract and load (EL) tasks to Apache Airflow we have setup and created a DAG for the same. However, with the data federation capabilities of DDAE, the EL tasks can now be seamlessly integrated with the T (Transform) capabilities of dbt. This means that any data can be added as if it were located within the same database, provided there is a DDAE connector for it. This includes relational or NoSQL databases, message queues, or APIs, all readily available without the need for expensive and complicated extract and load processes.
Already, a table has been loaded directly from our PostgreSQL database into the datalake without requiring additional tools. Now, let's add another source: the clickstream data. For instance, imagine wanting to track how many times a customer has visited our website before making a purchasing decision. Our clickstream data is readily accessible under the website catalog.
To begin, add a new source named "website" to the sources.yml file:
version: 2
sources:
- name: webshop
...
- name: website
database: website
schema: clickstream
tables:
- name: clicks
Create a model file src_clicks.sql under the models folder:
with source as (
SELECT * FROM {{ source('website', 'clicks') }}
),
renamed as (
SELECT
visitorid,
useragent,
language,
event,
cast(from_iso8601_timestamp(eventtime) AS timestamp(6) with time zone) AS eventtime,
page,
referrer
FROM source
)
SELECT * FROM renamed
Execute dbt run again to materialize a newly created view.
dbt implicitly builds your DAG
A crucial concept in data pipelines is a DAG (Directed Acyclic Graph), which defines all the steps the pipeline must perform from source to target. Each step of a DAG executes its task once all its parents have completed, triggering the start of its direct children (the dependents).
While many tools, like Apache Airflow, take an explicit approach to constructing DAGs, dbt constructs the DAG implicitly. Each step of the DAG is represented by a simple SQL file (referred to as a model in dbt), and you can reference other models using the "ref" macro, for example, {{ ref('src_customers') }}.
Consider a scenario where you want to determine how many times each customer visits the website before making a purchase decision. To achieve this, you need to join your webshop data with the clickstream data. However, clickstream data is often large and challenging to analyze. For instance, users may research products before registering or logging into the webshop.
To address this, you can introduce the concept of sessionization to associate sessions with actual users. Each website visitor receives a unique identifier stored in a long-lasting cookie, and you have a sessions table in the webshop linking this identifier to an actual user. With this data, you can identify clicks performed prior to logging into the webshop.
Below, you can observe the lineage DAG of models generated by dbt, illustrating the relationships between various data transformation steps.
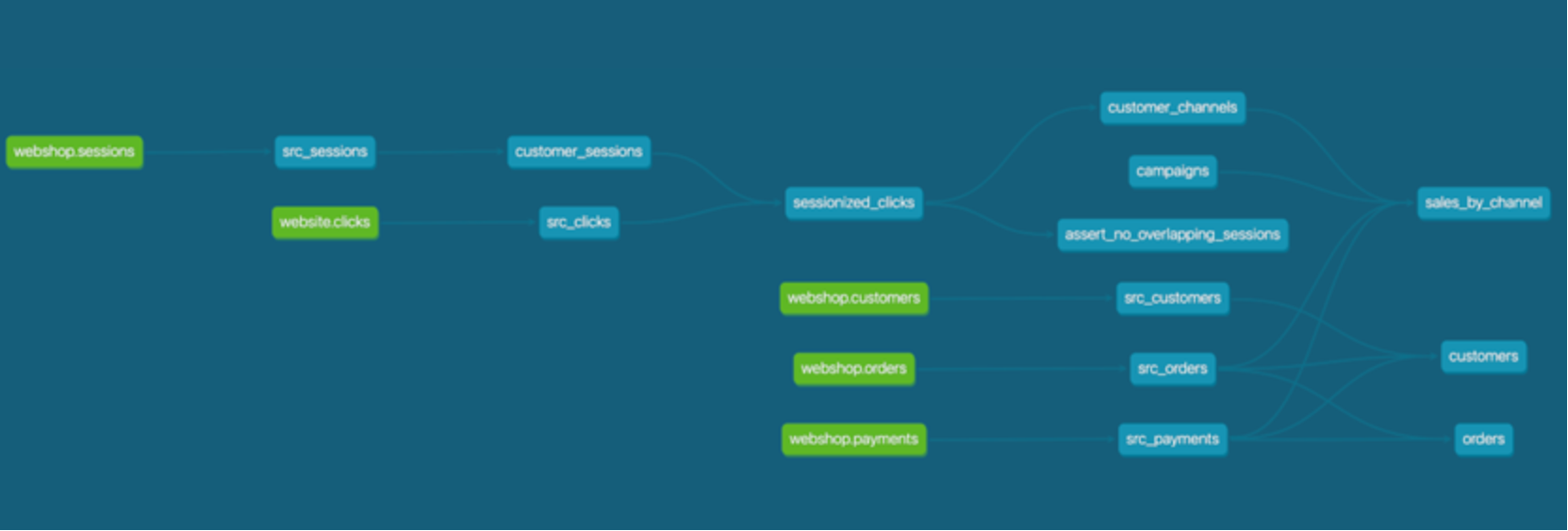
Figure 17. DBT generated DAG
First you need to add the sessions table to our sources:
version: 2
sources:
- name: webshop
database: webshop
schema: public
tables:
- name: customers
- name: sessions
Again, you add a simple model called src_sessions.sql that is just performing a select on our source:
with source as (
SELECT * FROM {{ source('webshop', 'sessions') }}
),
renamed as (
SELECT
cookie_id,
cast(from_unixtime(started_ts/1000) AS timestamp(6)) AS session_started,
customer_id
FROM source
)
SELECT * FROM renamed
Let's begin by creating a new model named sessionized_clicks.sql. First, let's establish some rules regarding our sessionization:
- A session is defined as a sequence of clicks, where no two consecutive clicks are more than one hour apart.
- Once a user logs in, past sessions are associated with the user.
Trino supports a wide range of SQL functions and advanced operators that can be utilized in dbt models. The query used in the following model incorporates some of Trino's more sophisticated features. Although complex, these features are essential and beneficial in the hands of a data engineer.
One such feature used to implement sessions is WINDOW operations. The WINDOW clause enables you to analyze a subset of rows related to the current row within a query result set. It's different from a GROUP BY clause as it doesn't reduce the number of rows but instead allows you to perform aggregate or analytic calculations on subsets of rows.
Additionally, the model utilizes a macro called "star". This macro generates a comma-separated list of all fields existing in the "from" relation, excluding any fields listed in the "except" argument. This construction is identical to "SELECT * FROM
{{ ref('my_model') }}", replacing "star (*)" with the "star" macro:
WITH sessions AS (
SELECT
date_diff('hour', lag(c.eventtime) OVER w, c.eventtime) > 1 AS new_session,
{{ dbt_utils.star(ref("src_clicks"), "c") }},
{{ dbt_utils.star(ref("customer_sessions"), "s", ["session_started", "session_ended"]) }},
first_value(c.referrer) ignore nulls OVER (PARTITION BY s.customer_id ORDER BY c.eventtime ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS channel,
row_number() OVER w AS clickid,
min(eventtime) OVER w AS session_started,
max(eventtime) OVER w AS session_ended
FROM {{ ref("src_clicks") }} c
JOIN {{ ref("customer_sessions") }} s ON c.visitorid = s.cookie_id AND c.eventtime BETWEEN s.session_started AND s.session_ended
WINDOW w AS (
PARTITION BY c.visitorid ORDER BY c.eventtime
)
),
sequenced_sessions AS (
SELECT
{{ dbt_utils.star(ref("src_clicks")) }},
sum(if(new_session, 1, 0)) OVER w AS session_sequence,
clickid,
customer_id,
session_started,
session_ended,
channel
FROM sessions
WINDOW w AS (
PARTITION BY visitorid ORDER BY eventtime
)
)
SELECT
visitorid || '_' || cast(session_sequence as varchar) || '_' || cast(clickid as varchar) AS clickid,
visitorid || '_' || cast(session_sequence as varchar) AS sessionid,
customer_id,
session_started,
session_ended,
channel,
{{ dbt_utils.star(ref("src_clicks")) }}
FROM sequenced_sessions
Materializations (view, table, ephemeral)
To optimize the performance of your data pipeline, it's crucial to make informed decisions about whether models should be materialized as views, tables, or simply reused within existing SQL statements.
As a general rule, it's advisable to create tables for all data exposed to end users, such as dashboards.
In the case of sessionization, where a window operation is used to add a session_id to each click, you don't want this computationally expensive operation to be performed every time you utilize the sessionized_clicks object. Therefore, it should be persisted as a table rather than a view.
To achieve this, simply modify the sessionized_clicks.sql model and add a configuration at the top:
{{ config(materialized='table') }}
When you execute "dbt run", dbt persists this model as a table by encapsulating your query within a "CREATE TABLE sessionized_clicks AS ..." statement.
Ephemeral models, on the other hand, are not directly constructed in the database. Instead, dbt interpolates the code from this model into dependent models as a common table expression.
Is our sessionization logic correct
To ensure the correctness of our sessionization logic, dbt simplifies the process of adding data tests. Suppose we want to verify the accuracy of our logic. In that case, we can utilize generic tests like "unique" and "not_null" defined in schema.yml. These tests evaluate whether values in a specified column are unique or not null.
Common errors encountered during sessionization logic development include inadvertent mistakes leading to overlapping sessions, which should always be avoided.
To validate this, we can add a dbt test. After adjusting our model, we can easily execute the test to assess the logic's correctness.
To implement this, create assert_no_overlapping_sessions.sql in the tests folder with the following SQL query:
SELECT
sc1.session_started,
sc1.session_ended,
sc1.session_ended,
sc2.session_started,
sc1.visitorid,
sc2.visitorid
FROM {{ ref('sessionized_clicks') }} sc1
JOIN {{ ref('sessionized_clicks') }} sc2
ON sc1.session_started > sc2.session_ended
AND sc1.session_ended < sc2.session_started
AND sc1.visitorid = sc2.visitorid
Now, you can execute "dbt test --select sessionized_clicks" to test and validate the model.
Dbt macros
dbt offers a powerful feature called macros, which allows for the creation and reuse of common functionalities across dbt projects. The well-maintained package dbt-utils contains macros that can be reused across dbt projects.
Starburst maintains dbt-trino-utils, a package containing macros specifically designed for projects running on Trino or Starburst databases. These macros include implementations of dispatched macros from other packages that can be used on Trino or Starburst databases.
To use dbt-utils or trino-utils, both packages must be defined in the packages.yml file:
packages:
- package: dbt-labs/dbt_utils
version: {SEE DBT HUB FOR NEWEST VERSION}
- package: starburstdata/trino_utils
version: {SEE DBT HUB FOR NEWEST VERSION}
Next, instruct the supported package to also search for trino-utils macros by adding the relevant dispatches to your dbt_project.yml:
dispatch:
- macro_namespace: dbt_utils
search_order: ['trino_utils', 'dbt_utils']
Once the packages are defined, run "dbt deps", which pulls the packages specified in packages.yml.
A sample use case might involve dropping and cleaning databases from objects no longer in use. To accomplish this, simply run:
dbt run-operation trino__drop_old_relations
To preview the cleaning results, add "--args "{dry_run: true}" at the end of the command above.
DBT seed: To add static data
dbt offers the ability to insert the content of CSV files, referred to as seeds in dbt, directly into a table using the dbt seed command. This feature is particularly handy when you need to maintain a list of mappings or values within your project.
For instance, suppose you have a list consisting of campaigns, countries, and age groups, where the columns campaign_id identifies the campaign, country denotes where the campaign was run, and age_group represents the target group for the campaign. You can create a CSV file named campaigns.csv and place it into the seeds folder with the following content:
```
campaign_id,country,age_group
1,US,"18-24"
2,Europe,"18-24"
3,US,"25-40"
4,Europe,"25-40"
5,US,"41-60"
```
After executing the dbt seed command, you can reference the seed in your models using the familiar syntax: {{ ref("campaigns") }}.
Now, it's time to enhance efficiency further with incremental refreshing.
Incremental models
To expedite data refreshing, you can leverage incremental models, which streamline the amount of data loaded into the target table, significantly reducing loading time. When an incremental model is initially executed, the table is created by transforming all rows from the source. Subsequently, dbt only transforms the rows specified by your model's filter criteria, inserting them into the target table. Incremental models offer notable performance improvements and reduced compute costs.
To implement incremental models, simply add "materialized='incremental'" to your model configuration:
{{
config(
materialized='incremental',
unique_key='id'
)
}}
The "unique_key" parameter determines whether a record has new values and should be updated. By specifying a unique_key, you ensure that each row from the source table is represented by a single row in your incremental model, eliminating duplicates. Failure to specify a unique_key results in append-only behavior, where dbt inserts all rows returned by the model's SQL into the preexisting target table without regard for duplicates.
In scenarios where multiple columns are needed to uniquely identify each row, you can provide these columns as a list, similar to "unique_key = ['id', 'user_id']".
Reduce data for processing.
To instruct dbt on which rows to transform during an incremental run, encapsulate valid SQL filtering for these rows within the is_incremental() macro. This filter is exclusively applied during subsequent incremental runs.
Include this macro in the model configuration:
SELECT * FROM ...
{% if is_incremental() %}
WHERE eventtime > (SELECT max(eventtime) FROM {{ this }})
{% endif %}
This setup ensures that dbt processes only the relevant rows specified by the filtering condition when executing an incremental run.
Incremental strategies
The dbt-trino adapter offers multiple incremental strategies to dictate how data is loaded into the target table. Different strategies may vary in effectiveness depending on factors such as data volume, unique key reliability, or available features.
The following incremental strategies are supported by dbt-trino:
1. Append (default): The default strategy, append, adds only new records based on the condition specified in the is_incremental() block. It can be configured without a unique_key since it solely inserts data into the target table.
{{
config(
materialized = 'incremental'
)
}}
SELECT * FROM ...
2. Delete+Insert: The delete+insert strategy involves a two-step approach. It first deletes records identified through the configured is_incremental() block before re-inserting them.
{{
config(
materialized = 'incremental',
unique_key='user_id',
incremental_strategy='delete+insert',
)
}}
SELECT * FROM ...
3. Merge: The merge strategy constructs a MERGE statement, enabling dbt-trino to insert new records and update existing ones based on the unique key.
Note: that some Trino connectors may have limited or no support for MERGE.
{{
config(
materialized = 'incremental',
unique_key='user_id',
incremental_strategy='merge',
)
}}
SELECT * FROM ...
Refresh data faster
To accelerate data refreshes on your lakehouse, leverage the incremental models as described below:
First, load the clicks data into the src_clicks view in the data lake with an append incremental strategy. Configure the model as follows:
{{
config(
materialized='incremental'
)
}}
with source as (
SELECT * FROM {{ source('website', 'clicks') }}
),
renamed as (
SELECT
visitorid,
useragent,
language,
event,
cast(from_iso8601_timestamp(eventtime) as timestamp(6) with time zone) AS eventtime,
page,
referrer
FROM source
)
SELECT * FROM renamed
{% if is_incremental() %}
-- this filter is only applied on an incremental run
WHERE eventtime > (SELECT max(eventtime) FROM {{ this }})
{% endif %}
Next, create a customer_sessions table, which calculates when a particular session has started and ended:
SELECT
cookie_id,
last_value(customer_id) IGNORE NULLS OVER (
PARTITION BY cookie_id ORDER BY session_started ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS customer_id,
session_started,
lead(session_started, 1, current_timestamp(6)) OVER (PARTITION BY cookie_id ORDER BY session_started asc) AS session_ended
FROM {{ ref("src_sessions") }}
Since sessionization can affect older sessions, utilize the MERGE incremental strategy to update existing records, and insert only new records into the sessionized_clicks table based on the clickid column:
{{
config(
materialized='incremental',
unique_key="clickid",
incremental_strategy='merge',
)
}}
with sessions as (
SELECT
date_diff('hour', lag(c.eventtime) OVER w, c.eventtime) > 1 AS new_session,
{{ dbt_utils.star(ref("src_clicks"), "c") }},
{{ dbt_utils.star(ref("customer_sessions"), "s", ["session_started", "session_ended"]) }},
first_value(c.referrer) IGNORE NULLS OVER (PARTITION BY s.customer_id ORDER BY c.eventtime ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS channel,
row_number() OVER w AS clickid,
min(eventtime) OVER w AS session_started,
max(eventtime) OVER w AS session_ended
FROM {{ ref("src_clicks") }} c
JOIN {{ ref("customer_sessions") }} s ON c.visitorid = s.cookie_id
AND c.eventtime between s.session_started
AND s.session_ended
window w AS (
PARTITION BY c.visitorid ORDER BY c.eventtime
)
),
sequenced_sessions as (
SELECT
{{ dbt_utils.star(ref("src_clicks")) }},
sum(if(new_session, 1, 0)) OVER w AS session_sequence,
clickid,
customer_id,
session_started,
session_ended,
channel
FROM sessions
WINDOW w AS (
PARTITION BY visitorid
ORDER BY eventtime
)
)
SELECT
visitorid || '_' || cast(session_sequence as varchar) || '_' || cast(clickid as varchar) AS clickid,
visitorid || '_' || cast(session_sequence as varchar) AS sessionid,
customer_id,
session_started,
session_ended,
channel,
{{ dbt_utils.star(ref("src_clicks")) }}
FROM sequenced_sessions
By implementing these incremental strategies, you can significantly enhance the efficiency of your data pipeline refreshes on the lakehouse.
In our validation process, we emphasized the utilization of DBT for constructing the DAG (Directed Acyclic Graph) to handle ELT (Extract, Load, Transform) tasks, although Airflow could have been equally viable. While Airflow offers versatility for ETL (Extract, Transform, Load) and various other tasks, DBT efficiently addressed the structured data analytics requirements. However, this doesn't preclude the option of leveraging Airflow for complementary functionalities.
Apache Airflow
DBT Core
Recommended Usage
Data workflow orchestration
Data transformation, documentation, data quality, data lineage
Primary Strength
Orchestration of data pipelines
Data modeling and transformation
Development Language
Python or YAML using DagFactory
SQL and Python in some warehouses
Ease of Use
Python knowledge required. Deployment is simpler if using a managed platform, but increases in complexity if self deploying and managing
SQL based transformation reduces the learning curve for using dbt. But setting up and managing the dbt infrastructure manually can be challenging as the organization grows.