
Setup Apache Iceberg Catalog
Setup Apache Iceberg Catalog
-
Configure Iceberg Catalog to store Iceberg Open tables on the Dell ECS Object Storage of the Dell Data lakehouse. Start by loging into Dell Data Lakehouse system software UI. Then, under Catalogs, Connect Catalog, Click +Add, Type è Iceberg and provide the configuration parameters.
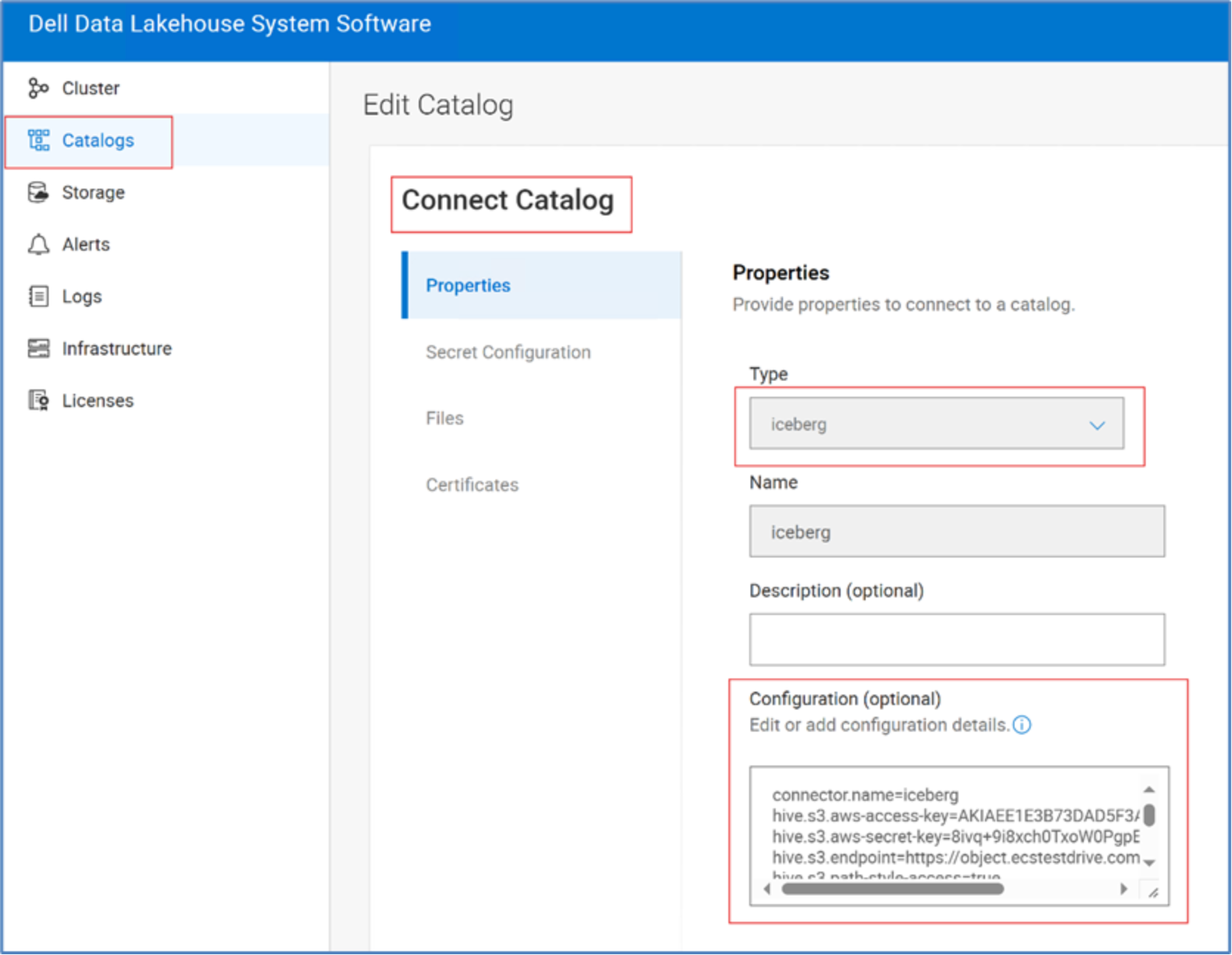
Figure 7. Add Iceberg Catalog
Setup PostgreSQL Catalog
Configure PostgreSQL Catalog to connect DDAE and perform federated querying of the Wedshop dataset hosted on the Postgres database. For that login into Dell Data Lakehouse system software UI, under Catalogs, Connect Catalog, Click +Add, Type è Postgres and provide the configuration parameters.
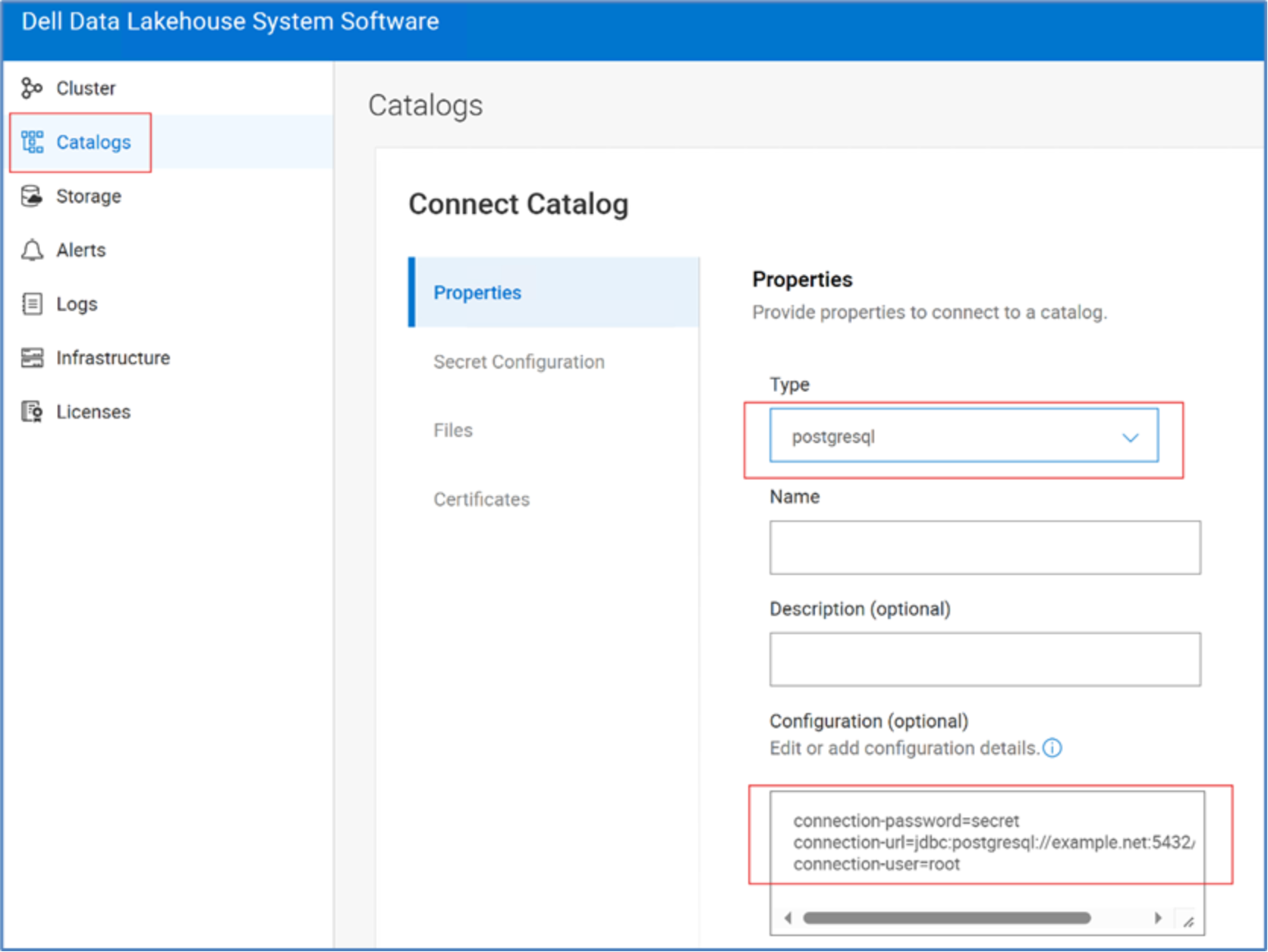
Figure 8. Connect Catalog with Dell Data Lakehouse
Setup MongoDB Catalog
Configure MongoDB Catalog to connect DDAE and perform federated querying of the Clickstream dataset hosted on MongoDB. For that login into Dell Data Lakehouse system software UI, under Catalogs, Connect Catalog, Type è MongoDB and provide the configuration parameters.
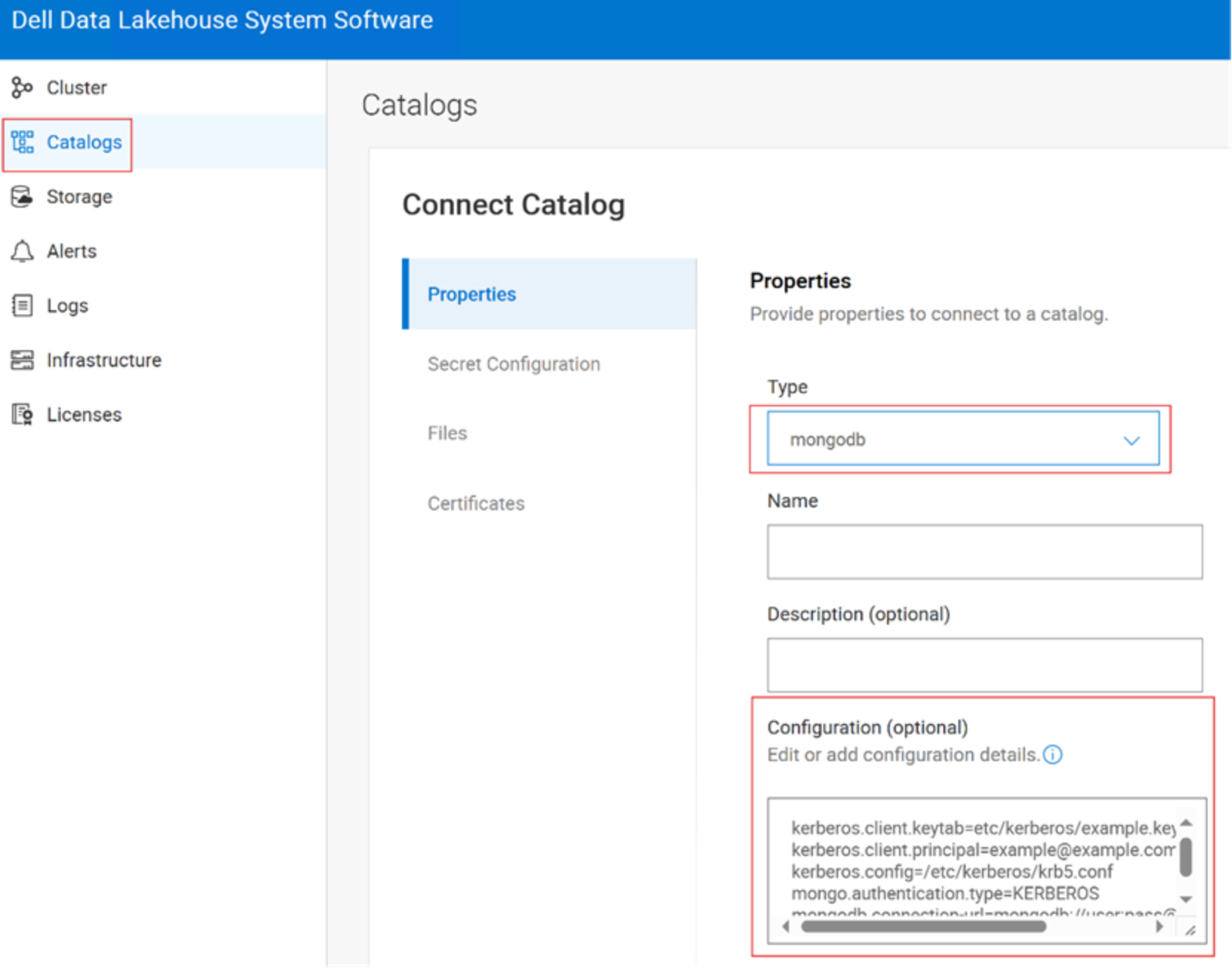
Figure 9. Add MongoDB Catalog
Airflow setup
To get started using Airflow to run data pipelines with DDAE, you need to complete the following steps:
- Install of Apache Airflow 2.10+
- Install the TrinoHook
- Create a Trino connection in Airflow
- Deploy a TrinoOperator
- Deploy your DAGs
Step 1: Install Apache Airflow 2.10
This step is out of scope, and it is assumed the Apache Airflow 2.10 in is installed in the service or utility node.
Step 2: Install TrinoHook
This step is out of scope, and this step is required only if Airflow is run in docker or any other container service.
Step 3: Create a Trino connection in Airflow
This step is out of scope, and it is assumed the Apache Airflow 2.10 is installed in the service or utility node.
After you have installed the TrinoHook and restarted Airflow, you can create a connection to your Trino cluster through the Airflow web UI. If you installed Airflow, then go to http://localhost:8080 on your browser and login. The default credentials unless changed are airflow for username and password.
Go to Admin > Connections.
Figure 10. Add New Connection to DDAE/Trino
Click the blue button to Add a new record.
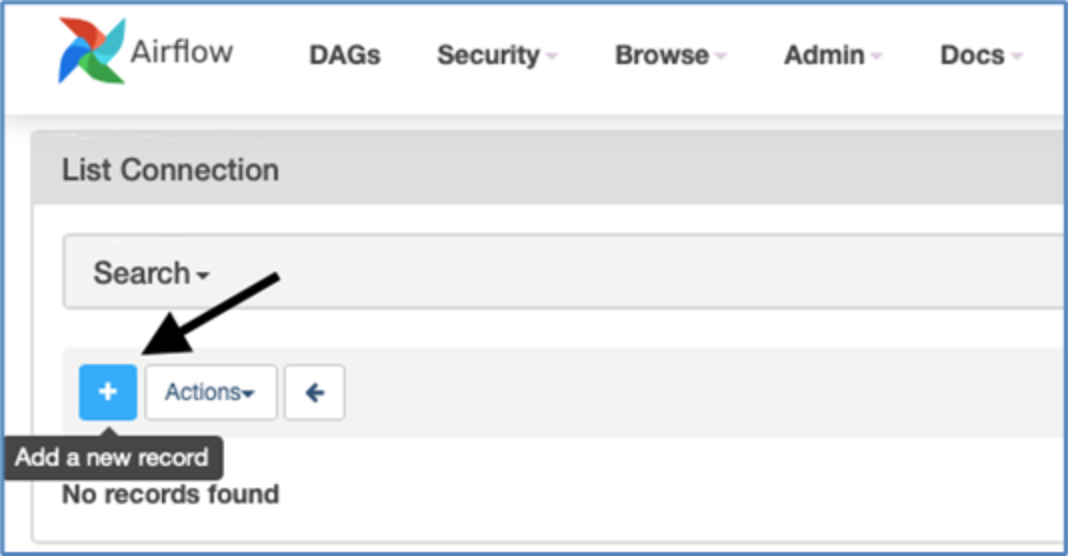
Figure 11. Add New record
Select Trino from the Connection Type dropdown and provide the following information:
Parameter
Remark
Connection Id
Whatever you want to call your connection.
Host
Provide DDAE Host name
Schema
A schema in your DDAE cluster.
Login
The username of the user that Airflow uses to connect to DDAE.
Password
The password of the user that Airflow uses to connect to DDAE if authentication is enabled.
Port
The port where the DDAE Web UI can be accessed
Extra
More settings, like protocol: https if using TLS, or verify: false if you are using a self-signed certificate.
The test button might not return any feedback for Trino connections.
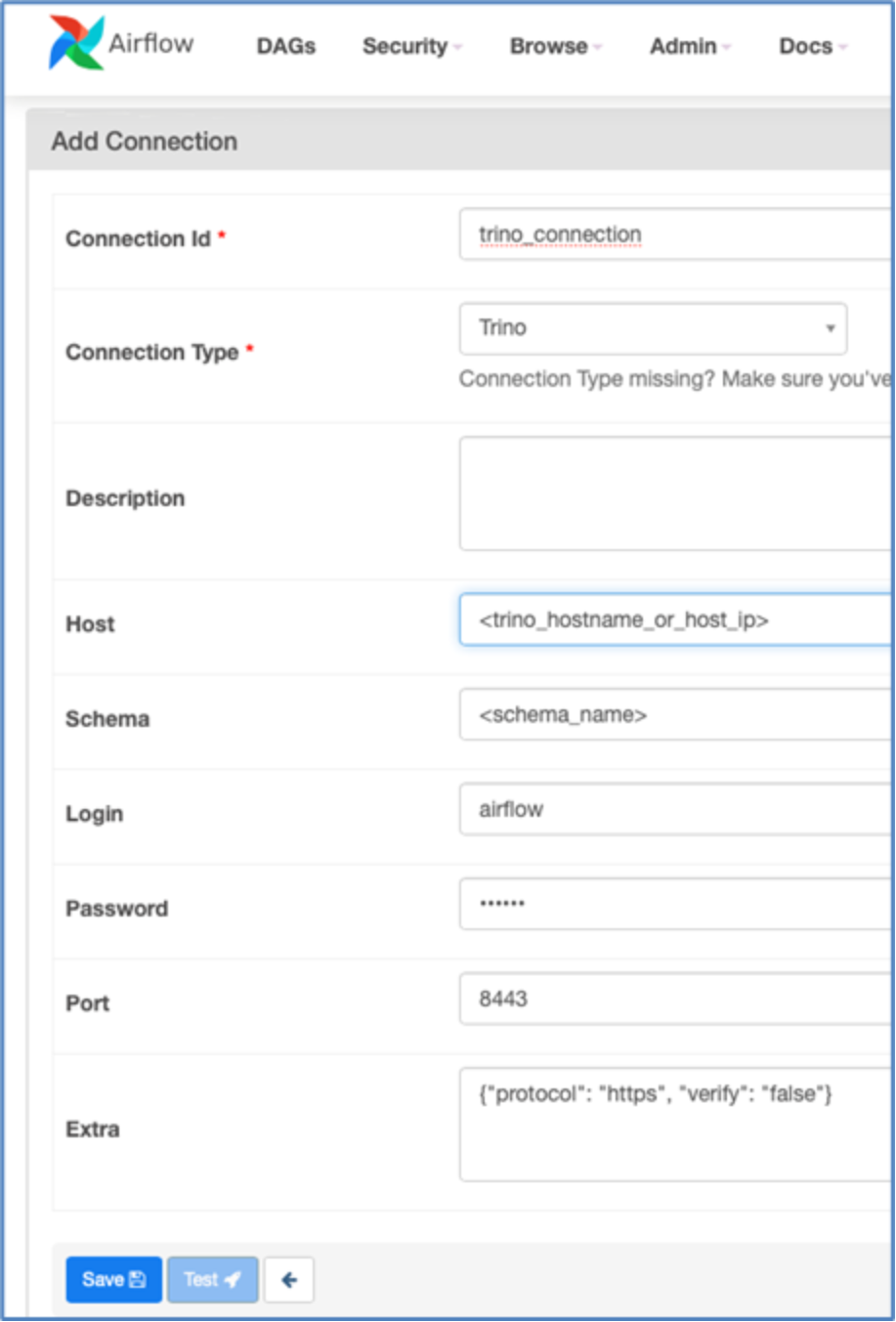
Figure 12. Add connection properties
Step 4: Deploy a TrinoOperator
The TrinoOperator lets you run SQL statements supported by Trino, like SELECT and INSERT. It allows running multiple statements within a single task. To use it, create a file named trino_operator.py in the airflow plugins directory. Airflow automatically compiles the code. In Airflow, Directed Acyclic Graphs (DAGs) define tasks and their dependencies for execution.
from airflow.models.baseoperator import BaseOperator
from airflow.utils.decorators import apply_defaults
from airflow.providers.trino.hooks.trino import TrinoHook
import logging
from typing import Sequence, Callable, Optional
def handler(cur):
cur.fetchall()
class TrinoCustomHook(TrinoHook):
def run(
self,
sql,
autocommit: bool = False,
parameters: Optional[dict] = None,
handler: Optional[Callable] = None,
) -> None:
""":sphinx-autoapi-skip:"""
return super(TrinoHook, self).run(
sql=sql, autocommit=autocommit, parameters=parameters, handler=handler
)
class TrinoOperator(BaseOperator):
template_fields: Sequence[str] = ('sql',)
@apply_defaults
def __init__(self, trino_conn_id: str, sql, parameters=None, **kwargs) -> None:
super().__init__(**kwargs)
self.trino_conn_id = trino_conn_id
self.sql = sql
self.parameters = parameters
def execute(self, context):
task_instance = context['task']
logging.info('Creating Trino connection')
hook = TrinoCustomHook(trino_conn_id=self.trino_conn_id)
sql_statements = self.sql
if isinstance(sql_statements, str):
sql = list(filter(None,sql_statements.strip().split(';')))
if len(sql) == 1:
logging.info('Executing single sql statement')
sql = sql[0]
return hook.get_first(sql, parameters=self.parameters)
if len(sql) > 1:
logging.info('Executing multiple sql statements')
return hook.run(sql, autocommit=False, parameters=self.parameters, handler=handler)
if isinstance(sql_statements, list):
sql = []
for sql_statement in sql_statements:
sql.extend(list(filter(None,sql_statement.strip().split(';'))))
logging.info('Executing multiple sql statements')
return hook.run(sql, autocommit=False, parameters=self.parameters, handler=handler)
Step 5: Deploy your DAGs
Deploy your first DAG by creating a file named my_first_trino_dag.py with provided code, then save it in airflow/dags directory.
import pendulum
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from trino_operator import TrinoOperator
## This method is called by task2 (below) to retrieve and print to the logs the return value of task1
def print_command(**kwargs):
task_instance = kwargs['task_instance']
print('Return Value: ',task_instance.xcom_pull(task_ids='task_1',key='return_value'))
with DAG(
default_args={
'depends_on_past': False
},
dag_id='my_first_trino_dag',
schedule_interval='0 8 * * *',
start_date=pendulum.datetime(2022, 5, 1, tz="US/Central"),
catchup=False,
tags=['example'],
) as dag:
## Task 1 runs a Trino select statement to count the number of records
## in the tpch.tiny.customer table
task1 = TrinoOperator(
task_id='task_1',
trino_conn_id='trino_connection',
sql="select count(1) from tpch.tiny.customer")
## Task 2 is a Python Operator that runs the print_command method above
task2 = PythonOperator(
task_id = 'print_command',
python_callable = print_command,
provide_context = True,
dag = dag)
## Task 3 demonstrates how you can use results from previous statements in new SQL statements
task3 = TrinoOperator(
task_id='task_3',
trino_conn_id='trino_connection',
sql="select ")
## Task 4 demonstrates how you can run multiple statements in a single session.
## Best practice is to run a single statement per task however statements that change session
## settings must be run in a single task. The set time zone statements in this example will
## not affect any future tasks but the two now() functions would timestamps for the time zone
## set before they were run.
task4 = TrinoOperator(
task_id='task_4',
trino_conn_id='trino_connection',
sql="set time zone 'America/Chicago'; select now(); set time zone 'UTC' ; select now()")
## The following syntax determines the dependencies between all the DAG tasks.
## Task 1 will have to complete successfully before any other tasks run.
## Tasks 3 and 4 won't run until Task 2 completes.
## Tasks 3 and 4 can run in parallel if there are enough worker threads.
task1 >> task2 >> [task3, task4]
Airflow automatically picks up and compiles DAGs. If compilation fails, Airflow displays an error message on the main page where all DAGs are listed. You can refresh the page until the DAG is added or an error message appears. Expand the message for details on the error source. Once the DAG appears on your list, trigger a manual run using the play button. Switch to the Graph view to monitor task statuses as they run.
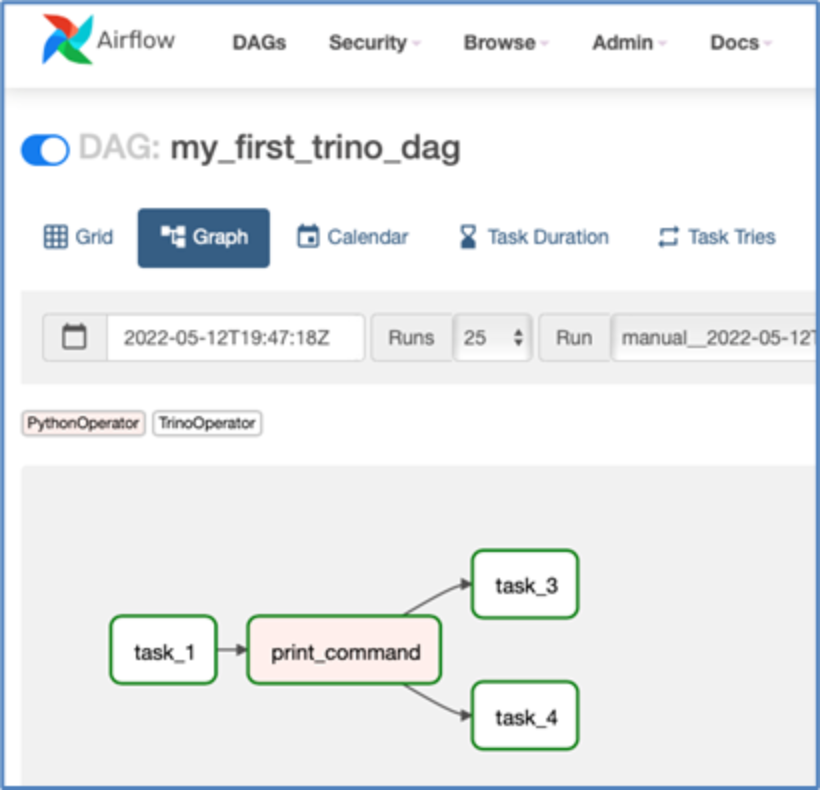
Figure 13. The DDAE/Trino DAG created
View task logs by clicking on the corresponding box and selecting "Log" from the options at the top.
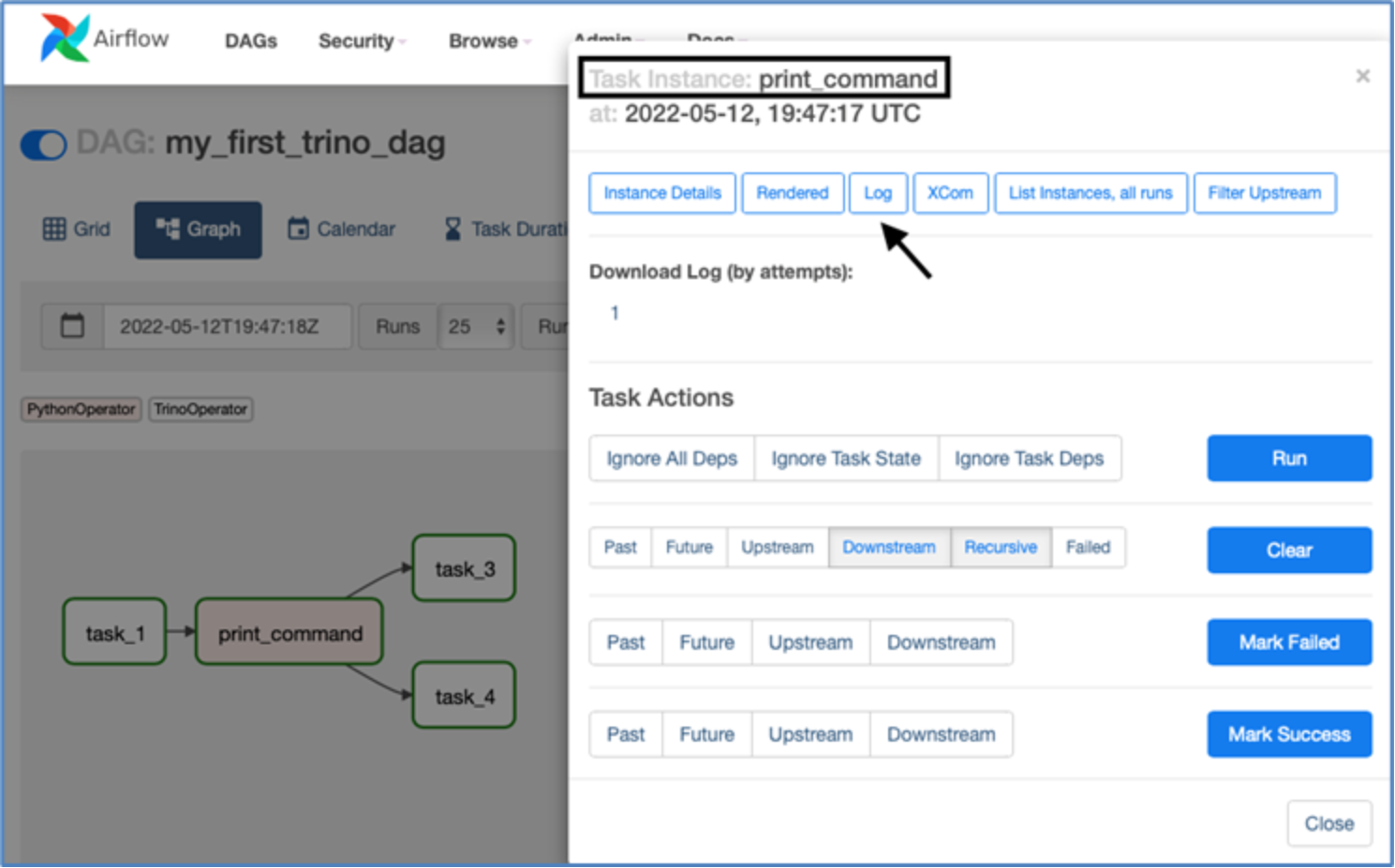
Figure 14. DDAE/Trino DAG Task instance logs
Review the logs for the "print_command" task to observe the return value of the select statement from "task_1".
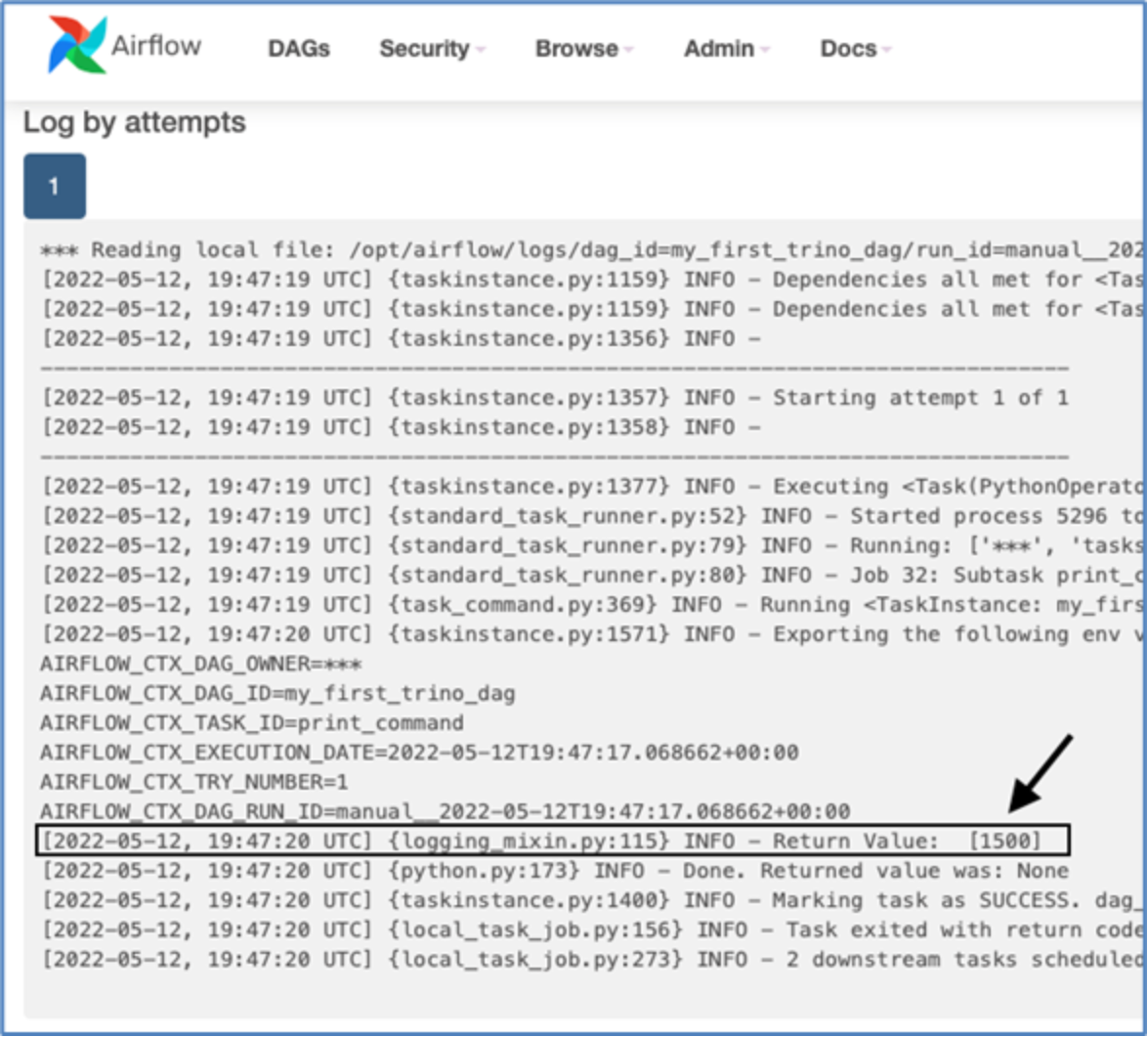
Figure 15. DDAE/Trino First DAG log
Output from print() commands is visible in these logs.