




Supercharge Inference Performance at the Edge using the Dell EMC PowerEdge XE2420
Wed, 05 Jul 2023 13:43:30 -0000
|Read Time: 0 minutes
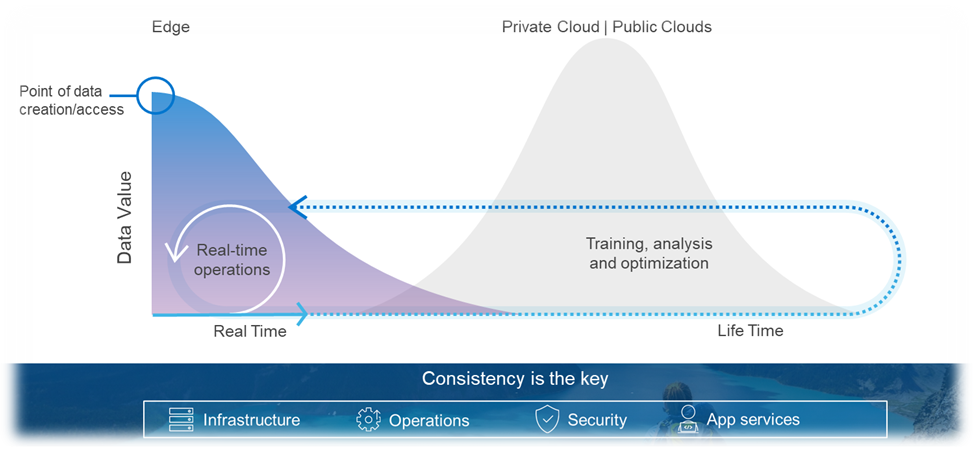
Deployment of compute at the Edge enables the real-time insights that inform competitive decision making. Application data is increasingly coming from outside the core data center (“the Edge”) and harnessing all that information requires compute capabilities outside the core data center. It is estimated that 75% of enterprise-generated data will be created and processed outside of a traditional data center or cloud by 2025.[1]
This blog demonstrates that the Dell EMC PowerEdge XE2420, a high-performance Edge server, performs AI inference operations more efficiently by leveraging its ability to use up to four NVIDIA T4 GPUs in an edge-friendly short-depth server. The XE2420 with NVIDIA T4 GPUs can classify images at 25,141 images/second, an equal performance to other conventional 2U rack servers that is persistent across the range of benchmarks.
XE2420 Features and Capabilities
The Dell EMC PowerEdge XE2420 is a 16” (400mm) deep, high-performance server that is purpose-built for the Edge. The XE2420 has features that provide dense compute, simplified management and robust security for harsh edge environments.

Built for performance: Powerful 2U, two-socket performance with the flexibility to add up to four accelerators per server and a maximum local storage of 132TB.
Designed for harsh edge environments: Tested to Network Equipment-Building System (NEBS) guidelines, with extended operating temperature tolerance of 5˚-45˚C without sacrificing performance, and an optional filtered bezel to guard against dust. Short depth for edge convenience and lower latency.
Integrated security and consistent management: Robust, integrated security with cyber-resilient architecture, and the new iDRAC9 with Datacenter management experience. Front accessible and cold-aisle serviceable for easy maintenance.
The XE2420 allows for flexibility in the type of GPUs you use, in order to accelerate a wide variety of workloads including high-performance computing, deep learning training and inference, machine learning, data analytics, and graphics. It can support up to 2x NVIDIA V100/S PCIe, 2x NVIDIA RTX6000, or up to 4x NVIDIA T4.
Edge Inferencing with the T4 GPU
The NVIDIA T4 is optimized for mainstream computing environments and uniquely suited for Edge inferencing. Packaged in an energy-efficient 70-watt, small PCIe form factor, it features multi-precision Turing Tensor Cores and new RT Cores to deliver power efficient inference performance. Combined with accelerated containerized software stacks from NGC, XE240 and NVIDIA T4 is a powerful solution to deploy AI application at scale on the edge.

Fig 1: NVIDIA T4 Specifications

Fig 2: Dell EMC PowerEdge XE2420 w/ 4x T4 & 2x 2.5” SSDs
Dell EMC PowerEdge XE2420 MLPerf Inference Tested Configuration
Processors | 2x Intel Xeon Gold 6252 CPU @ 2.10GHz |
Storage
| 1x 2.5" SATA 250GB |
1x 2.5" NVMe 4TB | |
Memory | 12x 32GB 2666MT/s DDR4 DIMM |
GPUs | 4x NVIDIA T4 |
OS | Ubuntu 18.04.5 |
Software
| TensorRT 7.2 |
CUDA 11.0 Update 1 | |
cuDNN 8.0.2 | |
DALI 0.25.0 | |
Hardware Settings | ECC off |
Inference Use Cases at the Edge
As computing further extends to the Edge, higher performance and lower latency become vastly more important in order to decrease response time and reduce bandwidth. One suite of diverse and useful inference workload benchmarks is MLPerf. MLPerf Inference demonstrates performance of a system under a variety of deployment scenarios and aims to provide a test suite to enable balanced comparisons between competing systems along with reliable, reproducible results.
The MLPerf Inference v0.7 suite covers a variety of workloads, including image classification, object detection, natural language processing, speech-to-text, recommendation, and medical image segmentation. Specific scenarios covered include “offline”, which represents batch processing applications such as mass image classification on existing photos, and “server”, which represents an application where query arrival is random, and latency is important. An example of server is essentially any consumer-facing website where a consumer is waiting for an answer to a question. Many of these workloads are directly relevant to Telco & Retail customers, as well as other Edge use cases where AI is becoming more prevalent.
Measuring Inference Performance using MLPerf
We demonstrate inference performance for the XE2420 + 4x NVIDIA T4 accelerators across the 6 benchmarks of MLPerf Inference v0.7 in order to showcase the versatility of the system. The inference benchmarking was performed on:
- Offline and Server scenarios at 99% accuracy for ResNet50 (image classification), RNNT (speech-to-text), and SSD-ResNet34 (object detection)
- Offline and Server scenarios at 99% and 99.9% accuracy for BERT (NLP) and DLRM (recommendation)
- Offline scenario at 99% and 99.9% accuracy for 3D-Unet (medical image segmentation)
These results and the corresponding code are available at the MLPerf website.[1]
Key Highlights
The XE2420 is a compact server that supports 4x 70W T4 GPUs in an efficient manner, reducing overall power consumption without sacrificing performance. This high-density and efficient power-draw lends it increased performance-per-dollar, especially when it comes to a per-GPU performance basis.
Additionally, the PowerEdge XE2420 is part of the NVIDIA NGC-Ready and NGC-Ready for Edge validation programs[i]. At Dell, we understand that performance is critical, but customers are not willing to compromise quality and reliability to achieve maximum performance. Customers can confidently deploy inference and other software applications from the NVIDIA NGC catalog knowing that the PowerEdge XE2420 meets the requirements set by NVIDIA to deploy customer workloads on-premises or at the Edge.
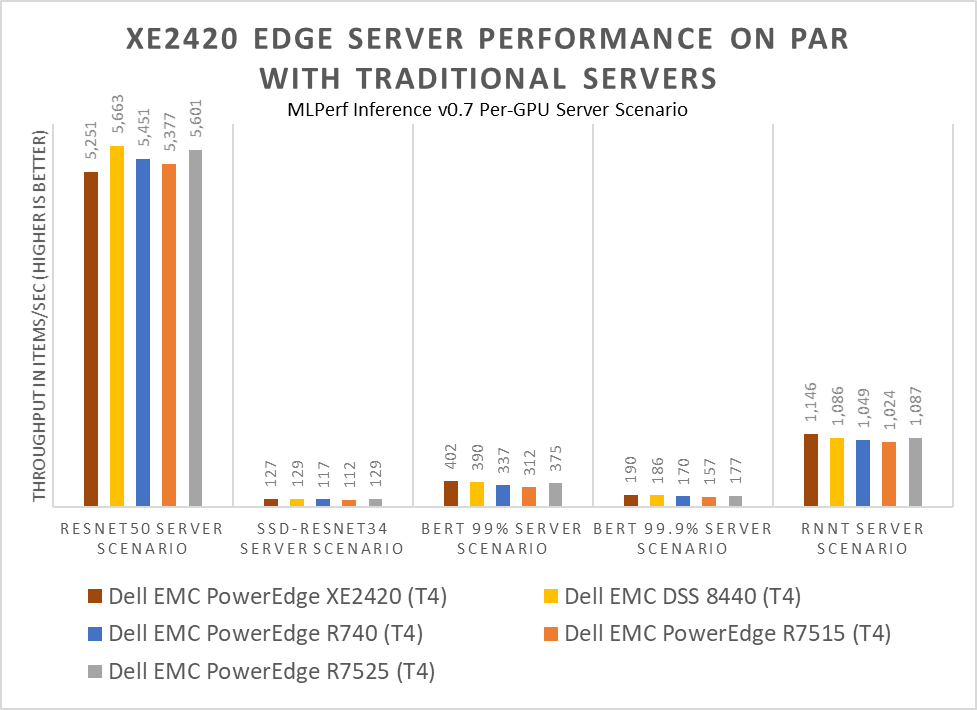
In the chart above, per-GPU (aka 1x T4) performance numbers are derived from the total performance of the systems on MLPerf Inference v0.7 & total number of accelerators in a system. The XE2420 + T4 shows equivalent per-card performance to other Dell EMC + T4 offerings across the range of MLPerf tests.
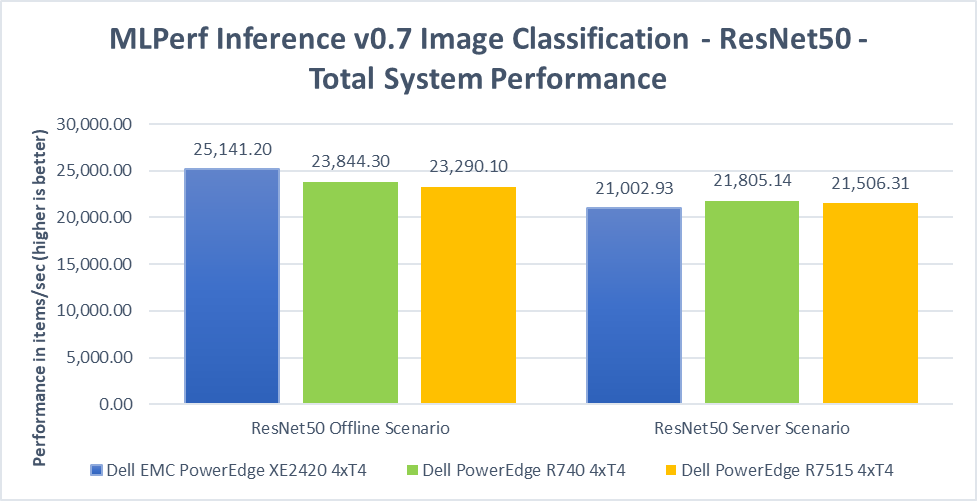
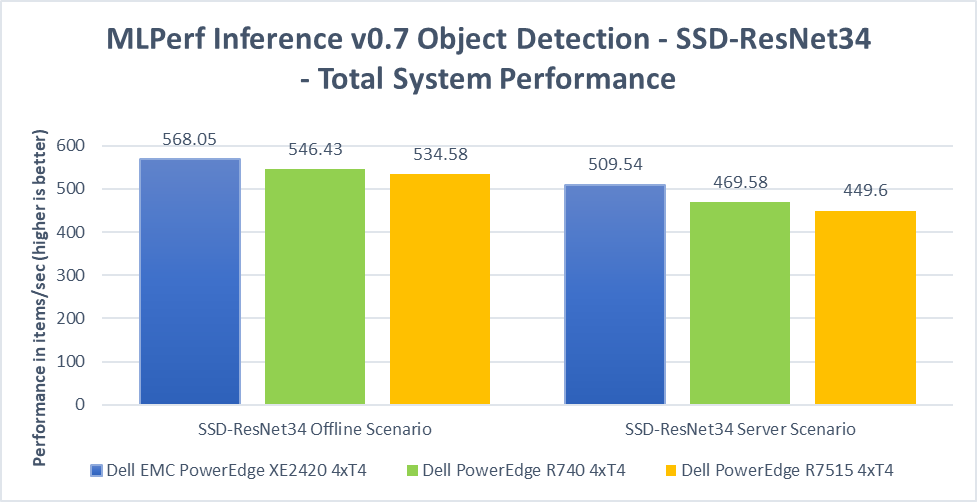
When placed side by side with the Dell EMC PowerEdge R740 (4x T4) and R7515 (4x T4), the XE2420 (4x T4) showed performance on par across all MLPerf submissions. This demonstrates that operating capabilities and performance were not sacrificed to achieve the smaller depth and form-factor.
Conclusion: Better Density and Flexibility at the Edge without sacrificing Performance
MLPerf inference benchmark results clearly demonstrate that the XE2420 is truly a high-performance, half-depth server ideal for edge computing use cases and applications. The capability to pack four NVIDIA T4 GPUs enables it to perform AI inference operations at par with traditional mainstream 2U rack servers that are deployed in core data centers. The compact design provides customers new, powerful capabilities at the edge to do more, faster without extra components. The XE2420 is capable of true versatility at the edge, demonstrating performance not only for common retail workloads but also for the full range of tested workloads. Dell EMC offers a complete portfolio of trusted technology solutions to aggregate, analyze and curate data from the edge to the core to the cloud and XE2420 is a key component of this portfolio to meet your compute needs at the Edge.
XE2420 MLPerf Inference v0.7 Full Results
The raw results from the MLPerf Inference v0.7 published benchmarks are displayed below, where the metric is throughput (items per second).
Benchmark | ResNet50 | RNNT | SSD-ResNet-34 | |||
Scenario | Offline | Server | Offline | Server | Offline | Server |
Result | 25,141 | 21,002 | 6,239 | 4,584 | 568 | 509 |
Benchmark | BERT | DLRM | ||||||
Scenario | Offline | Server | Offline | Server | ||||
Accuracy % | 99 | 99.9 | 99 | 99.9 | 99 | 99.9 | 99 | 99.9 |
Result | 1,796 | 839 | 1,608 | 759 | 140,217 | 140,217 | 126,513 | 126,513 |
Benchmark | 3D-Unet | |
Scenario | Offline | |
Accuracy % | 99 | 99.9 |
Result | 30.32 | 30.32 |