




Unlocking Deep Learning Training Performance on Dell PowerEdge XE8640 Servers with Four NVIDIA H100 GPUS
Tue, 02 Jul 2024 20:23:44 -0000
|Read Time: 0 minutes
The recent release of MLPerf™ Training v4.0 has provided new performance scores. This blog highlights the training performance scores on Dell PowerEdge XE8640 servers for different workloads in the MLPerf benchmark. The workloads include large language model (LLM) fine-tuning, graph neural networks (GNNs), image classification, medical image segmentation, object detection, and language modeling.
Dell PowerEdge XE8640 server
The PowerEdge XE8640 server can accelerate predictive and generative AI training and inferencing, modeling, simulation, and more for HPC applications with optimized compute. This server is a powerful compute-intensive server that is packed with four NVIDIA Tensor Core H100 GPUs.

Figure 1: Front view of the PowerEdge XE8640 server
The PowerEdge XE8640 server is an air-cooled server that:
• Uses a powerful architecture and the power of two 4th or 5th Generation Intel Xeon processors with a high core count of up to 64 cores and the latest on-chip innovations to boost AI and ML operations
• Includes four NVIDIA H100 Tensor Core 700 W SXM5 GPUs for extreme performance that are fully interconnected with NVIDIA NVLink technology
• Improves training performance with up to 900 GB/s bandwidth for GPU-to-GPU communication, which is 1.5 times more than the previous generation
• Hosts multitenant environments using virtualization options such as NVIDIA Multi-Instance GPU (MIG) capability
Figure 2: Top view of the PowerEdge XE8640 server
Accelerated I/O throughput
The PowerEdge XE8640 server enables deployment of the latest generation technologies including DDR5, NVLink, PCIe Gen 5.0, and NVMe SSDs to push the boundaries of data flow and computing possibilities. It includes:
• Up to four PCIe Gen 5 slots and up to eight drives that enable optimal expansion for high-performance AI operations.
• Support for NVIDIA GPUDirect Storage (GDS), a direct data path for direct memory access (DMA) transfers between GPU memory and storage, to increase system bandwidth and decrease latency and utilization load on the CPU.
• A 4U air-cooled design chassis that supports the highest wattage next-generation technologies in up to 35°C ambient, which makes it sustainable and cost effective for data center operations.
NVIDIA Tensor Core H100 GPU
The NVIDIA H100 Tensor Core GPU is an integral part of the NVIDIA data center platform. Built for AI, HPC, and data analytics, the platform accelerates over 3,000 applications, and is available everywhere from the data center to the edge, delivering both dramatic performance gains and cost-saving opportunities. The NVIDIA H100 Tensor Core GPU delivers unprecedented performance, scalability, and security for every workload.
With the NVIDIA NVLink Switch, you can connect up to 256 NVIDIA H100 GPUs to accelerate exascale workloads, while the dedicated Transformer Engine supports trillion-parameter language models. The NVIDIA H100 GPU uses breakthrough innovations in the NVIDIA Hopper architecture to deliver industry-leading conversational AI, accelerating LLMs by 30 times over the previous generation.
The following figure shows the NVIDIA H100 SXM accelerator:

Figure 3. NVIDIA H100 SXM accelerator
MLPerf Training v4.0 results
The following table shows the results of a Dell PowerEdge XE8640 server with four NVIDIA H100 GPUS on several benchmarks:
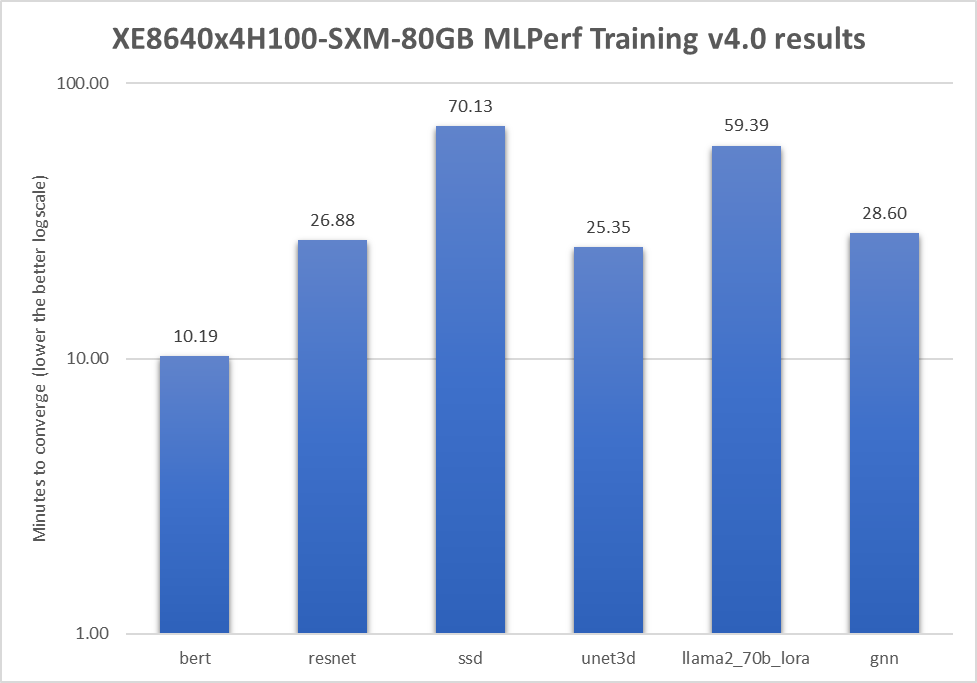
Figure 4: Different benchmarks in the MLPerf Training 4.0 submission
Conclusion
Figure 4 shows the official MLPerf results, which have passed compliance tests. Generative AI workloads have also been validated and performance tested with this server. The Dell PowerEdge XE8640 server with four NVIDIA H100 GPUs delivers excellent performance for different tasks. End users can expect similar performance for their use cases.
Appendix: Submission hardware specifications
The following table lists the hardware specifications for the submission for a Dell PowerEdge XE8640 server with four NVIDIA H100 GPUS:
Table 1. MLPerf Hardware specifications
Property | Value |
Division | Closed |
Status | Available on-premises |
System name | XE8640 x 4H100-SXM-80GB |
Number of nodes | 1 |
Host processors per node | 2 |
Host processor model name | Intel Xeon Platinum 8468 |
Host processor core count | 48 |
Host memory capacity | 1.024 TB |
Host storage type | NVMe |
Host storage capacity | 1 x 5.9 TB NVMe |
Host networking | 4 x ConnectX-7 IB NDR 400 Gb/Sec |
Host memory configuration | 16 x 64 GB DDR5 |
Accelerators per node | 4 |
Accelerator model name | NVIDIA H100-SXM5-80GB |
Accelerator host interconnect | PCIe 5.0x16 |
Accelerator frequency | 1980 MHz |
Accelerator memory configuration | HBM3 |
Accelerator memory capacity | 80 GB |
Accelerator interconnect | 18 x NVLink 25 GB/s |
Hardware notes | GPU TDP: 700 W |
Framework | NGC MXNet 23.04 NGC PyTorch 23.04 NGC HugeCTR 23.04 |
Software stack | CUDA 12.4 cuBLAS 12.4.5.8-1 cuDNN 9.1.0 TensorRT 8.6.3 DALI 1.36.0 NCCL 2.21.5-1+cuda12.4 OpenMPI 4.1.7a1 MLNX_OFED_LINUX-5.8-1.1.2.1 |
Operating system | Red Hat Enterprise Linux 9.1 |
MLCommons Results
The preceding graph shows MLCommons results for MLPerf IDs 4.0-0020.
LORA Llama 2 fine-tuning results not verified by MLCommons Association.
The MLPerf™ name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.