
Blogs

Silicon Diversity: Deploy GenAI on the PowerEdge XE9680 with AMD Instinct MI300X Accelerators
Thu, 11 Apr 2024 15:23:20 -0000
|Read Time: 0 minutes
| Entering the Era of Choice in AI: Putting Dell™ PowerEdge™ XE9680 Server with AMD Instinct™ MI300X Accelerators to the Test by Fine-tuning and Deploying Llama 2 70B Chat Model.
In this blog, Scalers AI™ will show you how to fine-tune large language models (LLMs), deploy 70B parameter models, and run a chatbot on the Dell™ PowerEdge™ XE9680 Server equipped with AMD Instinct™ MI300X Accelerators.
With the release of the AMD Instinct MI300X Accelerator, we are now entering an era of choice for leading AI Accelerators that power today’s generative AI solutions. Dell has paired the accelerators with its flagship PowerEdge XE9680 server for high performance AI applications. To put this leadership combination to the test, Scalers AI™ received early access and developed a fine-tuning stack with industry leading open-source components and deployed the Llama 2 70B Chat Model with FP16 precision in an enterprise chatbot scenario. In doing so, Scalers AI™ uncovered three critical value drivers:
- Deployed the Llama 2 70B parameter model on a single AMD Instinct MI300X Accelerator on the Dell PowerEdge XE9680 Server.
- Deployed eight concurrent instances of the model by utilizing all eight available AMD Instinct MI300X Accelerators on the Dell PowerEdge XE9680 Server.
- Fine-tuned the Llama 2 70B parameter model with FP16 precision on one Dell PowerEdge XE9680 Server with eight AMD Instinct MI300X accelerators.

This showcases industry leading total cost of ownership value for enterprises looking to fine-tune state of the art large language models with their own proprietary data, and deploy them on a single Dell PowerEdge XE9680 server equipped with AMD Instinct MI300X Accelerators.
 | “The PowerEdge XE9680 paired with AMD Instinct MI300X Accelerators delivers industry leading capability for fine-tuning and deploying eight concurrent instances of the Llama 2 70B FP16 model on a single server.”
| “The PowerEdge XE9680 paired with AMD Instinct MI300X Accelerators delivers industry leading capability for fine-tuning and deploying eight concurrent instances of the Llama 2 70B FP16 model on a single server.”
- Chetan Gadgil, CTO, Scalers AI
| To recreate, start with Dell PowerEdge XE9680 Server configurations as such.
OS: Ubuntu 22.04.4 LTS
Kernel version: 5.15.0-94-generic
Docker Version: Docker version 25.0.3, build 4debf41
ROCm™ version: 6.0.2
Server: Dell™ PowerEdge™ XE9680
GPU: 8x AMD Instinct™ MI300X Accelerators
| Setup Steps
- Install the AMD ROCm™ driver, libraries, and tools. Follow the detailed installation instructions for your Linux based platform.
To ensure these installations are successful, check the GPU info using rocm-smi.
- Clone the vLLM GitHub repository for 0.3.2 version as below:
git clone -b v0.3.2 https://github.com/vllm-project/vllm.git |
- Build the Docker container from the Dockerfile.rocm file inside the cloned vLLM repository.
cd vllm sudo docker build -f Dockerfile.rocm -t vllm-rocm:latest . |
- Use the command below to start the vLLM ROCm docker container and open the container shell.
sudo docker run -it \ --name vllm \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --shm-size 16G \ --group-add=video \ --workdir=/ \ vllm-rocm:latest bash |
- Request access to Llama 2 70B Chat Model from Llama 2 models from Meta and HuggingFace. Once the request is approved, log in to the Hugging Face CLI and enter your HuggingFace access token when prompted:
huggingface-cli login |
Part 1.0: Let’s start by showcasing how you can run the Llama 2 70B Chat Model on one AMD Instinct MI300X Accelerator on the PowerEdge XE9680 server. Previously we would use two cutting edge GPUs to complete this task. 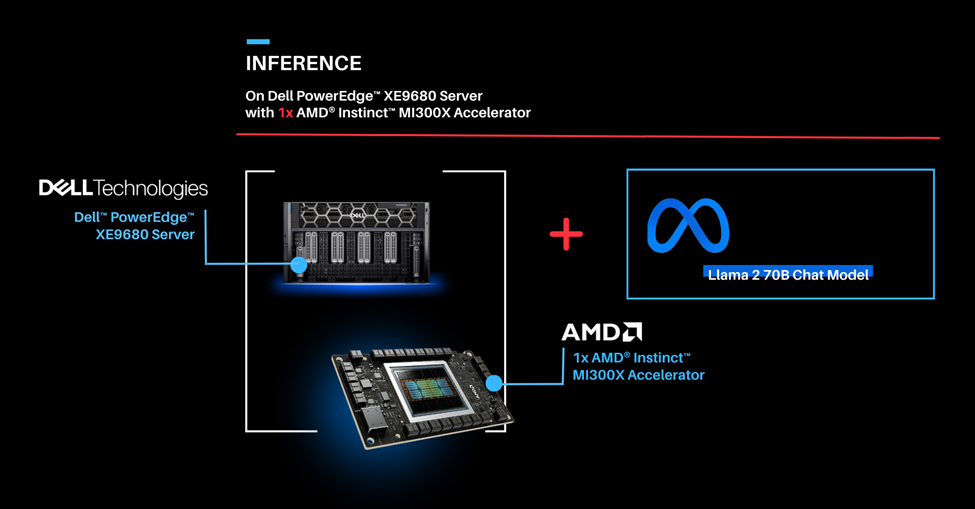
| Deploying Llama 2 70B Chat Model with vLLM 0.3.2 on a single AMD Instinct MI300X Accelerator with Dell PowerEdge XE9680 Server.
| Run vLLM Serving with Llama 2 70B Chat Model.
- Start the vLLM server for Llama 2 70B Chat model with FP16 precision loaded on a single AMD Instinct MI300X Accelerator.
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-70b-chat-hf --dtype float16 --tensor-parallel-size 1 |
- Execute the following curl request to verify if vLLM is successfully serving the model at the chat completion endpoint.
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-2-70b-chat-hf", "max_tokens":256, "temperature":1.0, "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Describe AMD ROCm in 180 words."} ]
}' |
The response should look as follows.
{"id":"cmpl-42f932f6081e45fa8ce7a7212cb19adb","object":"chat.completion","created":1150766,"model":"meta-llama/Llama-2-70b-chat-hf","choices":[{"index":0,"message":{"role":"assistant","content":" AMD ROCm (Radeon Open Compute MTV) is an open-source software platform developed by AMD for high-performance computing and deep learning applications. It allows developers to tap into the massive parallel processing power of AMD Radeon GPUs, providing faster performance and more efficient use of computational resources. ROCm supports a variety of popular deep learning frameworks, including TensorFlow, PyTorch, and Caffe, and is designed to work seamlessly with AMD's GPU-accelerated hardware. ROCm offers features such as low-level hardware control, GPU Virtualization, and support for multi-GPU configurations, making it an ideal choice for demanding workloads like artificial intelligence, scientific simulations, and data analysis. With ROCm, developers can take full advantage of AMD's GPU capabilities and achieve faster time-to-market and better performance for their applications."},"finish_reason":"stop"}],"usage":{"prompt_tokens":42,"total_tokens":237,"completion_tokens":195}} |
Part 1.1: Now that we have deployed the Llama 2 70B Chat Model on one AMD Instinct MI300X Accelerator on the Dell PowerEdge XE9680 server, let’s create a chatbot.
| Running Gradio Chatbot with Llama 2 70B Chat Model

This Gradio chatbot works by sending the user input query received through the user interface to the Llama 2 70B Chat Model being served using vLLM. The vLLM server is compatible with the OpenAI Chat API hence the request is sent in the OpenAI Chat API compatible format. The model generates the response based on the request which is sent back to the client. This response is displayed on the Gradio chatbot user interface.
| Deploying Gradio Chatbot
- If not already done, follow the instructions in the Setup Steps section to install the AMD ROCm driver, libraries, and tools, clone the vLLM repository, build and start the vLLM ROCm Docker container, and request access to the Llama 2 Models from Meta.
- Install the prerequisites for running the chatbot.
pip3 install -U pip pip3 install openai==1.13.3 gradio==4.20.1 |
- Log in to the Hugging Face CLI and enter your HuggingFace access token when prompted:
huggingface-cli login |
- Start the vLLM server for Llama 2 70B Chat model with data type FP16 on one AMD Instinct MI300X Accelerator.
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-70b-chat-hf --dtype float16 |
- Run the gradio_openai_chatbot_webserver.py from the /app/vllm/examples directory within the container with the default configurations.
cd /app/vllm/examples python3 gradio_openai_chatbot_webserver.py --model meta-llama/Llama-2-70b-chat-hf |
The Gradio chatbot will be running on the port 8001 and can be accessed using the URL http://localhost:8001. The query passed to the chatbot is “How does AMD ROCm contribute to enhancing the performance and efficiency of enterprise AI workflows?” The output conversation with the chatbot is shown below:

- To observe the GPU utilization, use the rocm-smi command as shown below.

- Use the command below to access various vLLM serving metrics through the /metrics endpoint.
curl http://127.0.0.1:8000/metrics |
The output should look as follows.
# HELP exceptions_total_counter Total number of requested which generated an exception # TYPE exceptions_total_counter counter # HELP requests_total_counter Total number of requests received # TYPE requests_total_counter counter requests_total_counter{method="POST",path="/v1/chat/completions"} 1 # HELP responses_total_counter Total number of responses sent # TYPE responses_total_counter counter responses_total_counter{method="POST",path="/v1/chat/completions"} 1 # HELP status_codes_counter Total number of response status codes # TYPE status_codes_counter counter status_codes_counter{method="POST",path="/v1/chat/completions",status_code="200"} 1 # HELP vllm:avg_generation_throughput_toks_per_s Average generation throughput in tokens/s. # TYPE vllm:avg_generation_throughput_toks_per_s gauge vllm:avg_generation_throughput_toks_per_s{model_name="meta-llama/Llama-2-70b-chat-hf"} 4.222076684555402 # HELP vllm:avg_prompt_throughput_toks_per_s Average prefill throughput in tokens/s. # TYPE vllm:avg_prompt_throughput_toks_per_s gauge vllm:avg_prompt_throughput_toks_per_s{model_name="meta-llama/Llama-2-70b-chat-hf"} 0.0 ... # HELP vllm:prompt_tokens_total Number of prefill tokens processed. # TYPE vllm:prompt_tokens_total counter vllm:prompt_tokens_total{model_name="meta-llama/Llama-2-70b-chat-hf"} 44 ... vllm:time_per_output_token_seconds_count{model_name="meta-llama/Llama-2-70b-chat-hf"} 136.0 vllm:time_per_output_token_seconds_sum{model_name="meta-llama/Llama-2-70b-chat-hf"} 32.18783768080175 ... vllm:time_to_first_token_seconds_count{model_name="meta-llama/Llama-2-70b-chat-hf"} 1.0 vllm:time_to_first_token_seconds_sum{model_name="meta-llama/Llama-2-70b-chat-hf"} 0.2660619909875095 |
Part 2: Now that we have deployed the Llama 2 70B Chat Model on a single GPU, let’s take full advantage of the Dell PowerEdge XE9680 server and deploy eight concurrent instances of the Llama 2 70B Chat Model with FP16 precision. To handle more simultaneous users and generate higher throughput, the 8x AMD Instinct MI300X Accelerators can be leveraged to deploy 8 vLLM serving deployments in parallel.
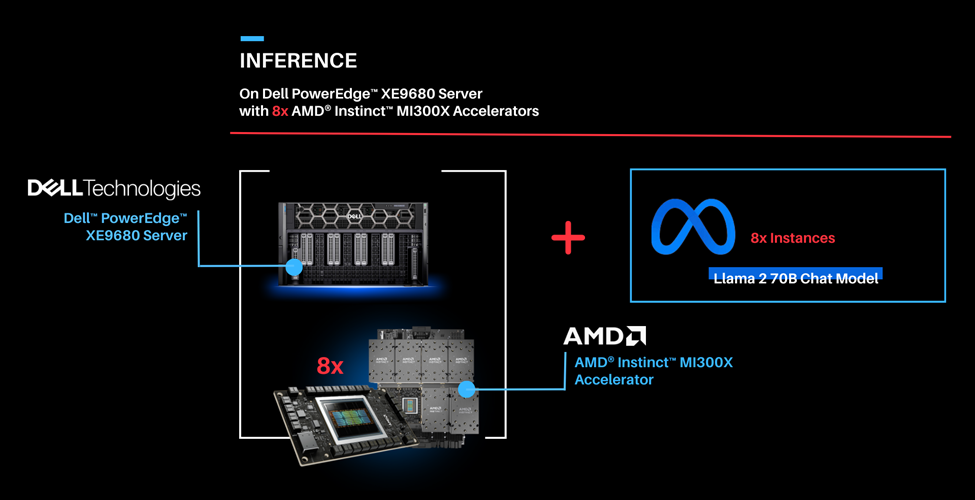
| Serving Llama 2 70B Chat model with FP16 precision using vLLM 0.3.2 on 8x AMD Instinct MI300X Accelerators with the PowerEdge XE9680 Server.
To enable the multi GPU vLLM deployment, we use a Kubernetes based stack. The stack consists of a Kubernetes Deployment with 8 vLLM serving replicas and a Kubernetes Service to expose all vLLM serving replicas through a single endpoint. The Kubernetes Service utilizes a round robin based strategy to distribute the requests across the vLLM serving replicas.
| Prerequisites
- Any Kubernetes distribution on the server.
- AMD GPU device plugins for Kubernetes setup on the installed Kubernetes distribution.
- A Kubernetes secret that grants access to the container registry, facilitating Kubernetes deployment.
| Deploying the multi vLLM serving on 8x AMD Instinct MI300X Accelerators.
- If not already done, follow the instructions in the Setup Steps section to install the AMD ROCm driver, libraries, and tools, clone the vLLM repository, build the vLLM ROCm Docker container, and request access to the Llama 2 Models from Meta. Push the built vllm-rocm:latest image to the container registry of your choice.
- Create a deployment yaml file “multi-vllm.yaml” based on the sample provided below.
# vllm deployment apiVersion: apps/v1 kind: Deployment metadata: name: vllm-serving namespace: default labels: app: vllm-serving spec: selector: matchLabels: app: vllm-serving replicas: 8 template: metadata: labels: app: vllm-serving spec: containers: - name: vllm image: container-registry/vllm-rocm:latest # update the container registry name args: [ "python3", "-m", "vllm.entrypoints.openai.api_server", "--model", "meta-llama/Llama-2-70b-chat-hf" ] env: - name: HUGGING_FACE_HUB_TOKEN value: "" # add your huggingface token with Llama 2 models access resources: requests: cpu: 15 memory: 150G amd.com/gpu: 1 # each replica is allocated 1 GPU limits: cpu: 15 memory: 150G amd.com/gpu: 1 imagePullSecrets: - name: cr-login # kubernetes container registry secret --- # nodeport service with round robin load balancing apiVersion: v1 kind: Service metadata: name: vllm-serving-service namespace: default spec: selector: app: vllm-serving type: NodePort ports: - name: vllm-endpoint port: 8000 targetPort: 8000 nodePort: 30800 # the external port endpoint to access the serving |
- Deploy the multi vLLM serving using the deployment configuration with kubectl. This will deploy eight replicas of vLLM serving using the Llama 2 70B Chat model with FP16 precision.
kubectl apply -f multi-vllm.yaml |
- Execute the following curl request to verify whether the model is being successfully served at the chat completion endpoint at port 30800.
curl http://localhost:30800/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-2-70b-chat-hf", "max_tokens":256, "temperature":1.0, "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Describe AMD ROCm in 180 words."} ]
}' |
The response should look as follows:
{"id":"cmpl-42f932f6081e45fa8ce7dnjmcf769ab","object":"chat.completion","created":1150766,"model":"meta-llama/Llama-2-70b-chat-hf","choices":[{"index":0,"message":{"role":"assistant","content":" AMD ROCm (Radeon Open Compute MTV) is an open-source software platform developed by AMD for high-performance computing and deep learning applications. It allows developers to tap into the massive parallel processing power of AMD Radeon GPUs, providing faster performance and more efficient use of computational resources. ROCm supports a variety of popular deep learning frameworks, including TensorFlow, PyTorch, and Caffe, and is designed to work seamlessly with AMD's GPU-accelerated hardware. ROCm offers features such as low-level hardware control, GPU Virtualization, and support for multi-GPU configurations, making it an ideal choice for demanding workloads like artificial intelligence, scientific simulations, and data analysis. With ROCm, developers can take full advantage of AMD's GPU capabilities and achieve faster time-to-market and better performance for their applications."},"finish_reason":"stop"}],"usage":{"prompt_tokens":42,"total_tokens":237,"completion_tokens":195}} |
- We used load testing tools similar to Apache Bench to simulate concurrent user requests to the serving endpoint. The screenshot below showcases the output of rocm-smi while Apache Bench is running 2048 concurrent requests.

Part 3: Now that we have deployed the Llama 2 70B Chat model on both one GPU and eight concurrent GPUs, let's try fine-tuning Llama 2 70B Chat with Hugging Face Accelerate.
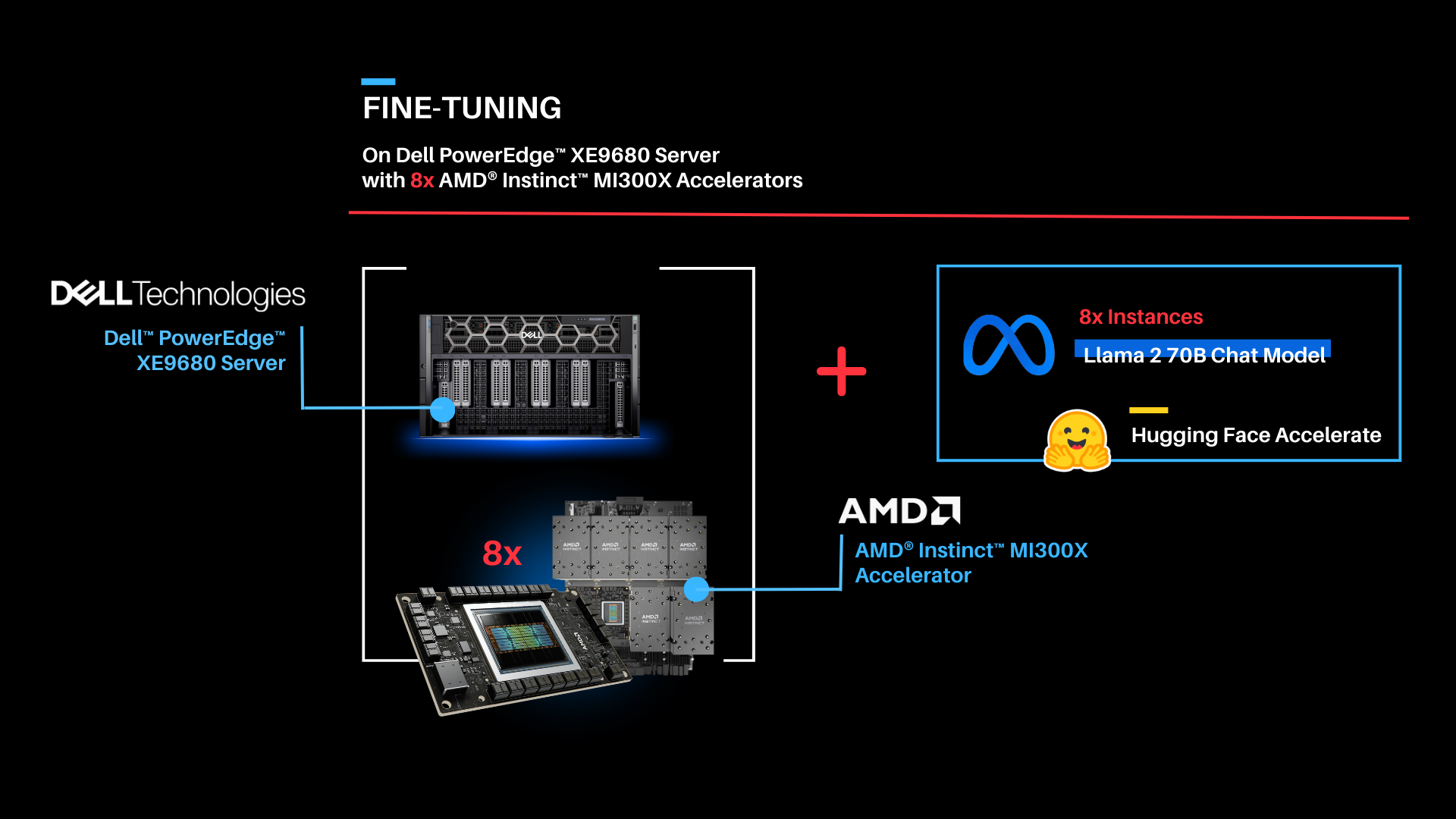
| Fine-tuning
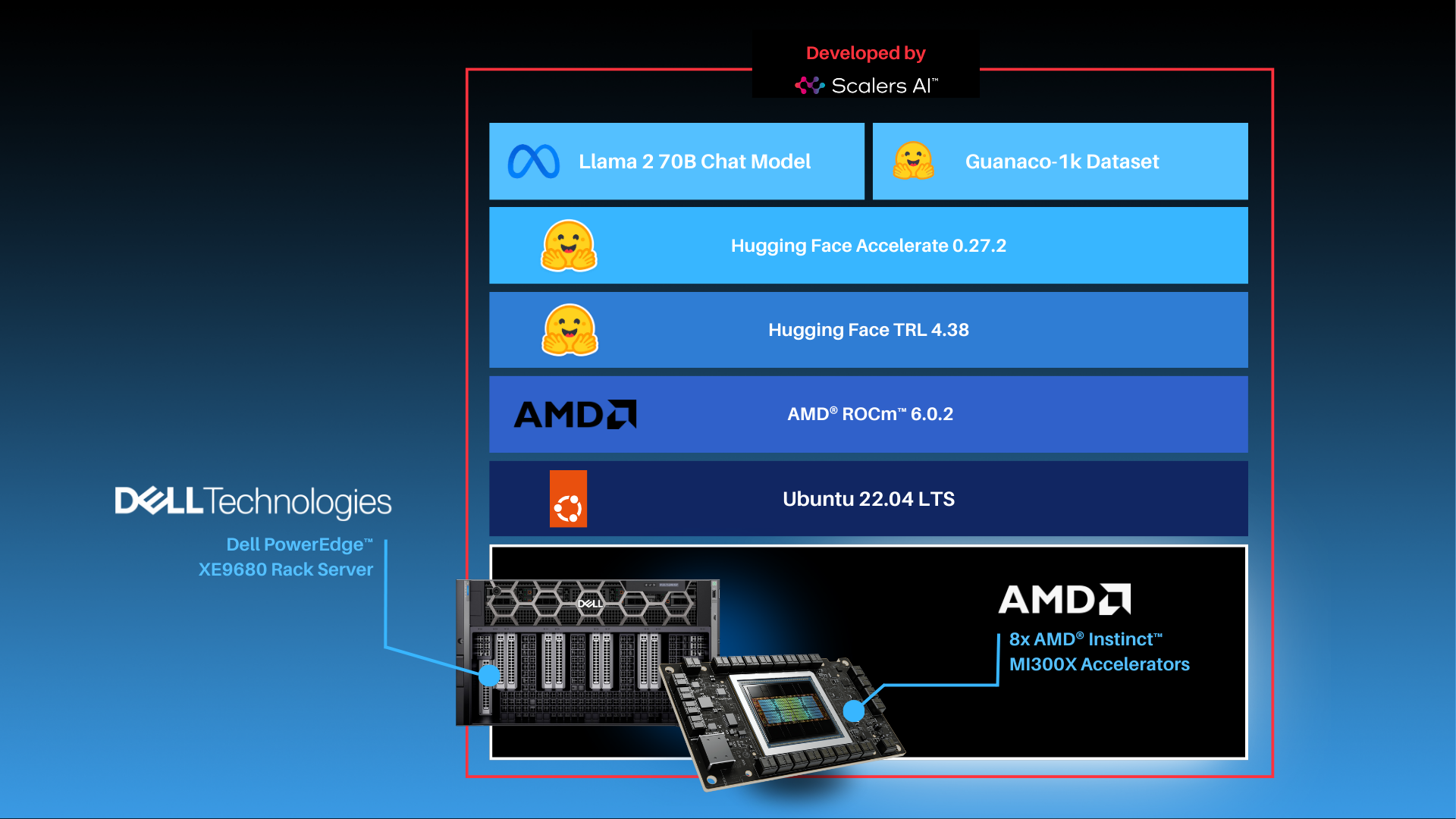
As shown above, the fine-tuning software stack begins with the AMD ROCm PyTorch image serving as the base, offering a tailored PyTorch library for optimal fine-tuning. Leveraging the Hugging Face Transformers library alongside Hugging Face Accelerate, facilitates multi-GPU fine-tuning capabilities. The Llama 2 70B Chat model will be fine-tuned with FP16 precision, utilizing the Guanaco-1k dataset from Hugging Face on eight AMD Instinct MI300X Accelerators.
In this scenario, we will perform full parameter fine-tuning of the Llama 2 70B Chat Model. While you can also implement fine-tuning using optimized techniques such as Low-Rank Adaptation of Large Language Models (LoRA) on accelerators with smaller memory footprints, performance tradeoffs exist on specific complex objectives. These nuances are addressed by full parameter fine-tuning methods, which generally require accelerators that support significant memory requirements.
| Fine-tuning Llama 2 70B Chat on 8x AMD Instinct MI300X Accelerators.
Fine-tune the Llama 2 70B Chat Model with FP16 precision for question and answer tasks by utilizing the mlabonne/guanaco-llama2-1k dataset on the 8X AMD Instinct MI300X Accelerators.
- If not already done, install the AMD ROCm driver, libraries, and tools and request access to the Llama 2 Models from Meta following the instructions in the Setup Steps section.
- Start the fine-tuning docker container with the AMD ROCm PyTorch base image.
The below command opens a shell within the docker container.
sudo docker run -it \ --name fine-tuning \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --shm-size 16G \ --group-add=video \ --workdir=/ \ rocm/pytorch:rocm6.0.2_ubuntu22.04_py3.10_pytorch_2.1.2 bash |
- Install the necessary Python prerequisites.
pip3 install -U pip pip3 install transformers==4.38.2 trl==0.7.11 datasets==2.18.0 |
- Log in to Hugging Face CLI and enter your HuggingFace access token when prompted.
huggingface-cli login |
- Import the required Python packages.
from datasets import load_dataset from transformers import ( AutoModelForCausalLM, AutoTokenizer, TrainingArguments, pipeline ) from trl import SFTTrainer |
- Load the Llama 2 70B Chat Model and the mlabonne/guanaco-llama2-1k dataset from Hugging Face.
# load the model and tokenizer base_model_name = "meta-llama/Llama-2-70b-chat-hf"
# tokenizer parameters llama_tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True) llama_tokenizer.pad_token = llama_tokenizer.eos_token llama_tokenizer.padding_side = "right"
# load the based model base_model = AutoModelForCausalLM.from_pretrained( base_model_name, device_map="auto", ) base_model.config.use_cache = False base_model.config.pretraining_tp = 1
# load the dataset from huggingface dataset_name = "mlabonne/guanaco-llama2-1k" training_data = load_dataset(dataset_name, split="train") |
- Define fine-tuning configurations and start fine-tuning for 1 epoch. The fine tuned model will be saved in finetuned_llama2_70b directory.
# fine tuning parameters train_params = TrainingArguments( output_dir="./runs", num_train_epochs=1, # fine tuning for 1 epochs per_device_train_batch_size=8 # setting per GPU batch size )
# define the trainer fine_tuning = SFTTrainer( model=base_model, train_dataset=training_data, dataset_text_field="text", tokenizer=llama_tokenizer, args=train_params, max_seq_length=512 )
# start the fine tuning run fine_tuning.train()
# save the fine tuned model fine_tuning.model.save_pretrained("finetuned_llama2_70b") print("Fine-tuning completed") |
- Use the `rocm-smi` command to observe GPU utilization while fine-tuning.

| Summary

Dell PowerEdge XE9680 Server equipped with AMD Instinct MI300X Accelerators offers enterprises industry leading infrastructure to create custom AI solutions using their proprietary data. In this blog, we showcased how enterprises deploying applied AI can take advantage of this solution in three critical use cases:
- Deploying the entire 70B parameter model on a single AMD Instinct MI300X Accelerator in Dell PowerEdge XE9680 Server
- Deploying eight concurrent instances of the model, each running on one of eight AMD Instinct MI300X accelerators on the Dell PowerEdge XE9680 Server
- Fine-tuning the 70B parameter model with FP16 precision on one PowerEdge XE9680 with all eight AMD Instinct MI300X accelerators
Scalers AI is excited to see continued advancements from Dell, AMD, and Hugging Face on hardware and software optimizations in the future.
| Additional Criteria for IT Decision Makers
| What is fine-tuning, and why is it critical for enterprises?
Fine-tuning enables enterprises to develop custom models with their proprietary data by leveraging the knowledge already encoded in pre-trained models. As a result, fine-tuning requires less labeled data and time for training compared to training a model from scratch, making it a more efficient approach for achieving competitive performance, particularly in the quantity of computational resources used and training time.
| Why is memory footprint critical for LLMs?
Large language models often have enormous numbers of parameters, leading to significant memory requirements. When working with LLMs, it is essential to ensure that the GPU has sufficient memory to store these parameters so that the model can run efficiently. In addition to model parameters, large language models require substantial memory to store input data, intermediate activations, and gradients during training or inference, and insufficient memory can lead to data loss or performance degradation.
| Why is the Dell PowerEdge XE9680 Server with AMD Instinct MI300X Accelerators well-suited for LLMs?
Designed especially for AI tasks, Dell PowerEdge XE9680 Server is a robust data-processing server equipped with eight AMD Instinct MI300X accelerators, making it well-suited for AI-workloads, especially for those involving training, fine-tuning, and conducting inference with LLMs. AMD Instinct MI300X Accelerator is a high-performance AI accelerator intended to operate in groups of eight within AMD’s generative AI platform.
Running inference, specifically with a Large Language Model (LLM), requires approximately 1.2 times the memory occupied by the model on a GPU. In FP16 precision, the model memory requirement can be estimated as 2 bytes per parameter multiplied by the number of model parameters. For example, the Llama 2 70B model with FP16 precision requires a minimum of 168 GB of GPU memory to run inference.
With 192 GB of GPU memory, a single AMD Instinct MI300X Accelerator can host an entire Llama 2 70B parameter model for inference. It is optimized for LLMs and can deliver up to 10.4 Petaflops of performance (BF16/FP16) with 1.5TB of total HBM3 memory for a group of eight accelerators.
Copyright © 2024 Scalers AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. AMD, Instinct™, ROCm™, and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other product names are the trademarks of their respective owners.
***DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.

Part I: Is AMD ROCm™ Ready to Deploy Leading AI Workloads?
Thu, 09 Nov 2023 23:21:48 -0000
|Read Time: 0 minutes
 PowerEdge R7615
PowerEdge R7615
 AMD Instinct MI210 Accelerator
AMD Instinct MI210 Accelerator
Today, Innovation is GPU constrained, and we are seeing explosive growth in AI workloads, namely transformer based models for Generative AI. This blog explores AMD ROCm™ software and AMD GPUs, and AMD readiness for primetime.
AMD ROCm™ or Radeon Open eCosystem (ROCm) was launched in 2016 as an open-source software foundation for GPU computing in Linux, providing developers with tools to leverage GPUs compute capacity to advance their workloads across applications including high performance computing and advanced rendering. It provides a comprehensive set of tools and libraries for programming GPUs in a variety of languages, including C++, Python, and R.
| AMD ROCm™ can be used to accelerate a variety of workloads, such as:
- Scientific computing and computer-aided design (CAD): AMD ROCm™ can accelerate scientific simulations, such as molecular dynamics and computational fluid dynamics.
- Artificial Intelligence: AMD ROCm™ can be used to train and deploy AI models faster and more efficiently.
- Data science: AMD ROCm™ can accelerate data processing and analytics tasks.
- Graphics and visualization: AMD ROCm™ can create and render high-performance graphics and visualizations.
With the broad and rising adoption of Generative AI driving the need for parallel computational power of GPUs to train, fine-tune, and deploy deep learning models, AMD ROCm™ has expanded support for the leading AI frameworks in TensorFlow, PyTorch, ONNX runtime, and more recently Hugging Face.
Hugging Face and AMD announced a collaboration to support AMD ROCm™ and hardware platforms to deliver leadership transformer performance on AMD CPUs and GPUs for training and inference. The initial focus will be on AMD Instinct™ MI2xx and MI3xx series GPUs¹.
AMD and Hugging Face plan to support transformer architectures for natural language processing, computer vision, and speech. Plans also include traditional computer vision models and recommendation models.
| “We will integrate AMD ROCm™ SDK seamlessly in our open-source libraries, starting with the transformers library.”
Further, Hugging Face highlighted plans for a new Optimum library dedicated to AMD¹. In addition to the growing ecosystem for AI software support for AMD ROCm™, Dell™ offers a portfolio of leading edge PowerEdge™ hardware supporting AMD ROCm™ and the AMD MI210 across Dell™ PowerEdge™ R760xa and R7615 servers.
The breadth of hardware offerings gives enterprise users of AMD ROCm™ robust hardware choices to pair with fast-advancing software support.

The architecture above showcases the robust availability of AMD ROCm™ software and Hugging Face integration, allowing developers to run leading transformer models optimized on AMD Instinct™ GPUs today. Dell™ offers a robust portfolio of PowerEdge™ servers that support GPUs supported by AMD ROCm™.
This enables customers to easily get the hardware needed to test, develop, and deploy AI solutions with AMD ROCm™.
| So is AMD ROCm™ Ready for AI Workloads?
Though the AMD ROCm™ adoption and ecosystem maturity are nascent, the support of leading AI frameworks and collaboration with key ecosystem partners such as Hugging Face, paired with AMD advancements in GPU Hardware, make it ready to take on the leading AI workloads today.
In part II of this blog series, we will put the architecture to the test and develop a LLM-based chatbot on Dell™ PowerEdge™ servers with AMD ROCm™ and AMD GPUs.
| References
https://huggingface.co/blog/huggingface-and-amd
| Authors
Steen Graham, CEO of Scalers AI
Delmar Hernandez, Dell PowerEdge Technical Marketing
Mohan Rokkam, Dell PowerEdge Technical Marketing

Part II | How to Run Hugging Face Models with AMD ROCm™ on Dell™ PowerEdge™?
Tue, 14 Nov 2023 16:27:00 -0000
|Read Time: 0 minutes
In case you’re interested in learning more about how Dell and Hugging Face are working together, check out the November 14 announcement detailing how the two companies are simplifying GenAI with on-premises IT.
 PowerEdge R7615
PowerEdge R7615
 AMD Instinct MI210 Accelerator
AMD Instinct MI210 Accelerator
In our first blog, we explored the readiness of the AMD ROCm™ ecosystem to run modern Generative AI workloads. This blog provides a step-by-step guide to running Hugging Face models on AMD ROCm™ and insights on setting up TensorFlow, PyTorch, and GPT-2.
Dell PowerEdge offers a rich portfolio of AMD ROCm™ solutions, including Dell™ R7615, R760xa, R7615, and R7625 PowerEdge™ servers.
For this blog, we selected the Dell PowerEdge R7615.
| System Configuration Details
Operating system: Ubuntu 22.04.3 LTS
Kernel version: 5.15.0-86-generic
Docker Version: Docker version 24.0.6, build ed223bc
ROCm version: 5.7
Server: Dell™ PowerEdge™ R7615
CPU: AMD EPYC™ 9354P 32-Core Processor
GPU: AMD Instinct™ MI210
| Step-by-Step Guide
1. First, Install the AMD ROCm™ driver, libraries, and tools. Follow the detailed installation instructions for your Linux based platform.
To ensure these installations are successful, check the GPU info using `rocm-smi.`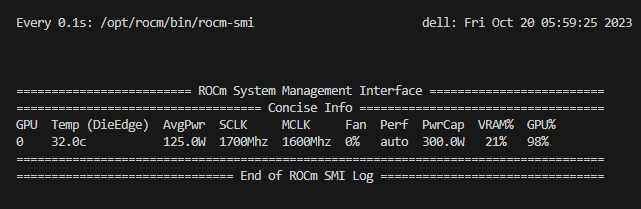
2. Next, we will select code snippets from Hugging Face. Hugging Face offers the most comprehensive developer tools for leading AI models. We will choose GPT2 code snippets for both TensorFlow and PyTorch.
| Running GPT2 on AMD ROCm™ with TensorFlow
Here, we use the AMD ROCm™ docker image for TensorFlow and launch GPT2 inference on an AMD™ GPU.
3. Use docker images for TensorFlow with AMD ROCm™ backend support to expedite the setup
Unset sudo docker run -it \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --ipc=host \ --shm-size 16G \ --group-add video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --workdir=/dockerx \ -v $HOME/dockerx:/dockerx rocm/tensorflow:latest /bin/bash |
4. Run TensorFlow code from Hugging Face to infer GPT2 successfully inside a Docker container with the AMD™ GPU, using the following snippet
Python from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2") GPT2 = TFGPT2LMHeadModel.from_pretrained("gpt2") prompt = "What is Quantum Computing?"
input_ids = tokenizer.encode(prompt, return_tensors='tf')
output = GPT2.generate(input_ids, max_length = 100) print(tokenizer.decode(output[0], skip_special_tokens = True)) |
| Running GPT2 on AMD ROCm™ with PyTorch
5. Use docker images for PyTorch with AMD ROCm™ backend support to expedite the setup
Unset sudo docker run -it \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --ipc=host \ --shm-size 16G \ --group-add=video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --workdir=/dockerx \ -v $HOME/dockerx:/dockerx rocm/pytorch:rocm5.7_ubuntu22.04_py3.10_pytorch_2.0.1 /bin/bash |
6. Use the snippet below to run a PyTorch from Hugging Face script in a Docker container
| Python from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2', device_map="auto") model = GPT2LMHeadModel.from_pretrained('gpt2', device_map="auto") prompt = "What is Quantum Computing?"
encoded_input = tokenizer(prompt, return_tensors='pt') encoded_input = encoded_input.to('cuda')
output = model.generate(**encoded_input, max_length=100) print(tokenizer.decode(output[0], skip_special_tokens = True)) |
| As you can see, AMD ROCm™ has a rich ecosystem of support for leading AI frameworks like PyTorch, TensorFlow, and Hugging Face to set up and deploy industry-leading transformer models.
If you are interested in trying different models from Hugging Face, you can refer to the comprehensive set of transformer models supported here: https://huggingface.co/docs/transformers/index
Our next blog shows you how to run Llama-2 in a chat application, arguably the leading large language model available to developers today using Hugging Face.
| References
- https://huggingface.co/amd
- https://huggingface.co/docs/transformers/index
- https://rocm.docs.amd.com/en/latest/deploy/linux/quick_start.html
- https://medium.com/@qztseng/install-and-build-tensorflow2-3-on-amd-gpu-with-rocm-7c812f922f57
- https://hub.docker.com/r/rocm/pytorch/tags
| Authors:
Steen Graham, CEO of Scalers AI
Delmar Hernandez, Dell PowerEdge Technical Marketing
Mohan Rokkam, Dell PowerEdge Technical Marketing

Part III | How to Run Llama-2 via Hugging Face Models on AMD ROCm™ with Dell PowerEdge™?
Thu, 09 Nov 2023 23:21:47 -0000
|Read Time: 0 minutes
 PowerEdge R7615
PowerEdge R7615
 AMD Instinct MI210 Accelerator
AMD Instinct MI210 Accelerator
In our second blog, we provided a step-by-step guide on how to get models running on AMD ROCm™, set up TensorFlow and PyTorch, and deploying GPT-2. In this guide, we are now exploring how to set up a leading large language model (LLM) Llama-2 using Hugging Face.
Dell™ PowerEdge™ offers a rich portfolio of AMD ROCm™ solutions, including Dell™ PowerEdge™ R7615, R7625, and R760xa servers.
| We implemented the following Dell™ PowerEdge™ system configurations
Operating system: Ubuntu 22.04.3 LTS
Kernel version: 5.15.0-86-generic
Docker Version: Docker version 24.0.6, build ed223bc
ROCm version: 5.7
Server: Dell PowerEdge R7615
CPU: AMD EPYC™ 9354P 32-Core Processor
GPU: AMD Instinct™ MI210

| Step-by-Step Guide
1. First, Install AMD ROCm™ driver, libraries, and tools. Follow the detailed installation instructions for your Linux based platform.
To ensure these installations are successful, check the GPU info using `rocm-smi`.
2. Next, we will select code snippets from Hugging Face. Hugging Face offers the most comprehensive set of developer tools for leading AI models. We will select GPT2 code snippets for both TensorFlow and PyTorch. Follow the steps in blog 2 (link) to start the ROCm PyTorch docker container.
Follow the steps in Blog II to start the AMD ROCm™ PyTorch docker container.
| Running a chatbot with Llama2-7B-chat model and Gradio ChatInterface:
The Llama-2-7b-chat model from Hugging Face is a large language model developed by Facebook AI and Meta, designed for text generation tasks. It is a part of the Llama2 series, featuring an impressive 6.74 billion parameters, and is primarily used for creating AI chatbots and generating human-like text.
Gradio ChatInterface is Gradio's high-level abstraction for creating chatbot UIs and allows you to create a web-based demo around the Llama2-7B- chat model in a few lines of code.
Install Prerequisites:
Python pip3 install transformers sentencepiece accelerate gradio protobuf |
Request access token:
Request access to Llama-2 7B Chat Model: Llama-2-7B-Chat-HF
Log in to Hugging Face CLI and enter your access token when prompted:
Unset huggingface-cli login |
Perform Python code:
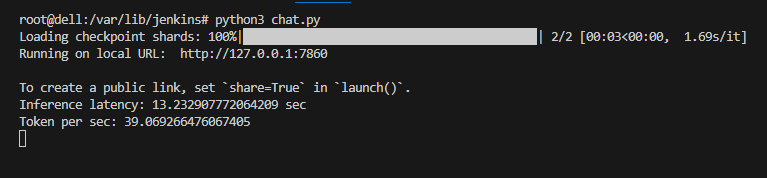
Python import time import torch from transformers import LlamaForCausalLM, LlamaTokenizer import gradio as gr model_name = "meta-llama/Llama-2-7b-chat-hf" torch_dtype = torch.bfloat16 max_new_tokens = 500 # Initialize and load tokenizer, model tokenizer = LlamaTokenizer.from_pretrained(model_name, device_map="auto") model = LlamaForCausalLM.from_pretrained(model_name, torch_dtype=torch_dtype, device_map="auto") def chat(message, history): input_text = message # Encode the input text using tokenizer encoded_input = tokenizer.encode(input_text, return_tensors='pt') encoded_input = encoded_input.to('cuda') # Inference start_time = time.time() outputs = model.generate(encoded_input, max_new_tokens=max_new_tokens) end_time = time.time() generated_text = tokenizer.decode( outputs[0], skip_special_tokens=True )
# Calculate number of tokens generated num_tokens = len(outputs[0].detach().cpu().numpy().flatten()) inference_time = end_time - start_time token_per_sec = num_tokens / inference_time print(f"Inference latency: {inference_time} sec") print(f"Token per sec: {token_per_sec}") return(generated_text)
# Launch gradio based chatinterface demo = gr.ChatInterface(fn=chat, title="Llama2 chatbot") demo.launch() |
| Here is the output conversation on the chatbot with prompt and results
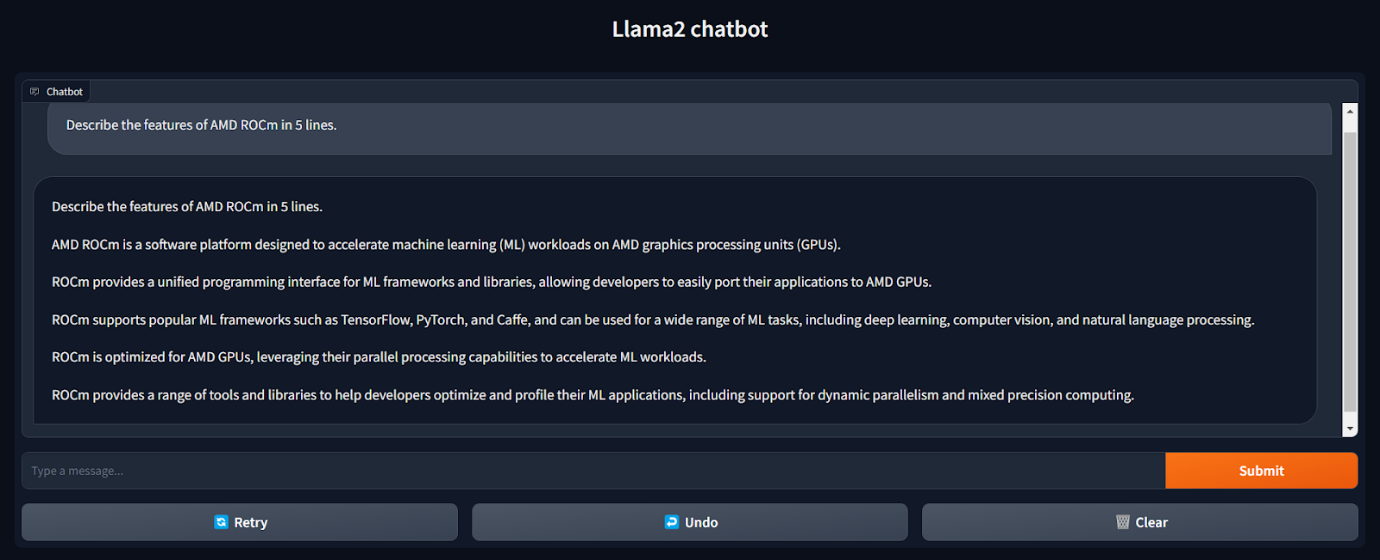
| Here is a view of AMD GPU utilization with rocm-smi
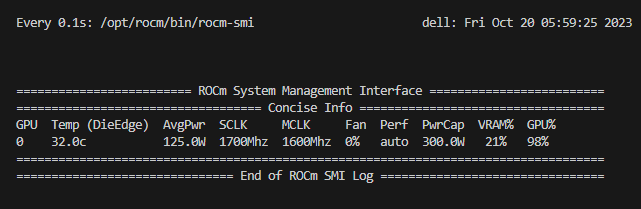
As you can see, using Hugging Face integration with AMD ROCm™, we can now deploy the leading large language models, in this case, Llama-2. Furthermore, the performance of the AMD Instinct™ MI210 meets our target performance threshold for inference of LLMs at <100 millisecond per token.
| “Scalers AI was thrilled to see the robust ecosystem emerging around ROCm that provides us with critical choice and exceeds our target <100 millisecond per user latency target on 7B parameter leading large language models!”
- Chetan Gadil, CTO, Scalers AI
In our next blog, we explore the performance of AMD ROCm™ and how we can accelerate AI research progress across industries with AMD ROCm™.
| Authors
Steen Graham, CEO of Scalers AI
Delmar Hernandez, Dell PowerEdge Technical Marketing
Mohan Rokkam, Dell PowerEdge Technical Marketing

Do We Always Need GPUs for AI Workloads?
Sun, 10 Sep 2023 15:52:30 -0000
|Read Time: 0 minutes
Graphics Processing Units (GPUs) have long been the preferred choice for accelerating AI workloads, especially deep learning tasks. However, the assumption that GPUs are indispensable for all AI applications merits a closer examination.
In this blog, we shift the focus to Central Processing Units (CPUs), delve into the role of CPU performance in AI workloads, and investigate scenarios where CPUs might offer competitive or even superior performance compared to GPUs.
To measure the performance of AI inference workload types on CPUs, we used the TensorFlow benchmark. TensorFlow is a benchmark with implementations of popular convolutional neural networks for large-scale image recognition (VGG-16, AlexNet, GoogLeNet, and ResNet-50) and various batch sizes (16, 32, 64, 256, and 512). It is designed to support workloads running on a single machine as well as workloads running in distributed mode across multiple hosts. The study looks at all subtests in TensorFlow.
We looked at the performance trend that each model shows for the different batch sizes to decide which of the 1-socket PowerEdge R7615 and 2-socket PowerEdge R7625 versions is suitable for a CPU-based AI inference type of workload.
The following figures show the performance of convolutional models on different batch sizes in the balanced, 12-DIMMs-per-socket configuration with memory capacity of 64 GB per DIMM in PowerEdge 7625 and 7615 with 4th Gen AMD EPYC 9654 and 9654P processors:

Figure 1. Performance of convolutional models on different batch sizes in a balanced, 12-DIMMs-per-socket configuration with memory capacity of 64 GB per DIMM with default BIOS settings
The batch size can vary depending on several factors, including the specific application, available computational resources, and hardware constraints. Generally, larger batch sizes are preferred because they offer better parallelization and computational efficiency, but they also require more memory. As we can see in the line graphs, the 2-socket server (PowerEdge R7625) outperforms the 1-socket server (PowerEdge R7615) by up to 150 percent in smaller batch sizes.
We found that the performance of smaller batch sizes is great in CPUs and suggest that our customers buy that configuration based on performance, business requirements and future scalability.
In practice, the choice between CPU-based and GPU-based AI inference depends on the specific requirements of the application. Some AI workloads benefit more from the parallel processing capabilities of GPUs, while others may prioritize low latency and versatile processing, which CPUs can provide.
Ultimately, the choice between using GPUs or CPUs for AI workloads should be based on a thorough understanding of the workload's characteristics, performance requirements, available hardware, and budget considerations. In some cases, a combination of different hardware components might also be a viable solution to optimize performance and cost.
You can find more about this on CPU-based AI inference | Workload-Based DDR5 Memory Guidance for Next-Generation PowerEdge Servers | Dell Technologies Info Hub.
Author: Swaraj Mohapatra