




Unlocking the Power of Large Language Models and Generative AI: A Dell and Run:ai Joint Solution
Tue, 30 Jan 2024 19:47:13 -0000
|Read Time: 0 minutes
In the fast-paced landscape of AI, the last year has undeniably been marked as the era of Large Language Models (LLMs), especially in the Generative AI (GenAI) field. Models like GPT-4 and Falcon have captured our imagination, showcasing the remarkable potential of these LLMs. However, beneath their transformative capabilities lie a substantial challenge: the insatiable hunger for computational resources.
The demand for compute: fueling innovation with computational power
GenAI applications span from media industry to software development, driving innovation across industries. OpenAI's release of GPT-3 was a turning point, demonstrating the capabilities of language models and their potential to revolutionize every sector. On one hand, startups and tech giants have introduced closed-source models, offering APIs for their usage, exemplified by OpenAI and GPT-4. On the other hand, an active open-source community has emerged, releasing powerful models such as Falcon and Llama 2. These models, both closed- and open-source, have spurred a wave of interest, with companies racing to use their potential.
While the promise of LLMs is enormous, they come with a significant challenge—access to high-performance GPUs. Enterprises aiming to deploy these models in their private data centers or cloud environments must contend with the need for substantial GPU power. Security concerns further drive the preference for in-house deployments, making GPU accessibility critical.
The infrastructure required to support LLMs often includes high-end GPUs connected through fast interconnects and storage solutions. These resources are not just expensive and scarce but are also in high demand, leading to bottlenecks in machine learning (ML) development and deployment. Orchestrating these resources efficiently and providing data science and ML teams with easy and scalable access becomes a Herculean task.
Challenges with GPU allocation
In this landscape, GPUs are the backbone of the computational power that fuels these massive language models. Due to the limited availability of on-premises and cloud resources, the open-source community has taken steps to address this challenge. Libraries like bits and bytes (by Tim Dettmers) and ggml (by Georgi Gerganov) have emerged, using various optimization techniques such as quantization to fine-tune and deploy these models on local devices.
However, the challenges are not limited to model development and deployment. These LLMs demand substantial GPU capacity to maintain low latency during inference and high throughput during fine-tuning. In the real world, the need for capacity means having an infrastructure that dynamically allocates GPU resources to handle LLM fine-tuning and inference operations, all while ensuring efficiency and minimal wasted capacity.
As an example, consider loading LLama-7B using half precision (float16). Such a model requires approximately 12GB of GPU memory─a figure that can be even lower with the use of lower precision. In instances where high-end GPUs, like the NVIDIA A100 GPU with 40 GB (or 80 GB) of memory, are dedicated solely to a single model, severe resource waste results, especially when done at scale. The wasted resource does not only translate to financial inefficiencies but also reduced productivity in data science teams, and an increased carbon footprint due to the excessive underutilization of running resources over extended periods.
Some LLMs are so large that they must be distributed across multiple GPUs or multiple GPU servers. Consider Falcon-180B using full precision. Such a model requires approximately 720 GB and the use of more than 16 NVIDIA A100 GPUs with 40 GB each. Fine tuning such models and running them in production requires tremendous computing power and significant scheduling and orchestration challenges. Such workloads require not only a high-end compute infrastructure but also a high-end performant software stack that can distribute these workloads efficiently without bottlenecks.
Apart from training jobs, serving these models also requires efficient autoscaling on hardware. When there is high demand, these applications must be able to scale up to hundreds of replicas rapidly, while in low demand situations, they can be scaled down to zero to save costs.
Optimizing the management of LLMs for all these specific needs necessitates a granular view of GPU use and performance as well as high-level scheduling view of compute-intensive workloads. For instance, it is a waste if a single model like LLama-7B (12 GB) is run on an NVIDIA A100 (40GB) with almost 60 percent spare capacity instead of using this remaining capacity for an inference workload.
Concurrency and scalability are essential, both when dealing with many relatively small, on-premises models, each fine-tuned and tailored to specific use cases as well as when dealing with huge performant models needing careful orchestration. These unique challenges require a resource orchestration tool like Run:ai to work seamlessly on top of Dell hardware. Such a solution empowers organizations to make the most of their GPU infrastructure, ensuring that every ounce of computational power is used efficiently. By addressing these challenges and optimizing GPU resources, organizations can harness the full potential of LLMs and GenAI, propelling innovation across various industries.
Dell Technologies and Run:ai: joint solution
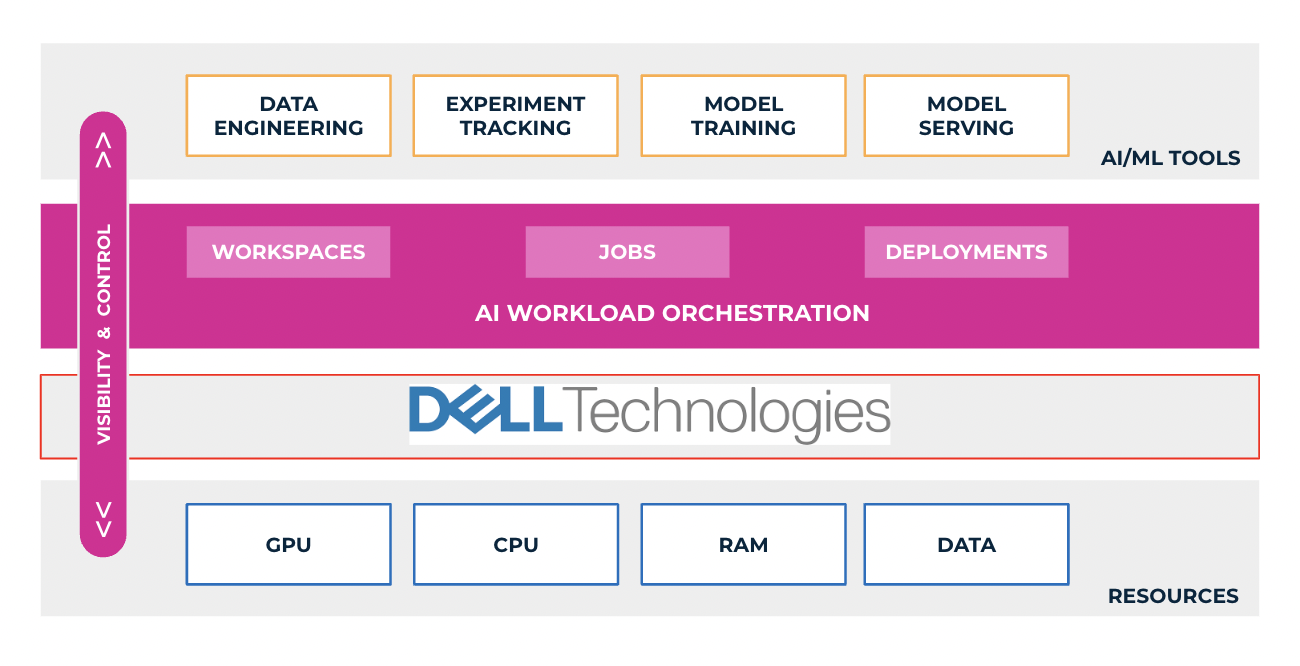
To address these bottlenecks, which hinder the rapid adoption of GenAI in organizations, Run:ai, a compute orchestration solution, teams up with Dell Technology.
The Dell Generative AI Solutions portfolio, a comprehensive suite of Dell products and services (Dell PowerEdge XE9680, PowerEdge 760XA, and PowerEdge XE8640 servers) in collaboration with NVIDIA, enables customers to build GenAI models on-premises quickly and securely, accelerate improved outcomes, and drive new levels of intelligence. Dell Validated Designs for Generative AI now support both model tuning and inferencing, allowing users to deploy GenAI models quickly with pretested and proven Dell infrastructure, software, and services to power transformative business outcomes with GenAI. The Validated designs integrate end-to-end AI solutions including all the critical components (server, networking, storage, and software) for AI systems, while Run:ai introduces two key technological components that unlock the true potential of these AI models: GPU optimization and a sophisticated scheduling system for training and inference workloads. Extending the Dell GenAI approaches with Run:ai orchestration enables customers to optimize GenAI and AI operations to build and train AI models and run inferencing with greater speed and efficiency.
AI-optimized compute: maximizing GPU utilization
Dell Technologies offers a range of acceleration-optimized PowerEdge servers, purpose-built for high-performance workloads like AI and demanding use-cases in generative AI, as part of the extensive server portfolio that supports various NVIDIA GPUs. Dell PowerEdge servers advance accelerated compute to drive enhanced AI workload outcomes with greater insights, inferencing, training, and visualization. However, one of the primary challenges in training and deploying LLMs is GPU use. Together with Dell PowerEdge servers, Run:ai's GPU optimization layer enables features like fractionalizing GPUs and GPU oversubscription. These features ensure that multiple workloads (training and inference), even small models, can efficiently run on the same GPU. By making better use of existing GPU resources, costs are reduced, and bottlenecks are mitigated.
Advanced scheduling: efficient workload management
Run:ai's advanced scheduling system integrates seamlessly into Kubernetes environments on top of PowerEdge servers. It is designed to tackle the complexities that arise when multiple teams and users share a GPU cluster and when running large multi-GPU or multi-node workloads. The scheduler optimizes resource allocation, ensuring efficient utilization of GPUs among various workloads, including training, fine-tuning, and inference.
Autoscaling and GPU optimization for inference workloads
Run:ai's autoscaling functionality enables dynamic adjustments to the number of replicas, allowing for efficient scaling based on demand. In times of increased workload, Run:ai optimally uses the available GPU, scaling up the replicas to meet performance requirements. Conversely, during periods of low demand, the number of replicas can be scaled down to zero, minimizing resource use and leading to cost savings. While there might be a brief cold start delay with the first request, this approach provides a flexible and effective solution to adapt to changing inference demands while optimizing costs.
Beyond autoscaling, deploying models for inference using Run:ai is a straightforward process. Internal users can effortlessly deploy their models and access them through managed URLs or user-friendly web interfaces like Gradio and Streamlit. This streamlined deployment process facilitates sharing and presentation of deployed LLMs, fostering collaboration and delivering a seamless experience for stakeholders.
AI networking
To achieve high throughput in multi-node training and low latency when hosting a model on multiple machines, most GenAI models require robust and highly performant networking capabilities on hardware, which is where Dell's networking capabilities and offerings come into play. The network interconnects the compute nodes among each other to facilitate communications during distributed training and inferencing. The Dell PowerSwitch Z-series are high-performance, open, and scalable data center switches ideal for generative AI, as well as NVIDIA Quantum InfiniBand switches for faster connectivity.
Fast access to your data
Data is a crucial component for each part of the development and deployment steps. Dell PowerScale storage supports the most demanding AI workloads with all-flash NVMe file storage solutions that deliver massive performance and efficiency in a compact form factor. PowerScale is an industry-leading storage platform purpose-built to handle massive amounts of unstructured data, ideal for supporting datatypes required for generative AI.
Streamlined LLM tools
To simplify the experience for researchers and ML engineers, Run:ai offers a suite of tools and frameworks. They remove the complexities of GPU infrastructure with interfaces like command-line interfaces, user interfaces, and APIs on top of Dell hardware. With these tools, training, fine-tuning, and deploying models become straightforward processes, enhancing productivity, and reducing time-to-market. As a data scientist, you can take pretrained models from the Huggingface model hub and start working on them with your favorite IDE and experiment with management tools in minutes, a testament to the efficiency and ease of the Dell and Run:ai solution.
Benefits of the Dell and Run:ai solution for customers
Now that we have explored the challenges posed by LLMs and the joint solution of Dell Technologies and Run:ai to these bottlenecks, let's dive into the benefits that this partnership between Dell Technologies and Run:ai and offers to customers:
1. Accelerated time-to-market
The combination of Run:ai's GPU optimization and scheduling solutions, along with Dell's robust infrastructure, significantly accelerates the time-to-market for AI initiatives. By streamlining the deployment and management of LLMs, organizations can quickly capitalize on their AI investments.
2. Enhanced productivity
Data science and ML engineering teams, often unfamiliar with the complexities of AI infrastructure, can now focus on what they do best: building and fine-tuning models. Run:ai's tools simplify the process, reducing the learning curve and improving productivity.
3. Cost efficiency
Optimizing GPU use not only provides performance but also provides cost-effectiveness. By running multiple workloads on the same GPU, organizations can achieve better cost efficiency, get the most out of their infrastructure, thus making AI initiatives more financially viable.
4. Increased scalability and GPU availability
Run:ai's advanced scheduling system ensures that workloads are efficiently managed, even during peak demand. This scalability is crucial for organizations that need to serve language models in real time to a growing user base. In addition, the scheduling component ensures fair and optimized allocation of GPU resources between multiple users, teams, and tasks, preventing resource bottlenecks and contention and increasing availability of GPUs to allow more users, teams, and AI services to get access and use available GPU resources effectively.
5. Innovation unleashed
The solution empowers enterprise teams to innovate and experiment with LLMs and GenAI without being hindered by infrastructure complexities. Researchers and ML engineers can easily fine-tune and deploy models using abstraction tools, fostering innovation and exploration in AI projects.
Summary
The joint solution offered by Dell Technologies and Run:ai addresses the critical challenges faced by organizations ramping up with GenAI for their business needs and working with LLMs. By enhancing GPU accessibility, optimizing scheduling, streamlining workflows, and saving costs, this solution empowers businesses to fully harness the potential of LLMs in GenAI applications while simplifying the challenges. With AI initiatives becoming increasingly vital in today's world, this partnership offers businesses new ways to automate and simplify their GenAI strategy and drive more business innovation.
For information about how to get started with Dell Technologies and Run:ai on your GenAI journey, see these resources:
- Dell AI Solutions
- GPU Optimization with Run:ai Atlas technical whitepaper
- Accelerate AI by Optimizing Compute Resources
- Run:ai
Authors: Justin King, Ekin Karabulut
Contributor: James Yung