




The Evolution of Edge Inferencing with NVIDIA NIM and Dell NativeEdge

Inferencing at the edge has taken a huge step forward with recent advances in GPU and AI technology. It’s smarter and faster, making it easier for computers to understand pictures and words together. This new way requires less work to train and can recognize many more elements in images than before. It’s like teaching a computer to see and think like a person, but quicker and without much human interaction. With NanoOWL, a special project from NVIDIA, this all happens at lightning speed, even when there is a lot to process. This results in even smarter machines that can do their jobs more effectively, right where they are needed.
This blog discusses the new AI models that enable all of this to work. It focuses on a specific example, and then closes by explaining how to deploy the technology on thousands of devices using NativeEdge.
Before we jump too far, let’s start with a quick recap.
Edge Inferencing at its Infancy – a Recap
In my previous post Inferencing at the Edge, I described the traditional process for edge inferencing. This process involves the following steps, which are also described in the following diagram.
- Create the model.
- Train the model.
- Save the model.
- Apply post-training quantization.
- Convert the model to TensorFlow Lite.
- Compile the TensorFlow Lite model using edge TPU compiler for Edge TPU devices such as Coral Dev board (Google development platform that includes the Edge TPU) to the TPU USB Accelerator (this allows users to add Edge TPU capabilities to existing hardware by simply plugging in the USB device).
- Deploy the model at the edge to make inferences.
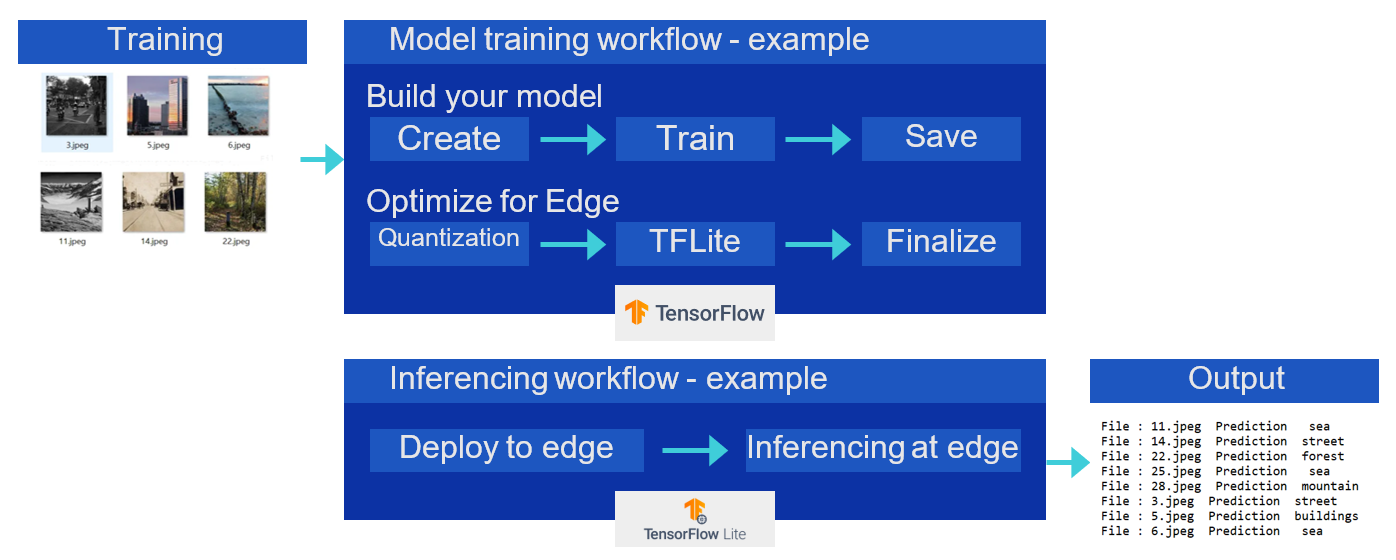 Traditional approach of edge inferencing
Traditional approach of edge inferencing
Challenges with the Initial Approach of Edge Inferencing
There are several key challenges with the traditional Inferencing approach, specifically as it relates to computer vision use cases:
- Labor-intensive data preparation—Traditional vision datasets require substantial human effort to create. This involves manually labeling thousands or even millions of images, which is time-consuming and expensive.
- Limited scope of visual concepts—Often, vision models are trained on datasets with a narrow range of concepts, which limits their ability to understand and classify a wide variety of images.
- Performance under stress—Many models perform poorly on stress tests, which are designed to evaluate how well a model can handle challenging scenarios that it may not have encountered during training.
The Generative AI Upgrade of Edge Inferencing
New AI models like OWL-ViT (Object-Word Learner using Vision Transformers) can find and understand objects in pictures, even those they haven’t been explicitly trained on. Unlike traditional models that rely on limited, labor-intensive datasets, OWL-ViT learns from a much broader range of visual concepts by using large-scale image-text data from the web. In addition, it leverages self-training techniques, where the model uses its own predictions to continually learn and improve its understanding of the object. This approach significantly reduces the need for costly dataset creation. It also combines special tools like Vision Transformers (ViT) to see the picture details and language models to match them into words. OWL-ViT is built on top of another model which was developed by Open-AI, called CLIP (Contrastive Language-Image Pretraining). CLIP specializes in matching pictures with words. OWL-ViT takes CLIP a step further by not just matching, but also finding where objects are located in pictures, using the descriptions in words.
This enables computers to understand and label what’s in an image, just like we describe it in text.
Adding Performance Optimization with NVIDIA NanoOWL Project
NanoOWL is an NVIDIA project that is essentially a performance-enhanced version of the OWL-ViT model that is specifically optimized to work in real-time use cases.
Here’s a simplified breakdown of how NanoOWL operates:
- Optimization—NanoOWL fine-tunes the OWL-ViT model for fast performance on NVIDIA’s computing platforms.
- Tree detection pipeline—It introduces “tree detection”, which allows for layered detection and classification based on text descriptions.
- Real-time processing—The system is designed to work quickly, providing immediate results for object detection and classification tasks.
- Text-based interaction—Users can interact with NanoOWL through text, instructing it to detect and classify objects within images by providing textual prompts.
- Nested detection—The technology can identify and categorize objects at any level of detail, just by analyzing the user’s text.
Building an Edge Inferencing Application using NanoOWL
Most edge inferencing applications have a lot in common. As inputs, they can typically accept text and an image. To process this image-text input, the application should first load the model into memory. Then, the model can be called with an inference function where the image and text are passed in to produce an output.
The general recipe of the reference example can be applied to nearly any generative AI model.
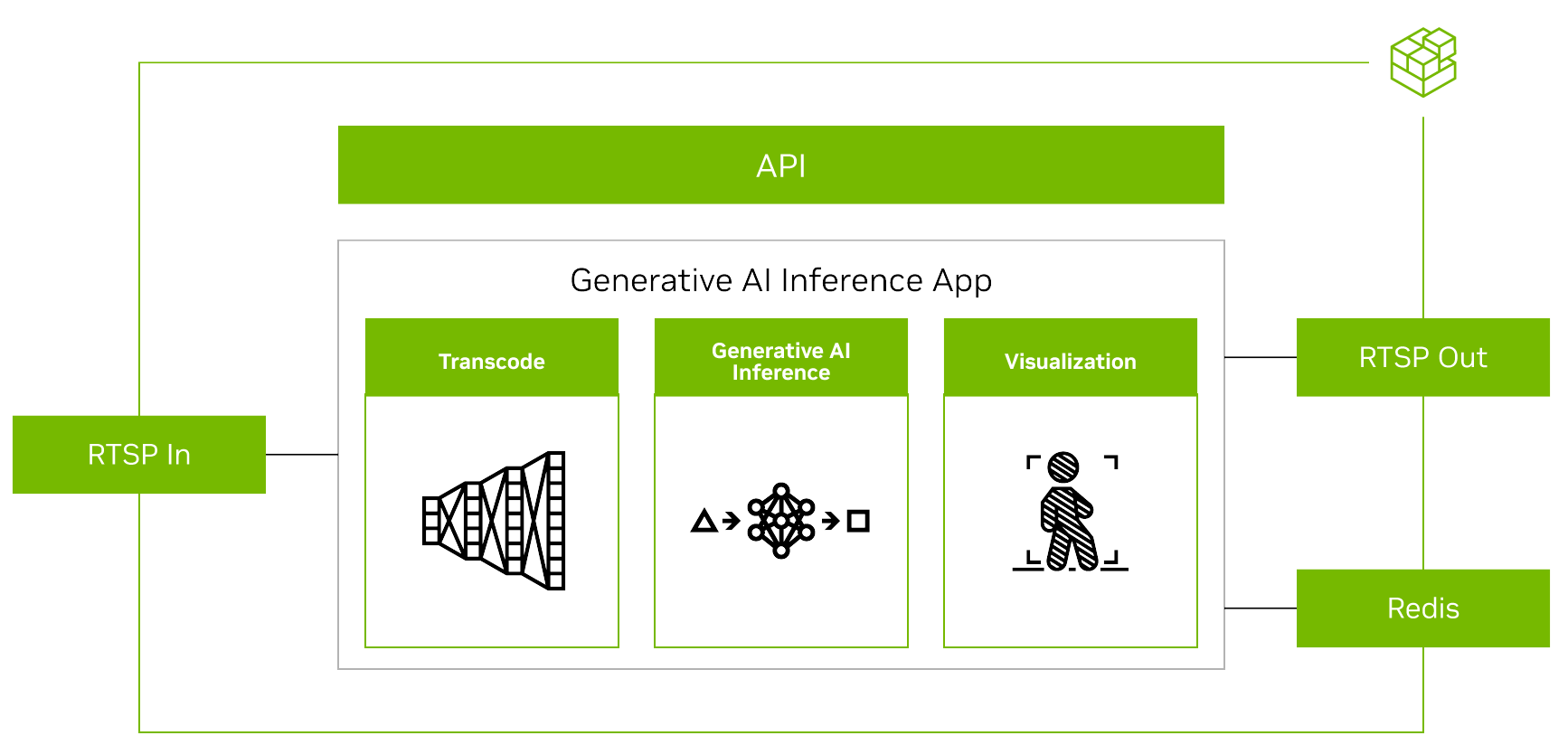 Overview of a GenAI application using Metropolis microservices
Overview of a GenAI application using Metropolis microservices
(Source: Bringing Generative AI to the Edge with NVIDIA Metropolis Microservices for Jetson)
This general process is described in the following steps:
- Stream video—The input and output use the RTSP protocol. RTSP is streamed from Video Storage Toolkit (VST), a video ingestion and management microservice. The output is streamed over RTSP with the overlaid inference output. The output metadata is sent to a Redis stream where other applications can read the data. For more information, see the Video Storage Toolkit with Metropolis Microservices demo videos.
- Introduce an API interface to enable chat interaction—As a generative AI application requires some external interface such as prompts; the application must accept REST API requests.
- Package and deploy the application into containers—The application that was developed in previous steps is containerized to integrate seamlessly with other microservices.
Learning by Example – Writing Text to Image Inferencing Applications using NanoOWL
The following figure shows the architecture of a specific NanoOwl application that can be used as a general recipe to build generative AI–powered applications taken from the NVIDIA guide:
Bringing Generative AI to the Edge.
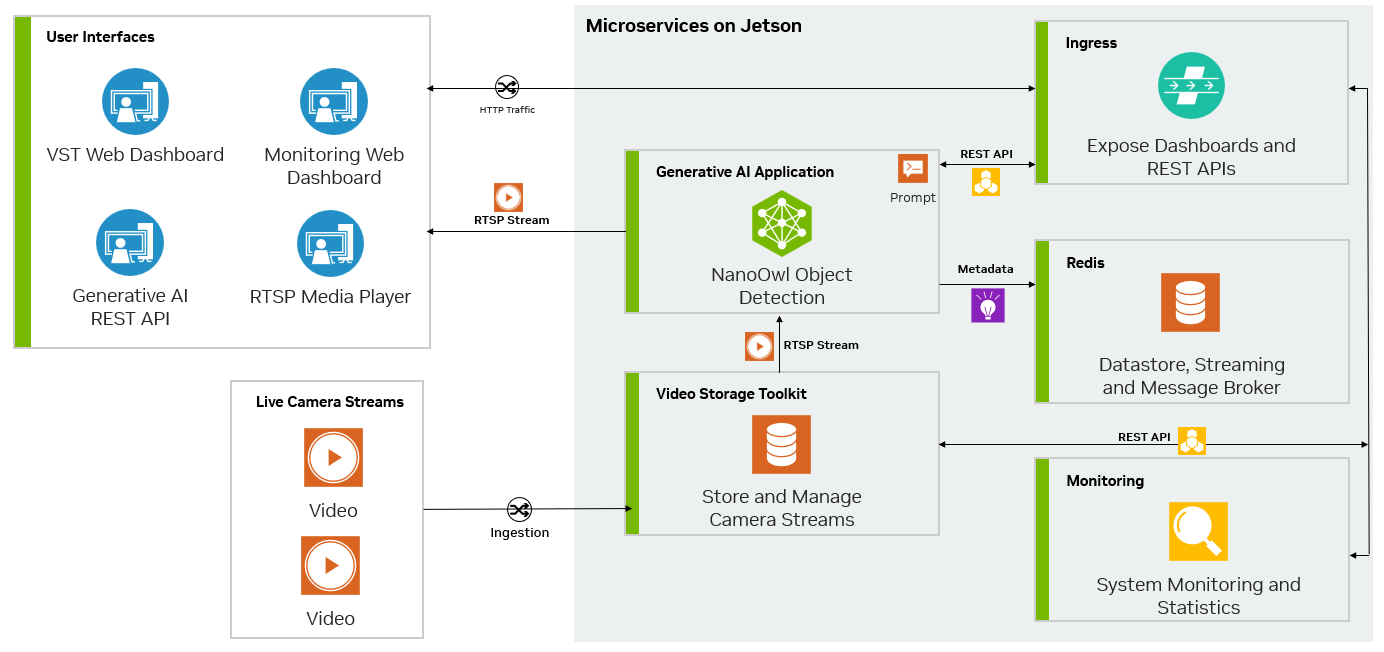 Edge inferencing example architecture using NanoOWL
Edge inferencing example architecture using NanoOWL
(Source: Bringing Generative AI to the Edge with NVIDIA Metropolis Microservices for Jetson)
In this specific example, the application:
- Calls the predict function of the machine learning model to perform inference. This involves processing input data through the model to obtain predictions.
- Integrates RTSP input and output using the jetson-utils library, which is designed for handling video streaming on NVIDIA Jetson devices. This allows for the setup of video streaming services over the network.
- Adds a REST endpoint using Flask, a micro web framework in Python. This endpoint accepts requests to update system settings on-the-fly.
- Adds overlay on the video steam. NVIDIA mmj_utils is a custom utility library used to generate overlays on video streams and interact with a Video Streaming Toolkit (VST) to manage video streams.
- Outputs metadata to a Redis database, which is an in-memory data structure store used as a database, cache, and message broker.
- Containerizes the edge inferencing application.
Deploying and Managing the Edge Inferencing Applications on Thousands of Devices using NativeEdge
In this step, we use NativeEdge as our edge platform. NativeEdge allows us to deploy the edge-inferencing application from the previous step and deploy it on thousands of devices through a single command.
To do so, we integrate the containerized application with a NativeEdge blueprint, together with the necessary NVIDIA runtime services and libraries such as TensorRT, as well as the dependent libraries that are needed such as Flask, Redis, Video Streaming Service, and so on.
The blueprint is now available and all that is left to do is tell NativeEdge to deploy it on one, two, or thousands of endpoints, and then let the NativeEdge Orchestrator do all the deployment work for us.
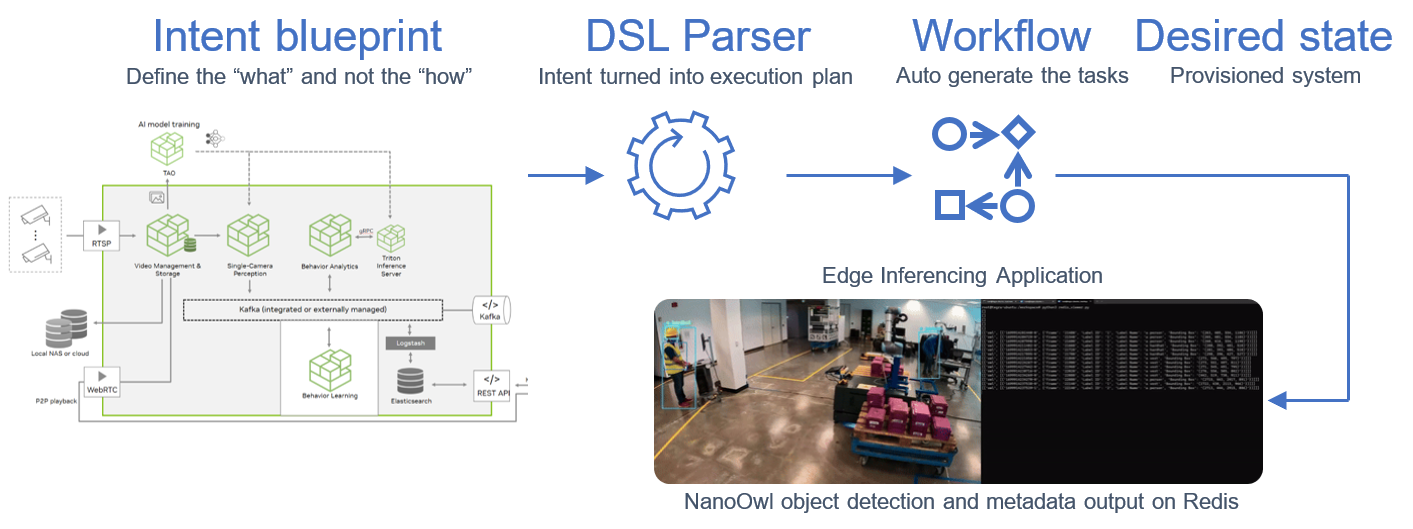 Blueprint automates deployment of inferencing applications across thousands of devices
Blueprint automates deployment of inferencing applications across thousands of devices
Extending our Example to Other Models
This reference example uses NanoOwl. However, you can follow these steps for any model that has a load and inference function callable from Python. For more information about the full implementation, see the reference example on the /NVIDIA-AI-IOT/mmj_genai GitHub project.
Final Notes
The use of the new generative AI models for edge Inferencing in general and compute vision specifically reduces the time to train and build such an application.
NVIDIA provides a useful set of tools and libraries that simplify the development and performance tuning processes on their infrastructure.
NativeEdge reduces the operational complexity involved in deploying and continuously managing those applications across many distributed endpoints.
The entire framework and platform are based on open-source foundations as well as cloud-native and DevOps best practices, which makes the development and management of those applications as simple as any traditional cloud-service.
NativeEdge provides a common platform that can support both traditional and modern edge inferencing applications simultaneously, enabling a smoother transition into this new world.
References:
- Delivering an AI-Powered Computer Vision Application with NVIDIA DeepStream and Dell NativeEdge | Dell Technologies Info Hub
- Inferencing at the Edge
- Bringing Generative AI to the Edge with NVIDIA Metropolis Microservices for Jetson | NVIDIA Technical Blog
- GitHub - NVIDIA-AI-IOT/mmj_genai: A reference example for integrating NanoOwl with Metropolis Microservices for Jetson
- GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
- GitHub - NVIDIA-AI-IOT/nanoowl: A project that optimizes OWL-ViT for real-time inference with NVIDIA TensorRT.
- OWL-ViT (huggingface.co)
- Understanding OpenAI’s CLIP model | by Szymon Palucha | Medium