




Unlocking LLM Performance: Advanced Inference Optimization Techniques on Dell Server Configurations


Introduction
Large Language Models (LLMs) are advanced artificial intelligence models designed to understand and generate human-like text that is based on the input that they receive. LLMs comprehend and generate text in various languages. They are used in a wide range of applications, including natural language processing tasks, text generation, translation, summarization, and more. LLMs use a transformer architecture and are trained on immense amounts of data that enable them to perform tasks with high accuracy.
In today's business landscape, LLMs are essential for effective communication with customers, providing accurate and context-aware responses across various industries. However, concerns arise when considering cloud-based deployment due to data privacy and control issues. Organizations prioritize retaining full control over sensitive data, leading to a preference for on-premises solutions. This inclination is particularly pronounced in industries governed by strict compliance regulations mandating data localization and privacy, underscoring the importance of maintaining data integrity while using the capabilities of LLMs.
Background
The following figure illustrates the evolving trends in LLMs over recent years. Notably, there has been an exponential growth in the scale of LLMs, characterized by an increase from models with millions of parameters to models with billions or trillions of parameters. This expansion signifies a significant advancement in natural language processing capabilities, enabling LLMs to undertake increasingly complex linguistic tasks with enhanced accuracy and efficiency.
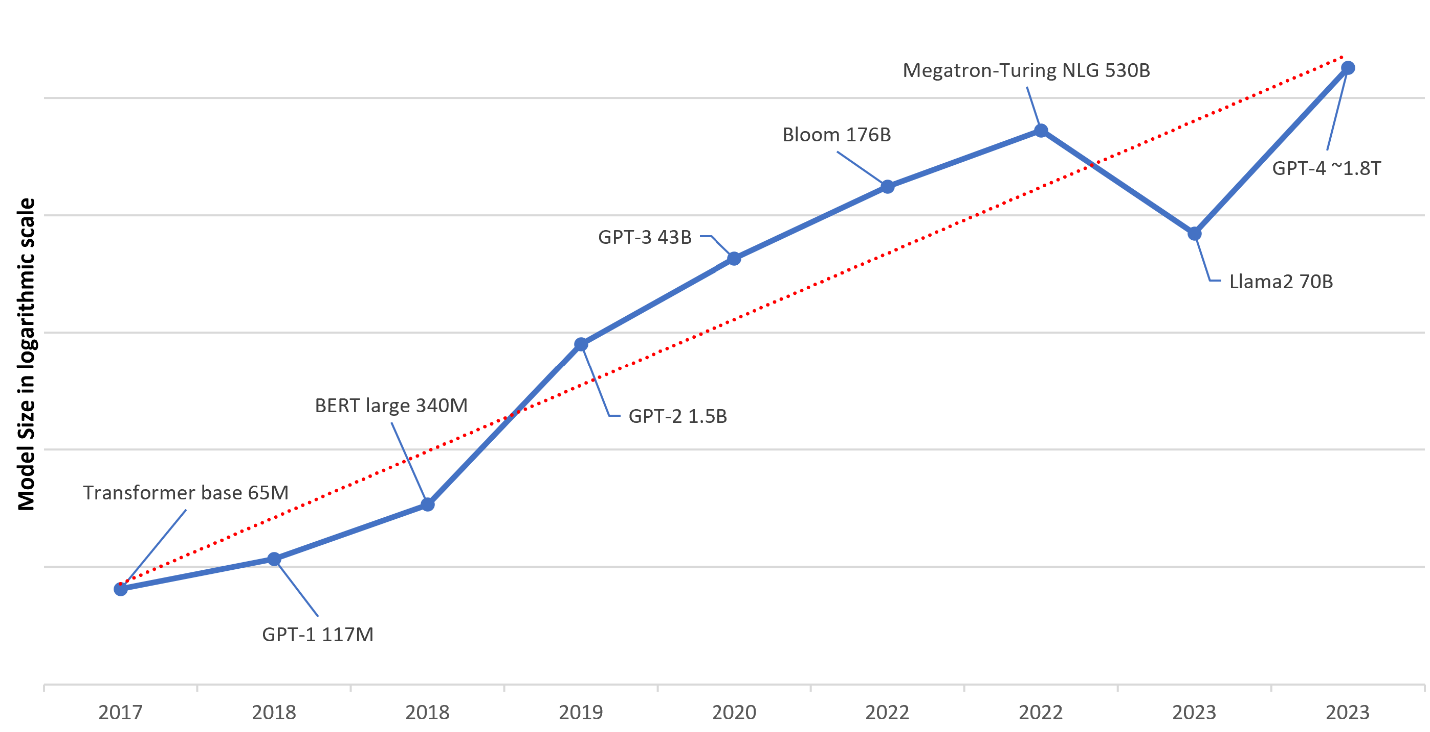
Figure 1: Parameters of LLMs in recent years
Running LLMs on premises can present its own set of challenges. The infrastructure must be robust and scalable enough to handle the computational demands of LLMs, which can be considerable, especially for models with large parameter sizes. This scenario requires significant upfront hardware investment and ongoing maintenance costs.
LLMs must be more cost effective to meet this requirement. This blog describes optimizing the deployment of LLMs on Dell servers, focusing on intricate performance enhancement techniques. Through meticulous experimentation across varied server configurations, we scrutinized the efficacy of methodologies such as iterative batching, sharding, parallelism, and advanced quantization. Our comparative analysis against the base model shows the nuanced impacts of these techniques on critical performance metrics like latency, throughput, and first-token latency. By using the throughput benchmark and first-token latency benchmark, we provide a detailed technical exploration into maximizing the efficiency of LLMs on Dell servers.
Objectives
The findings were derived from evaluating the performance metrics of the Llama13b-chat-hf model, focusing on throughput (tokens/sec), total response latency, first-token latency, and memory consumption. Input and output sizes are standardized at 512 tokens each. Testing encompassed various batch sizes to assess performance comprehensively across different scenarios.
Software setup
We investigated Llama-2-13b-chat-hf as the baseline model for our test results. We loaded the FP16 model from Hugging Face. After loading the model, we used NVIDIA NeMo with TensorRT-LLM to optimize the model and build TensorRT engines and run them on NVIDIA Triton Inference Server and NVIDIA GPUs. The TensorRT-LLM Python API mirrors the structure of the PyTorch API, simplifying development tasks. It offers functional and layers modules for assembling LLMs, allowing users to build models comparable to their PyTorch counterparts. To optimize performance and minimize memory use, NVIDIA TensorRT-LLM supports various quantization techniques, facilitated by the Algorithmic Model Optimization (AMMO) toolkit.
For more details about how to use NVIDIA TensorRT-LLM and Triton Inference Server, see the Convert HF LLMs to TensorRT-LLM for use in Triton Inference Server blog.
Hardware setup
The tests were performed on Dell PowerEdge R760xa servers powered by NVIDIA GPUs. We performed tests on two server configurations:
- PowerEdge R760xa server with four NVIDIA H100 GPUs
- PowerEdge R760xa server with four NVIDIA L40S GPUs
We posted the results of the following analyses to draw a comparison:
- Assessment of the impact of inference optimization and quantization on model performance
- Comparison between the performance of running a model on NVIDIA H100 GPUs compared to NVIDIA L40S GPUs
This analysis is crucial for determining the most suitable optimization technique for each specific use case. Also, it offers insights into the performance levels achievable with various GPU configurations, aiding in decisions about investment allocation and expected performance outcomes.
Inference optimization
Inference optimization in LLMs entails refining the data analysis and response generation process, enhancing operational efficiency. This optimization is critical for boosting LLM performance and ensuring its viability in real-world settings. It directly influences response time, energy consumption, and cost-effectiveness, underscoring its significance for organizations and developers seeking to integrate LLMs into their systems.
We applied a series of inference optimizations to enhance the performance of the foundational Llama2-13b model. These optimizations are designed to boost both throughput and latency. The following sections provide a comprehensive overview of these optimization techniques, detailing their implementation and impact on model efficiency.
LLM batching
LLM inferencing is an iterative process. You start with a prompt that is a sequence of tokens. The LLM produces output tokens until the maximum sequence length is achieved or it encounters a stop token. The following figure shows a simplified version of LLM inference. This example supports a maximum sequence length of eight tokens for a batch size of one sequence. Starting from the prompt token (yellow), the iterative process generates a single token (blue) at a time. When the model generates an end-of-sequence token (red), the token generation stops.
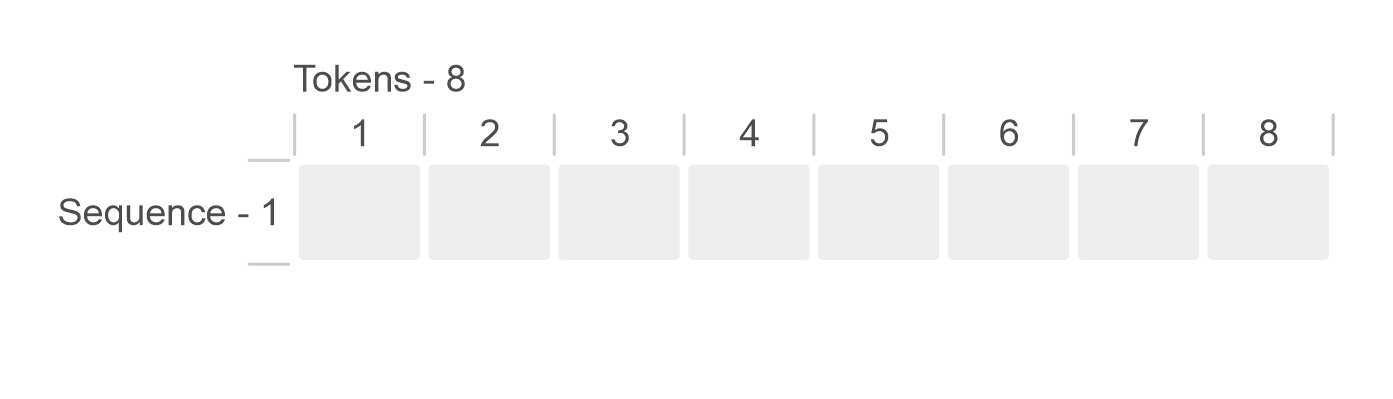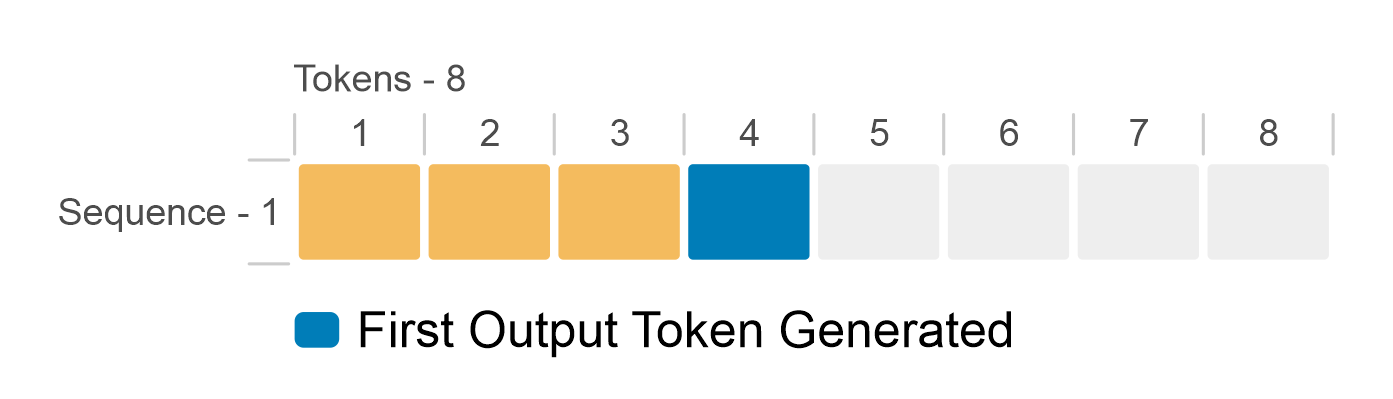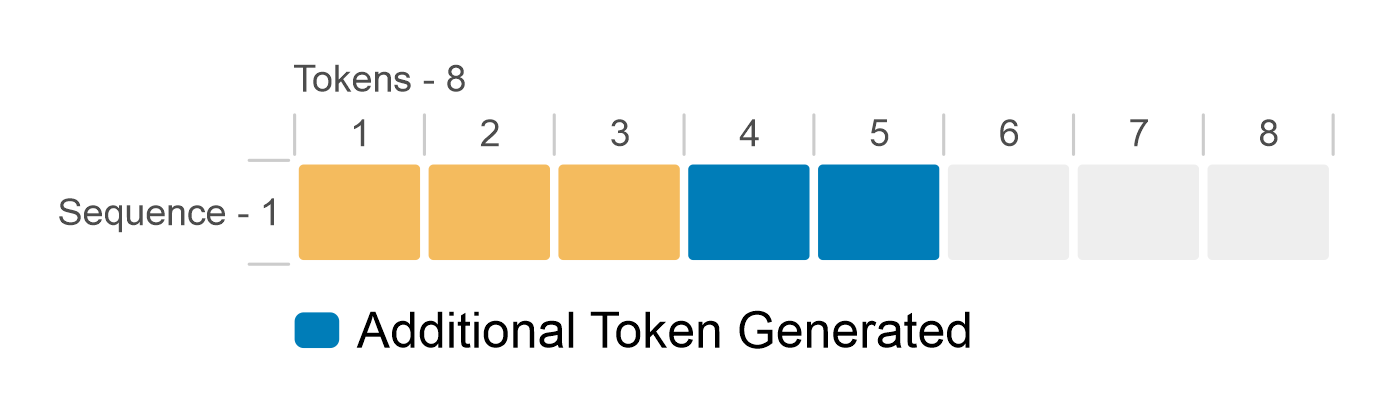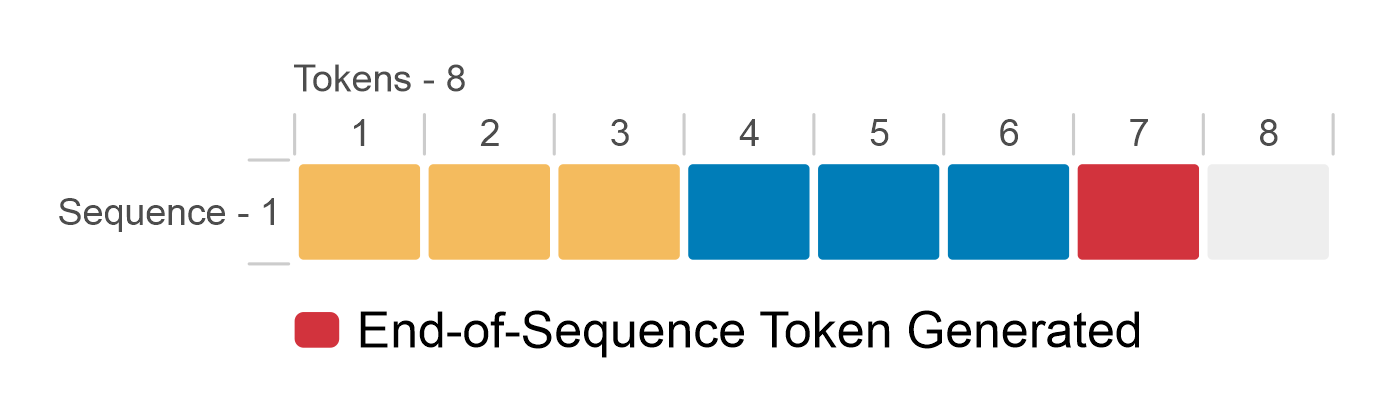
Figure 2: Simplified LLM inference
LLM inferencing is memory bound. The process of loading 1 MB of data onto GPU cores consumes more time compared to the actual computational tasks that those GPU cores perform for LLM computations. As a result, the throughput of LLM inference is contingent on the batch size that can be accommodated in the confines of GPU memory.
Native or static batching
Because a significant portion of time during inference is allocated to loading model parameters, a strategy emerges: rather than reloading model parameters for each new computation, we can load the parameters once and apply them to multiple input sequences. This method optimizes GPU memory use, enhancing throughput. Referred to as native batching or static batching, this approach maintains a consistent batch size throughout the entire inference process, resulting in more efficient resource use.
The following figure shows how native or static batching works for a batch size of four sequences. Initially, each sequence produces one token (shown in blue) per iteration until all sequences generate an end-of-sequence token. Although sequence 3 completes in only two iterations, GPU memory remains unused, with no other operations taking place.
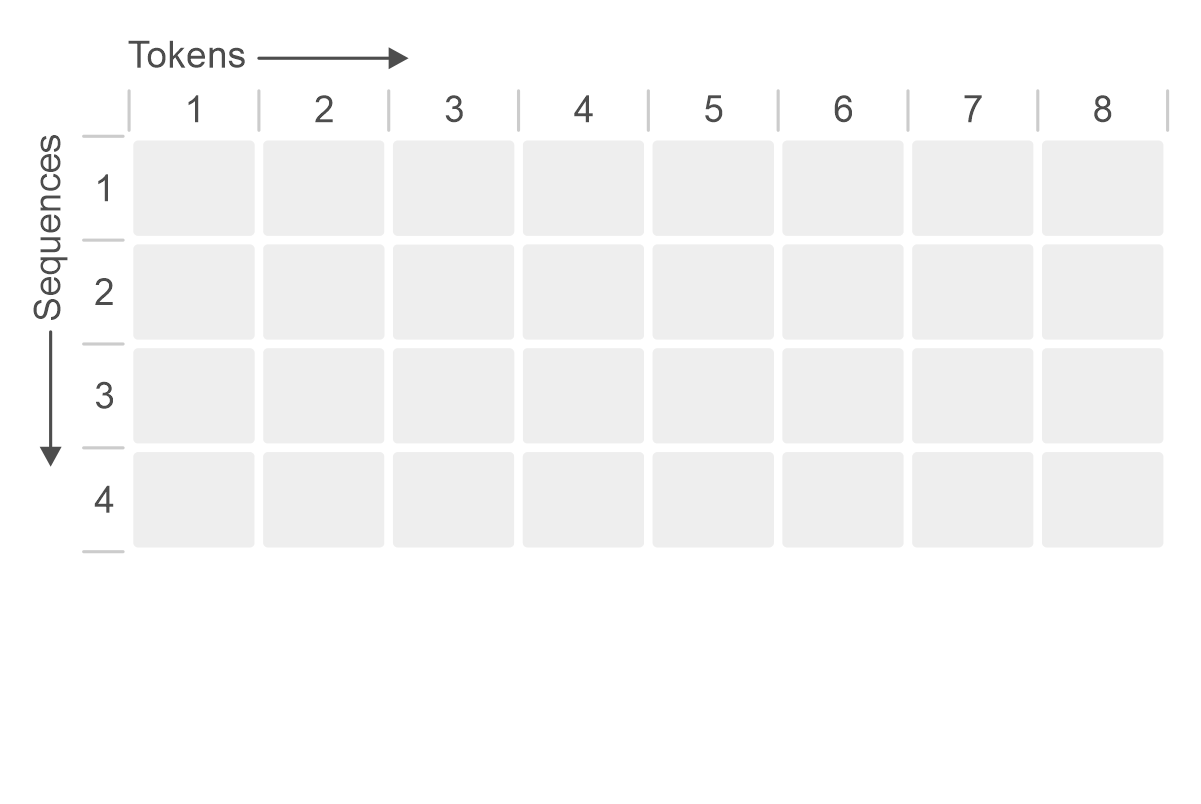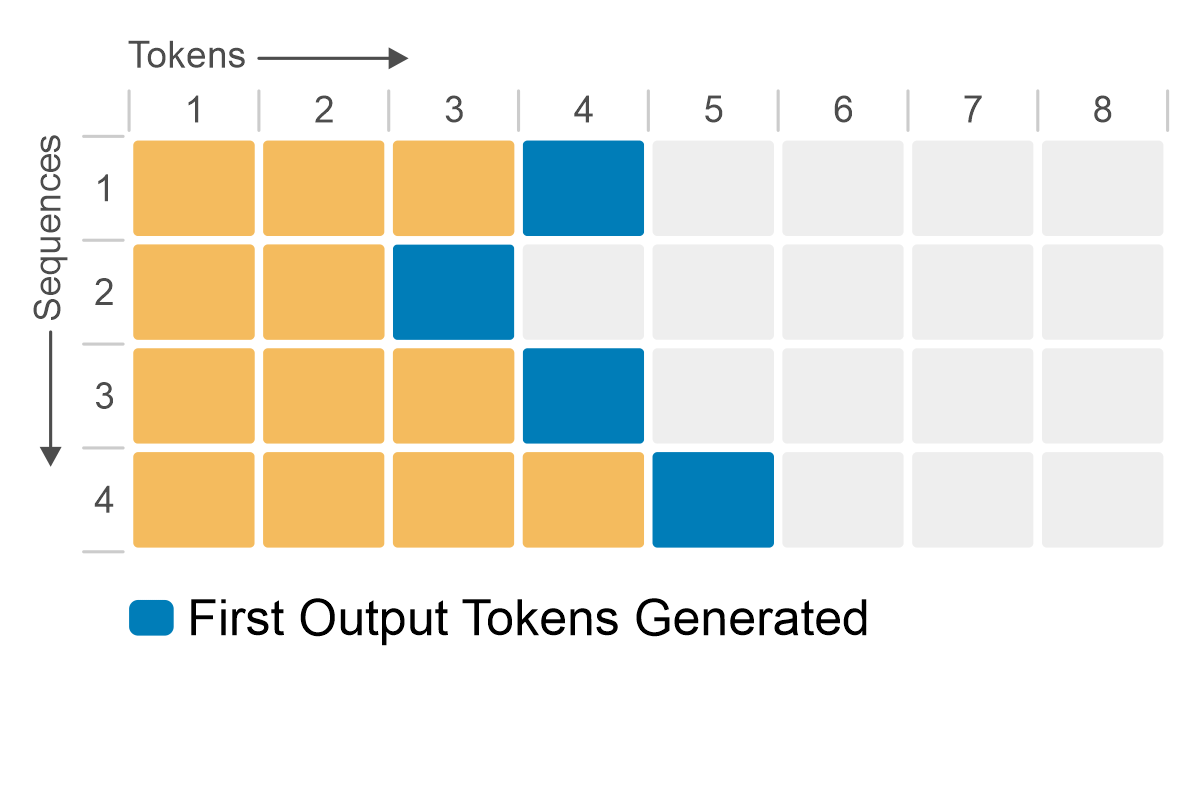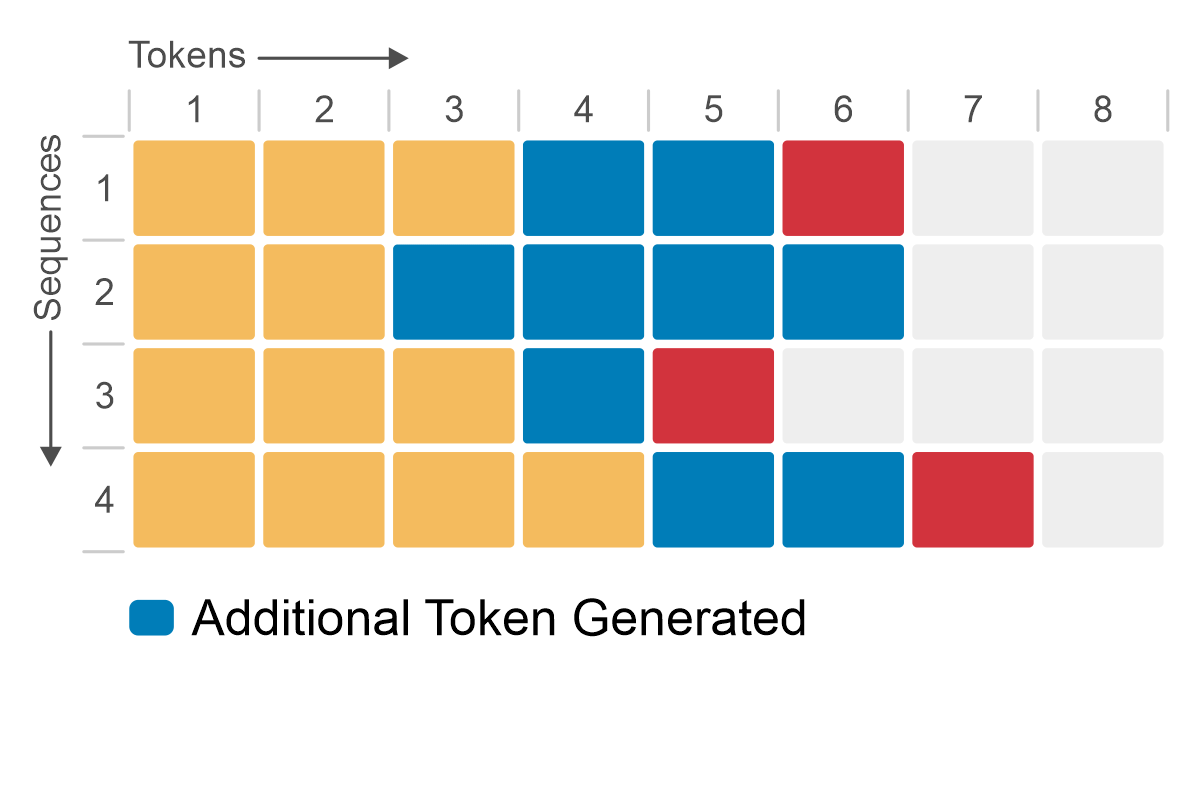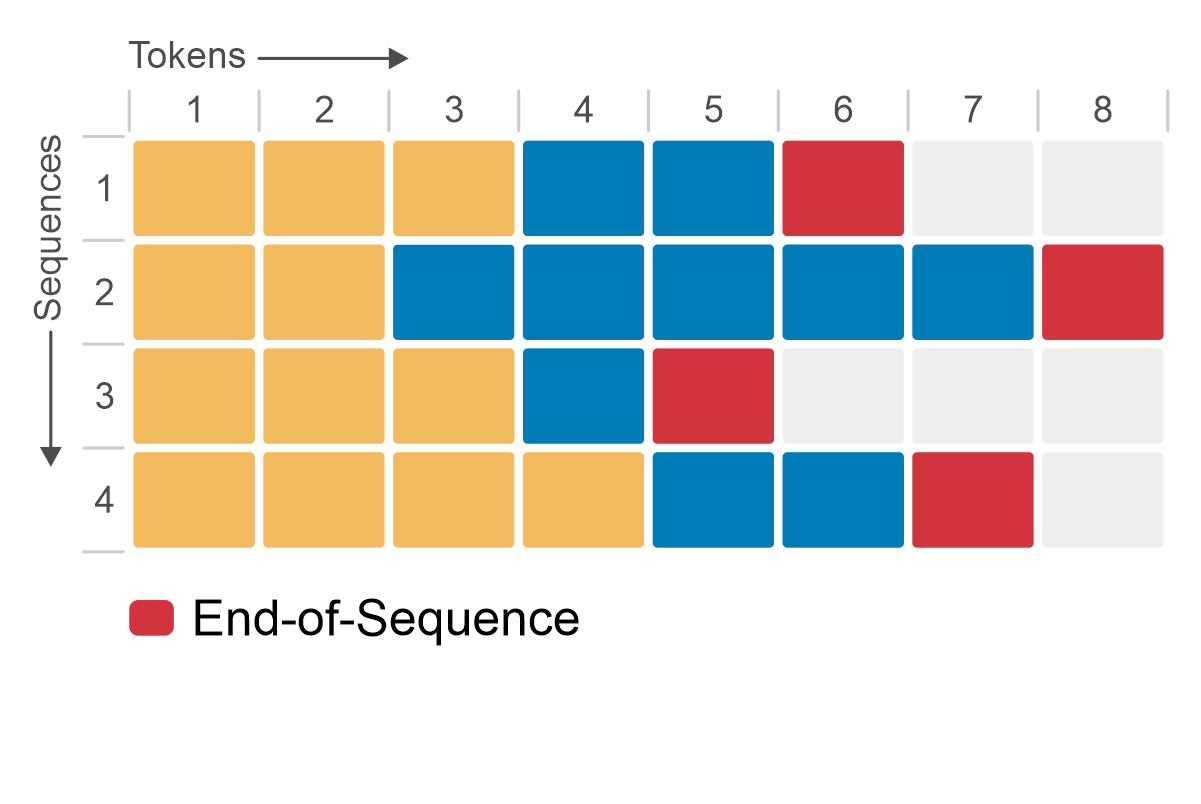
Figure 3: Native or static batching
The conventional batching method for LLM inference faced challenges due to its inflexibility in adapting to changing request dynamics. With this method, requests that were completed earlier in a batch did not immediately return to the client, causing delays for subsequent requests behind them in the queue. Moreover, newly queued requests had to wait until the current batch finished processing entirely, further exacerbating latency issues.
Iterative or continuous batching
To address these limitations, we introduced iterative or continuous batching techniques. These methods dynamically adjust the composition of the batch while it is in progress, allowing for more efficient use of resources and reducing latency. With iterative batching, requests that finish earlier can be immediately returned to the client, and new requests can be seamlessly incorporated into the ongoing batch processing, without waiting for the entire batch to be completed.
The following figure shows how iterative or continuous batching uses GPU memory. When a sequence presents an end-of-sequence token, a new sequence is inserted. This iterative approach significantly improves performance compared to conventional batching, all while maintaining the same latency requirements. By using dynamic batch management, iterative batching optimizes resource use and enhances responsiveness, making it a preferred choice for LLM inference tasks where adaptability and efficiency are paramount.
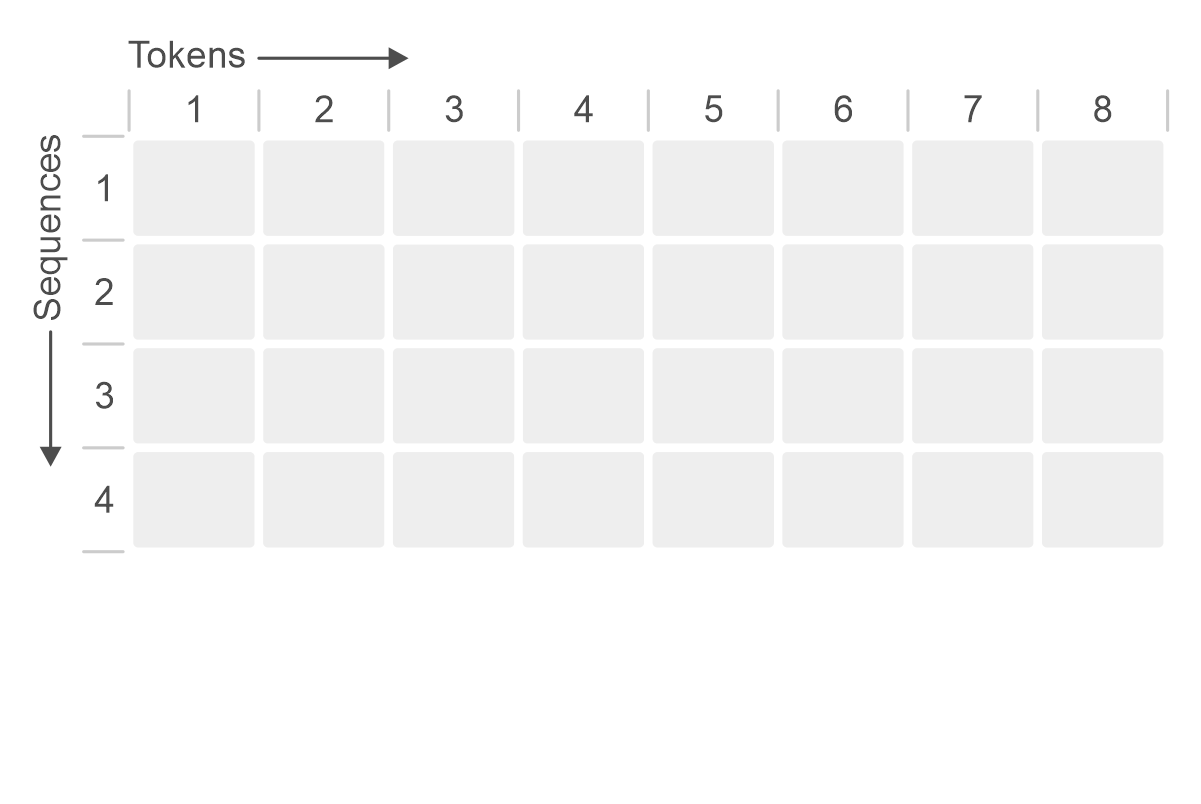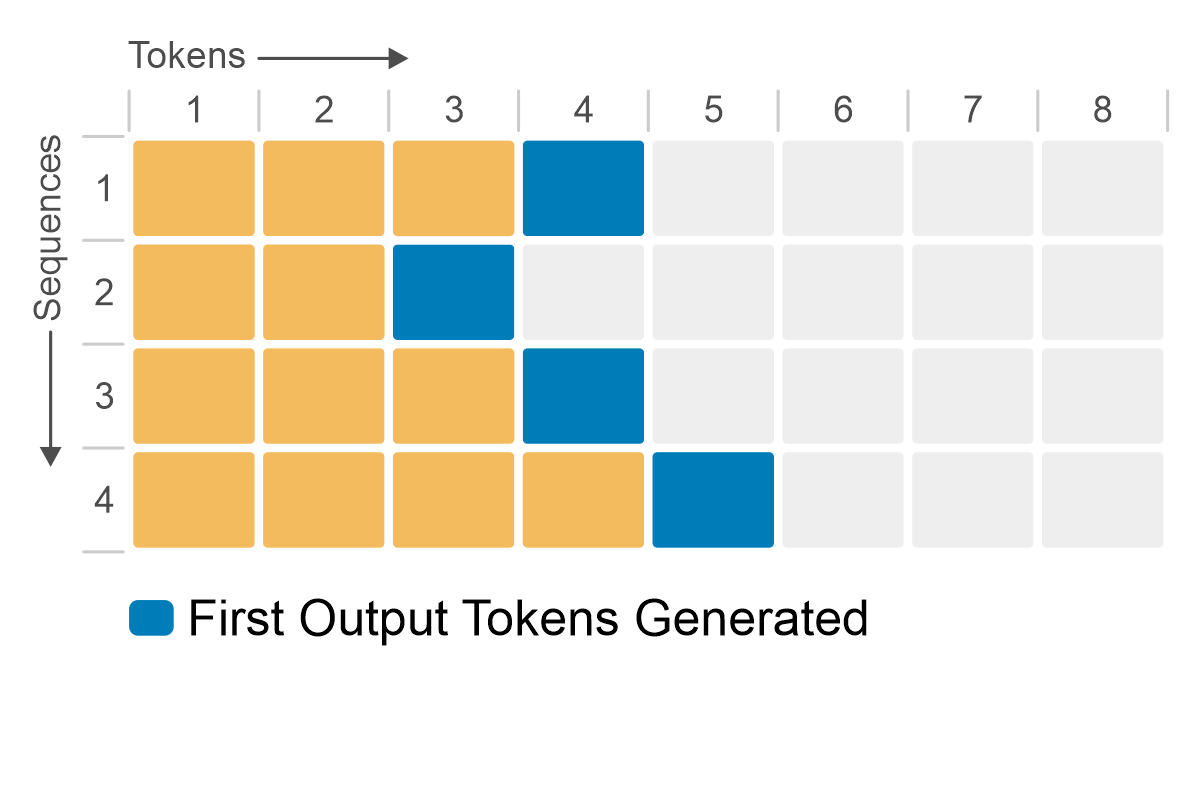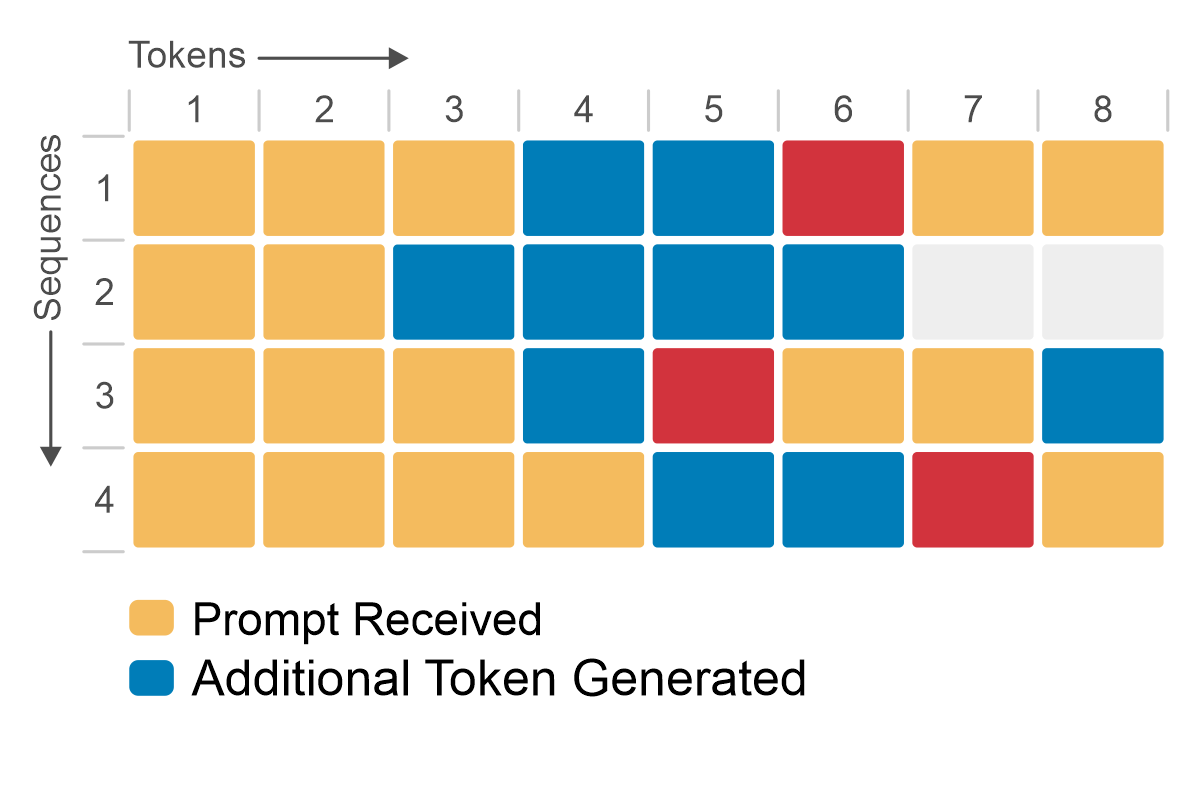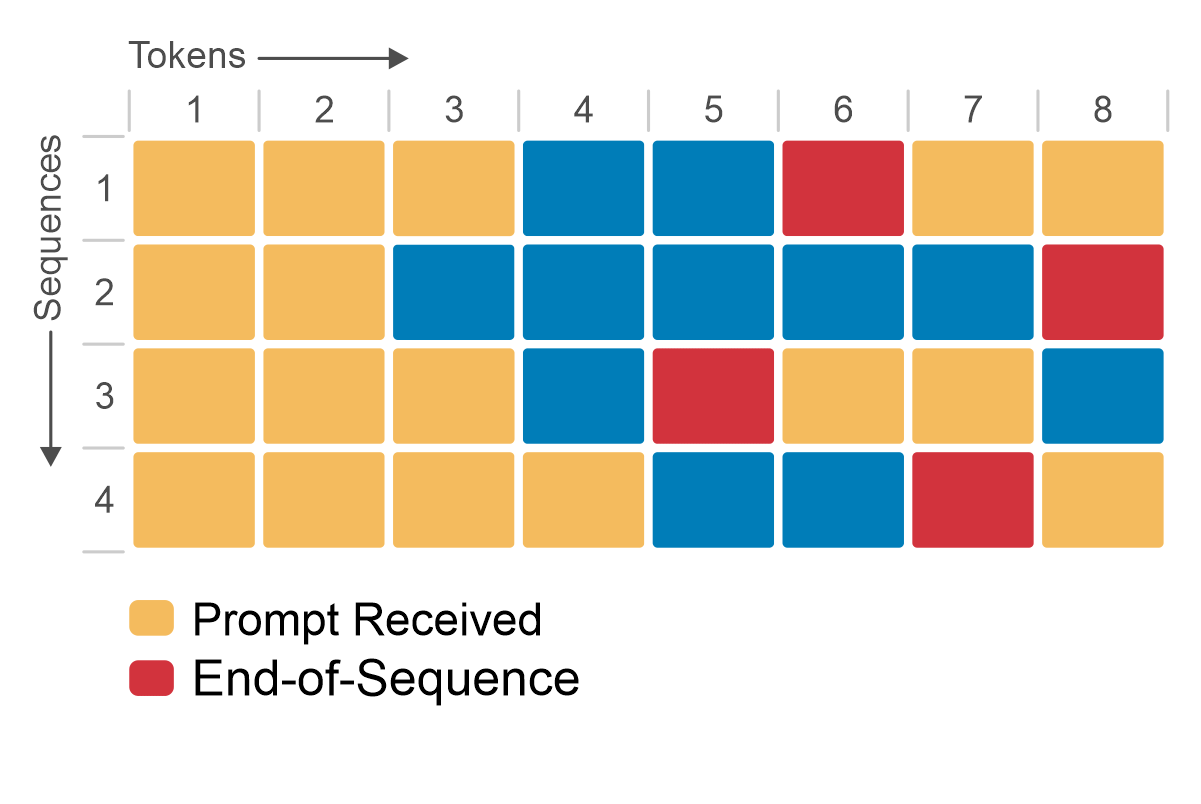
Figure 4: Iterative or continuous batching
Paged KV cache
During inference, an LLM generates output token-by-token through autoregressive decoding. This process entails each token's generation depending on all preceding tokens, including those tokens in the prompt and previously generated output. However, as the token list grows due to lengthy prompts or extensive outputs, the computational load in the self-attention stage can become a bottleneck.
To mitigate this bottleneck, a key-value (KV) cache is used, maintaining consistent performance for each decoding step by ensuring a small and manageable token list size, irrespective of the total token count. Paged KV cache takes KV cache a step further by reducing the KV cache size, enabling longer context lengths and larger batch sizes, enhancing throughput in high-scale inference scenarios. Importantly, Paged Attention operates as a cache management layer without altering the underlying model architecture.
A challenge of conventional KV cache management is memory waste due to over-reservation. Typically, the maximum memory required to support the full context size is preallocated but often remains underused. In cases where multiple inference requests share the same prompt, the key and value vectors for initial tokens are identical and can be shared among resources.
Paged Attention addresses this issue by implementing cache management strategies:
- Dynamic Allocation of GPU Memory─Instead of preallocating GPU memory, Paged Attention dynamically allocates memory in noncontiguous blocks as new cache entries are saved.
- Dynamic Mapping Table─Paged Attention maintains a dynamic mapping table that maps between the virtual view of the cache, represented as a contiguous tensor, and the noncontiguous physical memory blocks. This mapping enables efficient access and use of GPU memory resources, minimizing waste and optimizing performance.
By implementing these strategies, Paged Attention enhances memory efficiency and throughput in LLM inference tasks, particularly in scenarios involving lengthy prompts, large batch sizes, and high-scale processing requirements.
For enhanced performance, we implement quantization for the KV cache, reducing its precision to a lower level such as FP8. This adjustment yields significant improvement in throughput, which is noticeable when dealing with longer context lengths.
Context FMHA
Context feedforward multihead attention (FMHA) optimizes attention computation by refining the allocation of computational resources according to the context of the input sequence. By intelligently prioritizing attention calculations that are based on the relevance of the context, this optimization minimizes computational overhead associated with attention mechanisms.
This streamlined approach results in a notable reduction of the computational burden while enhancing the model's throughput, enabling it to process inputs more efficiently without sacrificing output quality. By optimizing attention computations in this manner, Context FMHA represents a significant advancement in the performance and efficiency of LLMs during inference.
Figure 5 and Figure 6 show the throughput comparison, that is, the number of tokens generated in one second, between the base Llama2-13b model and the model optimized for inference for a batch size of one, four, eight and 16 sequences. The Llama2-13b model has been optimized with iterative batching, FP8 KV caching, and Context FMHA enabled. The input size for inference is 512 tokens, and the output size is 512 tokens.
The following figure shows the throughput when the model is running on a single NVIDIA L40S GPU.
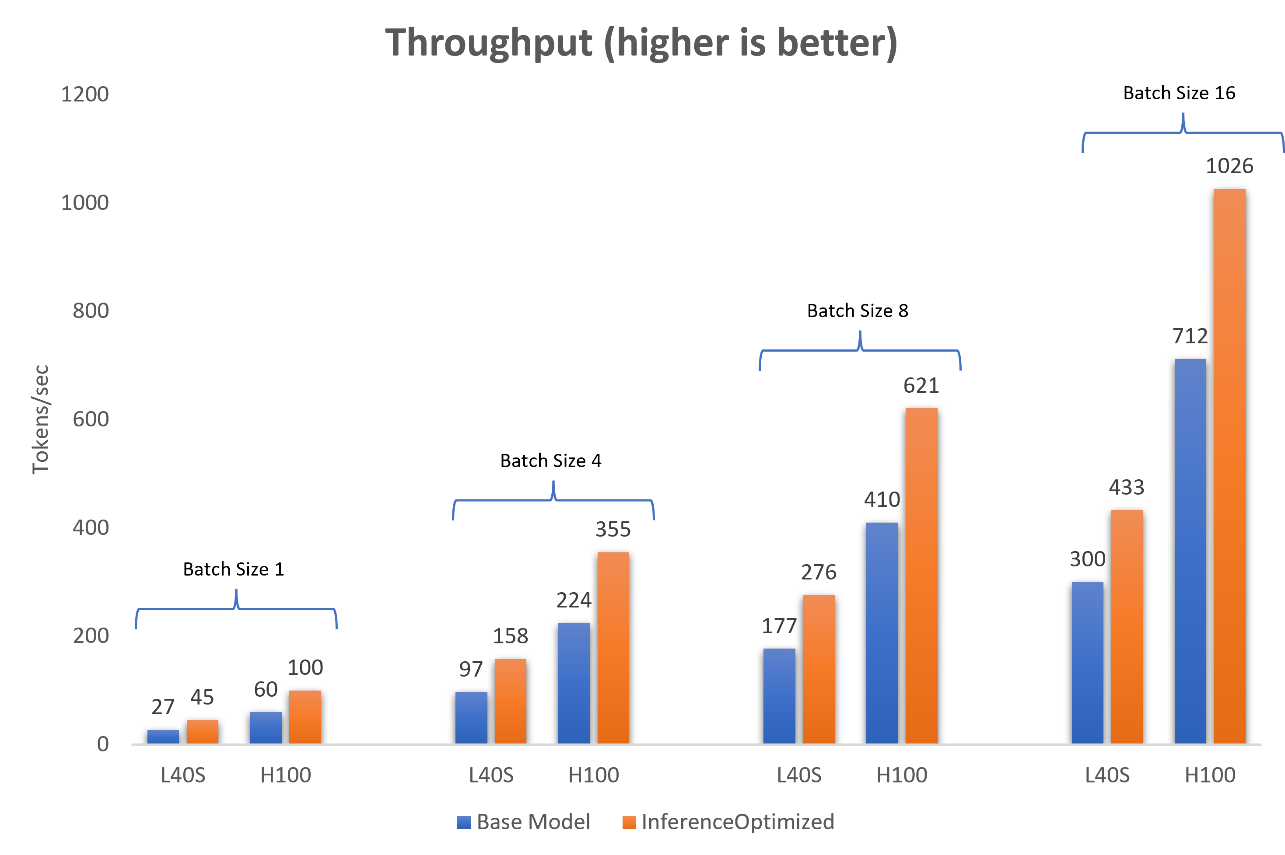
Figure 5: Comparison of throughput (tokens/sec) between the base Llama2-13b-chat model and the model optimized for inference on one NVIDIA L40S GPU and one NVIDIA H100 GPU
The following figure shows the throughput when the model is running on one NVIDIA H100 GPU and one NVIDIA L40S GPU.
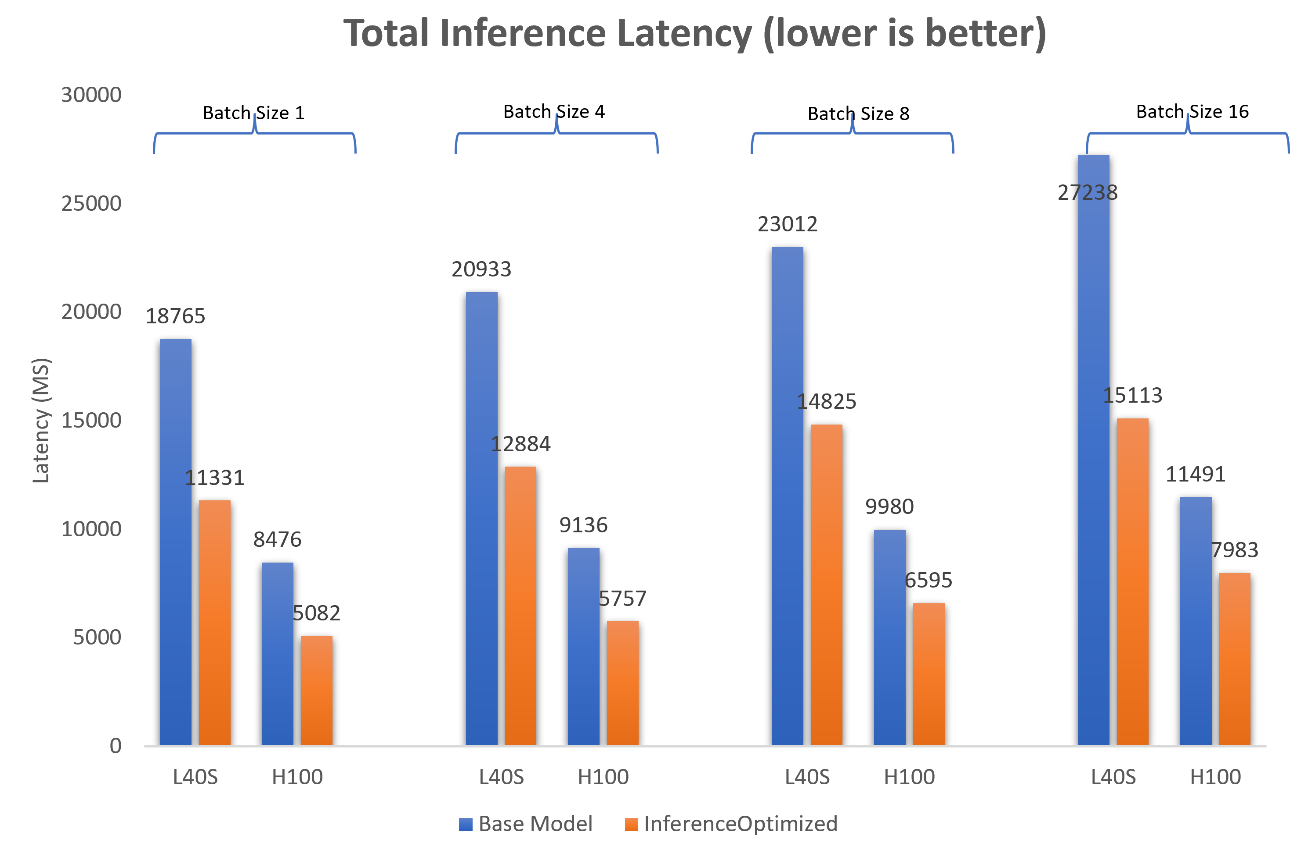
Figure 6: Comparison of time to generate total inference of 512 tokens between the Llama2-13b-chat base model and the model optimized for inference on one NVIDIA L40S GPU and one NVIDIA H100 GPU
We see a consistent gain of 30 to 40 percent in throughput when the model is optimized for inference.
The following figure shows the first token latency when Llama-2-13b is running on one NVIDIA H100 GPU and one NVIDIA L40S GPU.
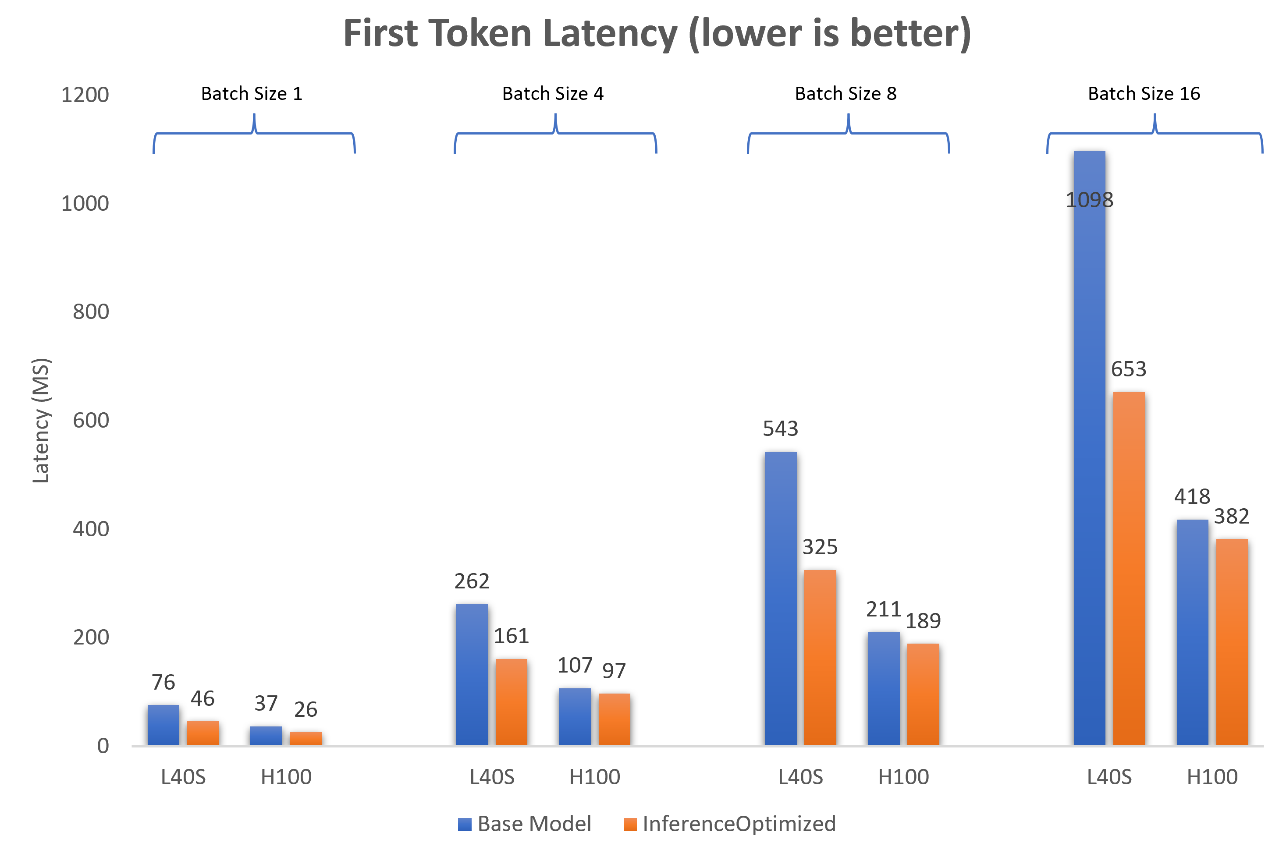
Figure 7: Comparison of time to generate the first token between the Llama2-13b-chat base model and the model optimized for inference on one NVIDIA L40S GPU and one NVIDIA H100 GPU
Conclusion
Key takeaways include:
- Optimizing a model for inference yields significant performance enhancements, boosting throughput, diminishing total inference latency, and reducing first token latency.
- The average reduction in throughput when the model is optimized for inference is approximately 40 percent.
- The total inference latency decreases by approximately 50 percent.