




Unlocking the power of synthetic data generation using Llama 3.1 405B models on Dell PowerEdge XE9680

Introduction
In the era of data-driven innovation, high-quality, diverse, and relevant data is the lifeblood of artificial intelligence (AI) and machine learning (ML) model development. However, the challenges of collecting and labeling real-world data are well-known: it is a time-consuming, expensive, and is often an improbable task due to privacy, security, and logistical constraints.
Enter Synthetic Data Generation: A Game-Changer for AI and ML
Synthetic data generation [1] [2] is a revolutionary technology that allows us to create artificial data that mimics real-world data, but with greater control, flexibility, and scalability. This technology has the potential to transform the way we develop and train AI and ML models.
Knowledge Transfer and Distillation with Synthetic Data Generation
One of the most exciting applications of synthetic data generation is knowledge transfer and distillation. By generating synthetic data that mimics the characteristics of a target domain, developers can:
- Fine-tune pre-trained models: Improve the performance and adaptability of pre-trained models on specific tasks or domains.
- Distill knowledge: Transfer knowledge from large, complex models to smaller, more efficient models, making them more suitable for real-world deployment.
- Reduce training data requirements: Train models on smaller, more manageable datasets, thereby reducing the need for large amounts of training data.
In this blog, we will harness the capabilities of Llama 3.1 collection of models by utilizing llama3.1- 405B instruct and Llama 3.1- 8B instruct on Dell PowerEdge XE9680 [3] to create high-quality synthetic data for generating Frequently Asked Questions (FAQs) in the educational domain. To ensure the generated data meets the highest standards, we will also utilize Llama 3.1- 405B as a judge to reward and refine the output. By generating high-quality synthetic data that mimics the characteristics of the target domain, we aim to demonstrate the potential of synthetic data generation for knowledge transfer and distillation.
Experimental setup
Our experiments were conducted on two Dell PowerEdge XE9680 servers, each hosting a different Llama model configuration. The first server ran Llama 3.1- 405B instruct with FP8 instructions, while the second server ran Llama 3.1- 8B instruct. Both systems have the configuration detailed in Table 1.
Table 1: Experimental Configuration for one Dell PowerEdge XE9680
Component | Details |
Hardware | |
Compute server for inferencing | PowerEdge XE9680 |
GPUs | 8x NVIDIA H100 80GB 700W SXM5 |
Host Processor Model Name | Intel(R) Xeon 8468 (TDP 350W) |
Host Processors per Node | 2 |
Host Processor Core Count | 48 |
Host Memory Capacity | 16x 64GB 4800 GHz RDIMMs |
Host Storage Type | SSD |
Host Storage Capacity | 4x 1.92TB Samsung U.2 NVMe |
Software | |
Operating System | Ubuntu 22.04.3 LTS |
CUDA | 12.1 |
CUDNN | 9.1.0.70 |
NVIDIA Driver | 550.90.07 |
Framework | PyTorch 2.5.0 |
In this step-by-step guide, we take you through a comprehensive code base that leverages the open-source framework Distilabel [4] to generate synthetic data for generating FAQs in the educational domain. To ensure a seamless and efficient execution, we will be utilizing the powerful Dell Enterprise Hub optimized containers on our Dell PowerEdge XE9680 servers, allowing us to run the models locally and tap into the full potential of our hardware.
Use Case: Generating Frequently Asked Questions (FAQ) from a text dataset.
Our example dataset (at HuggingFace) consists of long educational texts. The goal is to generate high-quality frequently asked questions (FAQs) from each of the text. Figure 1 illustrates the key components of our process, which can be broadly divided into two main stages:
1) Synthetic response generated using LLM’s (Llama 3.1 8B instruct and Llama 3.1 405B instruct)
2) Rating response with LLM as a judge (Llama 3.1 405B instruct)
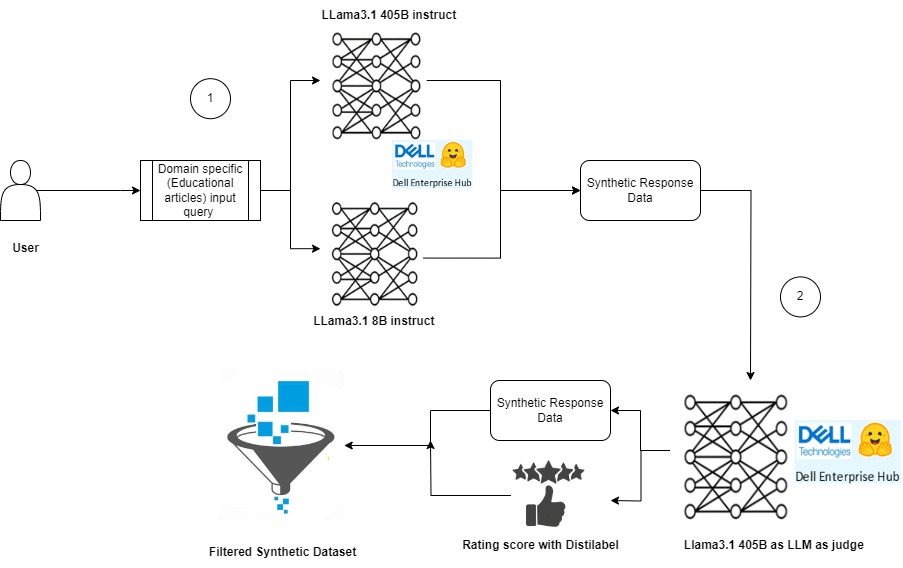
Figure 1 : Synthetic data generation pipeline using Llama models.
Below are steps followed to run the experiments.
Step 1: Model Deployment
We leveraged the Dell Enterprise Hub to deploy the models by running the containers, Llama 3.1- 405B instruct and Llama 3.1- 8B instruct. The following command was used to execute the Docker containers.
Docker container running Meta-Llama3.1- 405B instruct
docker run \ -it \ --gpus 8 \ --shm-size 1g \ -p 80:80 \ -e NUM_SHARD=8 \ -e MAX_BATCH_PREFILL_TOKENS=16182 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
Docker container running Meta-Llama3.1-8B instruct
docker run \ -it \ --gpus 4 \ --shm-size 1g \ -p 80:80 \ -e NUM_SHARD=8 \ -e MAX_BATCH_PREFILL_TOKENS=16182 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-8B-instruct
Step 2: Experiment Dataset
To demonstrate the capabilities of Distilabel in generating synthetic data, we created a sample dataset consisting of 10 rows of text data. In addition to the text itself, we included a column to display the token length of each text sample, providing insight into the size and complexity of the data.
Guidance for Synthetic Data Generation
To facilitate the generation of synthetic data, we also added a system_prompt column to the dataset. This column will be utilized by Distilabel to provide guidance on generating high-quality synthetic data that mimics the characteristics of the original dataset.
Dataset Preview
Figure 2 shows screenshot of the dataset used in this experiment. The original dataset can be accessed here for further exploration.
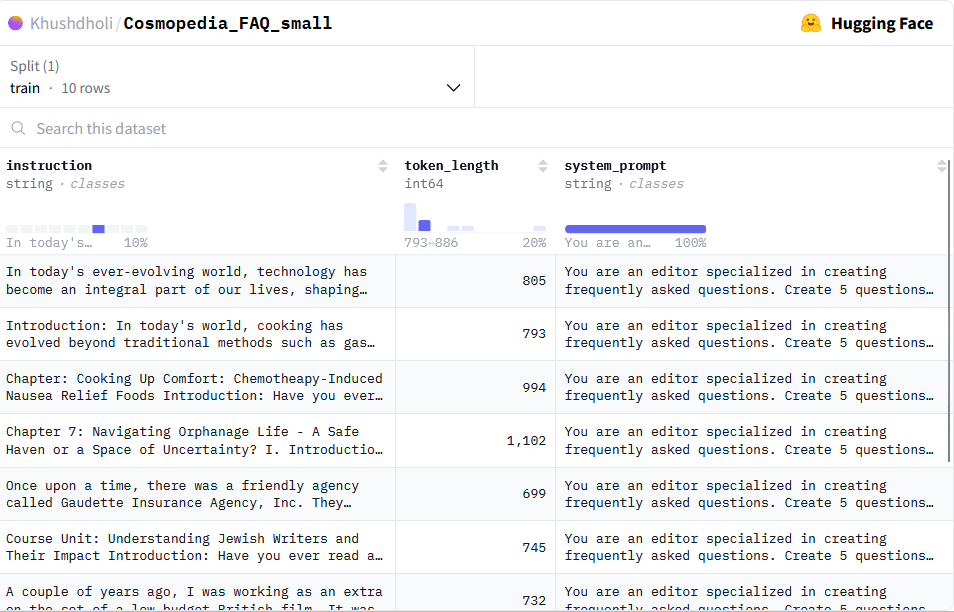
Figure 2:Screenshot of the educational dataset used as an input for generating the FAQ synthetic data.
Step 3: Generating Synthetic Data with Llama 3.1 collection models.
Get started with the code base to generate high-quality synthetic data using the powerful Llama 3.1-405B and Llama 3.1-8B models. Below are the steps followed in the code to build this pipeline to build:
- Load Dataset with Instructions
Loaded the dataset with instructions from Hugging Face Hub using the LoadDataFromHub class. - Generate Responses with Llama 3.1 Models
Utilize the TextGeneration task to generate two responses with InferenceEndpointsLLM Dell Enterprise Hub LLMs for each prompt, leveraging the capabilities of both the 405B and 8B models. - Combine Responses
Combine the two responses into a list of responses using the GroupColumns class. - Compare and Rate Responses
Use the UltraFeedback class from Distilabel framework for LLM-as-a-judge task with the 405B model to compare and rate the responses, providing valuable insights into the quality of the generated data.
The following are the prerequisites to be installed before running the final code base.
![!pip install distilabel[hf-inference-endpoints] -U -qqq!pip install -U distilabel!pip install distilabel --upgrade](/static/media/d453766c-0d3c-4bc9-813b-daea4955e568.png)
Below, is the code base that will guide you through this process. Follow along to learn how to build a synthetic data generation pipeline. pipelines.
from distilabel.llms import InferenceEndpointsLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import LoadDataFromHub
from distilabel.steps.tasks import TextGeneration, UltraFeedback
from distilabel.steps import CombineColumns, GroupColumns
from langchain_community.llms import HuggingFaceEndpoint
#loading llama3.1-8B model
Llama8B = InferenceEndpointsLLM(
api_key="hf_your_huggingface_access_token”
model_display_name="llama8B",
base_url="http://172.18.x.x:80",
generation_kwargs={
"max_new_tokens": 1024,
"temperature": 0.7
}
)
#loading llama3.1-405B model
llama405B = InferenceEndpointsLLM(
api_key="hf_your_huggingface_access_token",
model_display_name="llama405B",
base_url="http://172.18.y.y:80",
generation_kwargs={
"max_new_tokens": 1024,
"temperature": 0.7
}
)
with Pipeline(name="synthetic-data-with-llama3.1") as pipeline:
# load dataset with prompts
load_dataset = LoadDataFromHub(
repo_id= "Khushdholi/Cosmopedia_FAQ_small", split="train"
)
# Generate two responses
generate = [
TextGeneration(llm=llama8B),
TextGeneration(llm=llama405B)
]
combine = GroupColumns(
columns=["generation", "model_name"],
output_columns=["generations", "model_names"]
)
# rate responses with 405B LLM-as-a-judge
rate = UltraFeedback(aspect="overall-rating", llm=llama405B)
# define and run pipeline
load_dataset >> generate >> combine >> rate
# load_dataset >> generate >> rate
distiset = pipeline.run(use_cache=False)Step 4: Evaluating Generated Data with Llama 3.1-405B as LLM as the judge.
To assess the quality of our generated FAQs, we will leverage Llama 3.1-405B as our judge, rating the outputs on a scale of 1-5, with 5 indicating exceptional results. This rigorous evaluation process enables us to:
- Rate the results of both Llama 3.1-405B instruct and Llama 3.1-8B instruct models on the given task.
- Refine our synthetic data generation process to produce high-quality outputs.
Accessing the Synthetic Data
The generated synthetic data is available for exploration here. Figure 3 showcases an example of FAQ generated by these models and also rationales generated by LLM as a judge to rate it.

Figure 3: An example showing the long text about education article on left and FAQ generated by models and also rationales given by judging model
Rating Rationale and Results
Figure 4 is a screenshot that captures the rationale behind the rating, along with metadata on the generated data, and a set of questions generated by both models. This representation allows us to:
- Identify which set of questions rank higher with the given text.
- Gain insights into the quality of our synthetic data generation process by using the meta data information collected during this process.
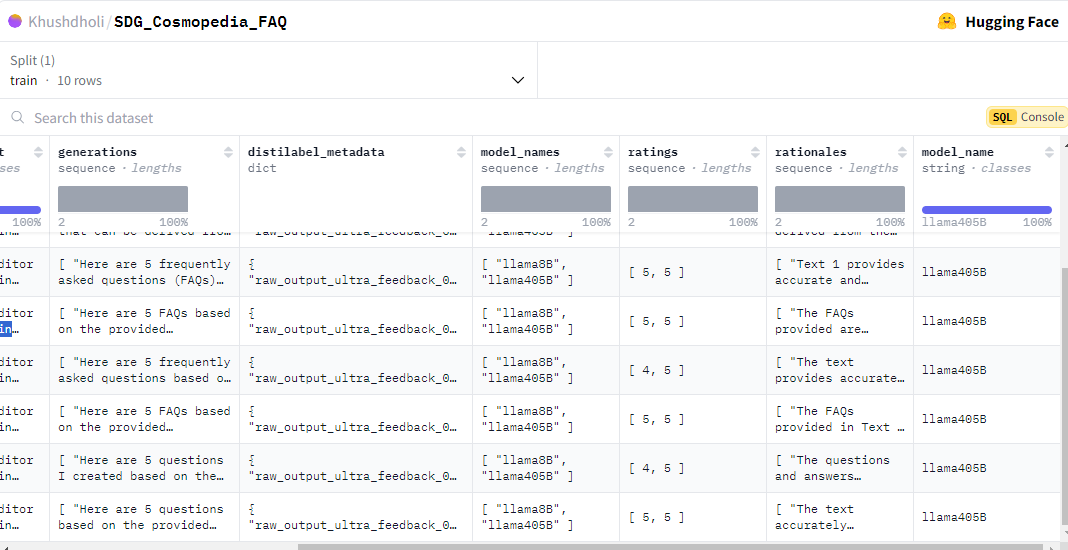
Figure 4: Screenshot of the output Synthetic data generation.
Conclusion
In this blog, we have explored the exciting world of synthetic data generation with Llama 3.1-405B and Llama 3.1-8B on Dell PowerEdge XE9680 by running these models locally. We also showcase the value of using Llama 3.1-405B as a judge to refine and reward high-quality synthetic data. You can clone our code base, access the synthetic data generated in this blog, and start exploring the world of synthetic data generation with Llama 3.1 and Dell PowerEdge XE9680.
In upcoming work, we will demonstrate the potential of using this synthetic data generation for knowledge transfer and distillation in the form of fine-tuning a small model.
References
[1] Comprehensive Exploration of Synthetic Data Generation https://arxiv.org/abs/2401.02524
[2] Machine Learning for Synthetic Data Generation https://arxiv.org/abs/2302.04062
[3] https://www.dell.com/en-us/shop/ipovw/poweredge-xe9680
[4] https://distilabel.argilla.io/latest/
Author: Khushboo Rathi (khushboo.rathi@dell.com)