




Ready Solution for HPC PixStor Storage Capacity Expansion, HDR100 Update
Tue, 17 Nov 2020 21:43:49 -0000
|Read Time: 0 minutes
Introduction
Today’s HPC environments have ever increasing demands for very high-speed storage that also frequently must provide high capacity and distributed access via several standard protocols such as NFS, and SMB. These high demand HPC requirements are typically covered by Parallel File Systems that provide concurrent access to a single file or set of files from multiple nodes, very efficiently and securely distributing data to multiple LUNs across several servers using the network technology with the highest speed available.
Solution Architecture
This blog is a technology update for the use of Infiniband HDR100 on the Dell EMC Ready Solution for HPC PixStor Storage, a Parallel File System (PFS) solution for HPC environments where PowerVault ME484 EBOD arrays are used to increase the capacity of the solution. Figure 1 presents the reference architecture depicting the capacity expansion SAS additions to the existing PowerVault ME4084 storage arrays, replacing Infiniband EDR components with HDR100: ConnectX-6 HCAs and QM8700 switches. The PixStor solution includes the widespread General Parallel File System also known as Spectrum Scale as the PFS component, in addition to many other ArcaStream software components including advanced analytics, simplified administration and monitoring, efficient file search, advanced gateway capabilities and many others.
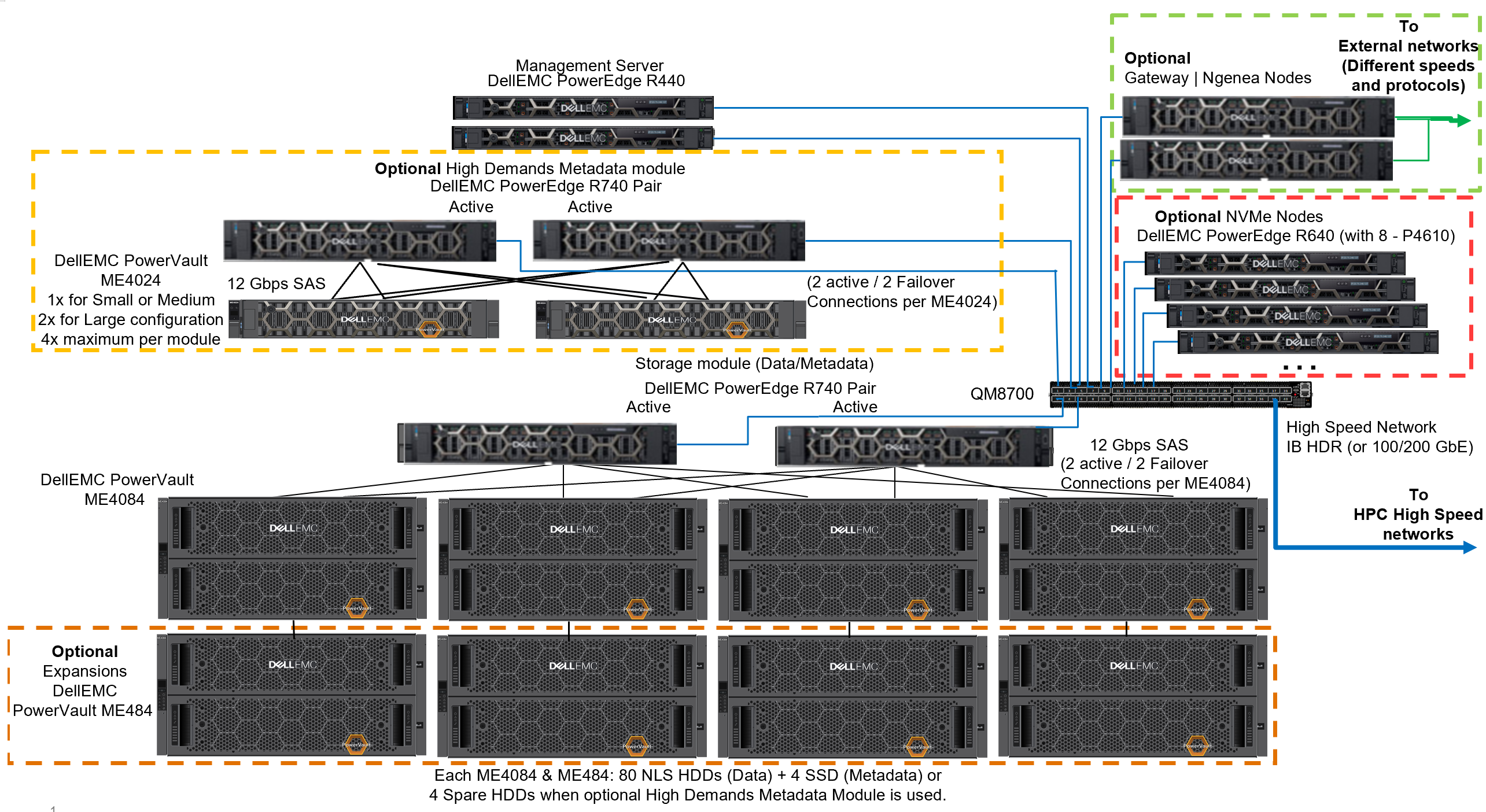
Figure 1 Reference Architecture
Solution Components
This solution was released with the latest Intel Xeon 2nd generation Scalable Xeon CPUs (Cascade Lake) and some of the servers will use the fastest RAM available (2933 MT/s). However, due to hardware availability during testing, the solution prototype used servers with Intel Xeon 1st generation Scalable Xeon CPUs (Skylake) and slower RAM to characterize the performance. Since the bottleneck of the solution is at the SAS controllers of the DellEMC PowerVault ME40x4 arrays, no significant performance disparity is expected once the Skylake CPUs and RAM are replaced with Cascade Lake CPUs and faster RAM. In addition, the solution was updated to the latest version of PixStor (5.1.3.1) that supports RHEL 7.7 and OFED 5.0-2.1.8.
Table 1 shows the list of main components for the solution where the first column has components used at release time and therefore available to customers, and the last column has the components actually used for characterizing the performance of the solution. The drives listed for data (12TB NLS) and metadata (960GB SSD), are the ones used for performance characterization, and faster drives can provide better Random IOPs and may improve create/removal metadata operations.
Finally, for completeness, the list of possible data HDDs and metadata SSDs was included, which is based on the drives supported as enumerated on the DellEMC PowerVault ME4 support matrix, available online.
Table 1 Components to be used at release time and those used in the test bed
Solution Component | Released | Test Bed | |
Internal Mgmt Connectivity | Dell Networking S3048-ON Gigabit Ethernet | ||
Data Storage Subsystem | 1x to 4x Dell EMC PowerVault ME4084
| ||
Optional High Demand Metadata Storage Subsystem | 1x to 2x (max 4x) Dell EMC PowerVault ME4024 | ||
RAID Storage Controllers | Redundant 12 Gbps SAS | ||
Capacity w/o Expansion | Raw: 4032 TB (3667 TiB or 3.58 PiB) with 12TB HDDs | ||
Capacity w/Expansion | Raw: 8064 TB (7334 TiB or 7.16 PiB) with 12TB HDDs Formatted ~ 6144 GB (5588 TiB or 5.46 PiB) | ||
Processor | Gateway/Ngenea (R740) | 2x Intel Xeon Gold 6230 2.1G, 20C/40T, 10.4GT/s, 27.5M Cache, Turbo, HT (125W) DDR4-2933 | 2x Intel Xeon Gold 6136 @ |
High Demand Metadata (R740) | |||
Storage Node (R740) | |||
Management Node (R440) | 2x Intel Xeon Gold 5220 2.2G, 18C/36T, 10.4GT/s, 24.75M Cache, Turbo, HT (125W) DDR4-2666 | 2x Intel Xeon Gold 5118 @ 2.30GHz, 12 cores | |
Memory | Gateway/Ngenea (R740) | 12 x 16GiB 2933 MT/s RDIMMs | 24x 16GiB 2666 MT/s RDIMMs (384 GiB) |
High Demand Metadata (R740) | |||
Storage Node (R740) | |||
Management Node (R440) | 12 X 16GB RDIMMs, 2666 MT/s (192GiB) | 12x 8GiB 2666 MT/s RDIMMs (96 GiB) | |
Operating System | CentOS 7.7 | ||
Kernel version | 3.10.0-1062.12.1.el7.x86_64 | ||
PixStor Software | 5.1.3.1 | ||
OFED Version | Mellanox OFED 5.0-2.1.8 | ||
High Performance Network Connectivity | Mellanox ConnectX-6 Dual-Port InfiniBand VPI HDR100/100 GbE, and 10 GbE | ||
High Performance Switch | 2x Mellanox QM8700 (HA – Redundant) | ||
Local Disks (OS & Analysis/monitoring) | All servers except Management node 3x 480GB SSD SAS3 (RAID1 + HS) for OS PERC H730P RAID controller 3x 480GB SSD SAS3 (RAID1 + HS) for OS & Analysis/Monitoring PERC H740P RAID controller | All servers except Management node 2x 300GB 15K SAS3 (RAID 1) for OS PERC H330 RAID controller Management Node 5x 300GB 15K SAS3 (RAID 5) for OS & PERC H740P RAID controller | |
Systems Management | iDRAC 9 Enterprise + DellEMC OpenManage | ||
Performance Characterization
To characterize this Ready Solution, we used the hardware specified in the last column of Table 1, including the optional High Demand Metadata Module. In order to assess the solution performance, the following benchmarks were used:
- IOzone N to N sequential
- IOzone random
- IOR N to 1 sequential
- MDtest
For all benchmarks listed above, the test bed had the clients as described in the Table 2 below. Since the number of compute nodes available for testing was only 16, when a higher number of threads was required, those threads were equally distributed on the compute nodes (i.e. 32 threads = 2 threads per node, 64 threads = 4 threads per node, 128 threads = 8 threads per node, 256 threads =16 threads per node, 512 threads = 32 threads per node, 1024 threads = 64 threads per node). The intention was to simulate a higher number of concurrent clients with the limited number of compute nodes available. Since the benchmarks support a high number of threads, a maximum value up to 1024 was used (specified for each test), while avoiding excessive context switching and other related side effects that can affect performance results.
Table 2 Client test bed
Number of Client nodes | 16 |
Client node | C6320 |
Processors per client node | 2 x Intel(R) Xeon(R) Gold E5-2697v4 18 Cores @ 2.30GHz |
Memory per client node | 12 x 16GiB 2400 MT/s RDIMMs |
High Performance Adapter | Mellanox ConnectX-4 InfiniBand VPI |
Operating System | CentOS 7.6 |
OS Kernel | 3.10.0-957.10.1 |
PixStor Software | 5.1.3.1 |
OFED Version | Mellanox OFED 5.0-1.0.0 |
Sequential IOzone Performance N clients to N files
Sequential N clients to N files performance was measured with IOzone version 3.487. Tests executed varied from single thread up to 512 threads on the capacity expanded solution (4x ME4084s + 4x ME484s); results from the EDR testing are contrasted with the HDR100 update.
Caching effects were minimized by setting the file system tunable page pool to 8 GiB on the clients and 24 GiB on the servers and using files twice the total memory size of the clients or servers (whichever value is larger). It is important to note that for the file system, the page pool tunable sets the maximum amount of memory used by the file system for caching data, regardless of the amount of RAM installed and free. Also, important to note is that while in previous DellEMC HPC solutions the block size for large sequential transfers is 1 MiB, the file system was formatted with 8 MiB blocks and therefore that value is used on the benchmark for optimal performance. That may look too large and apparently waste too much space, but the file system uses subblock allocation to prevent that situation. In the current configuration, each block was subdivided in 256 subblocks of 32 KiB each.
The following commands were used to execute the benchmark for writes and reads, where Threads was the variable with the number of threads used (1 to 512 incremented in powers of two), and threadlist was the file that allocated each thread on a different node, using round robin to spread them homogeneously across the 16 compute nodes.
./iozone -i0 -c -e -w -r 8M -s 128G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 8M -s 128G -t $Threads -+n -+m ./threadlist
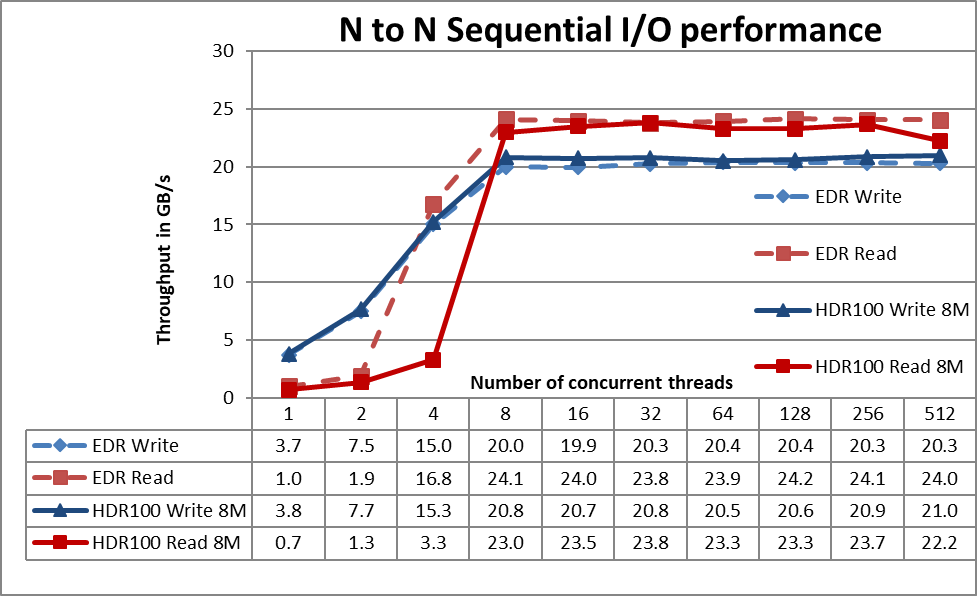
Figure 2 N to N Sequential Performance
From the results we can observe that performance rises fast with the number of clients used and then reaches a plateau that is fairly stable until the maximum number of threads that IOzone allows is reached, and therefore large file sequential performance is stable except for 512 concurrent threads (about 8% lower). The maximum read performance of 23.8 GB/s at 32 threads was still limited by the bandwidth of the two IB HDR100 links used on the storage nodes starting at 8 threads. Read performance at 4 threads is considerably lower and at high thread counts is a bit lower compared to EDR (less than 5%), but the results are reproduceable. Since the sequential N to 1 test using IOR uses the same data size and similar parameters but on a single file (adding locking overhead), the big drop in read performance at 4 threads (and to a much smaller degree at high thread counts) may be due to IOzone using calls that are working less efficiently than IOR calls, but more work is needed to find the reason for the different behavior.
The highest write performance of 21 GB/s was achieved at 512 threads. It is important to remember that for PixStor file system, the preferred mode of operation is scatter, and the solution was formatted to use such mode. In this mode, blocks are allocated from the very beginning of operation in a pseudo-random fashion, spreading data across the whole surface of each HDD. While the obvious disadvantage is a smaller initial maximum performance, that performance is maintained fairly constant regardless of how much space is used on the file system. That in contrast to other parallel file systems that initially use the outer tracks that can hold more data (sectors) per disk revolution, and therefore have the highest possible performance the HDDs can provide, but as the system uses more space, inner tracks with less data per revolution are used, with the consequent reduction of performance.
Sequential IOR Performance N clients to 1 file
Sequential N clients to a single shared file performance was measured with IOR version 3.3.0, assisted by OpenMPI v4.0.1 to run the benchmark over the 16 compute nodes. Tests executed varied from a one thread up to 512 threads (since there were not enough cores for 1024 threads), and results are contrasted to the solution without the capacity expansion.
Caching effects were minimized by setting the file system page pool tunable to 8 GiB on the clients and 24 GiB on the servers and using a total data size bigger than twice the total memory size of clients or servers (whichever is larger). This benchmark tests used 8 MiB blocks for optimal performance. The previous performance test section has a more complete explanation for those matters.
The following commands were used to execute the benchmark for writes and reads, where Threads was the variable with the number of threads used (1 to 1024 incremented in powers of two), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using round robin to spread them homogeneously across the 16 compute nodes.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b 128G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b 128G
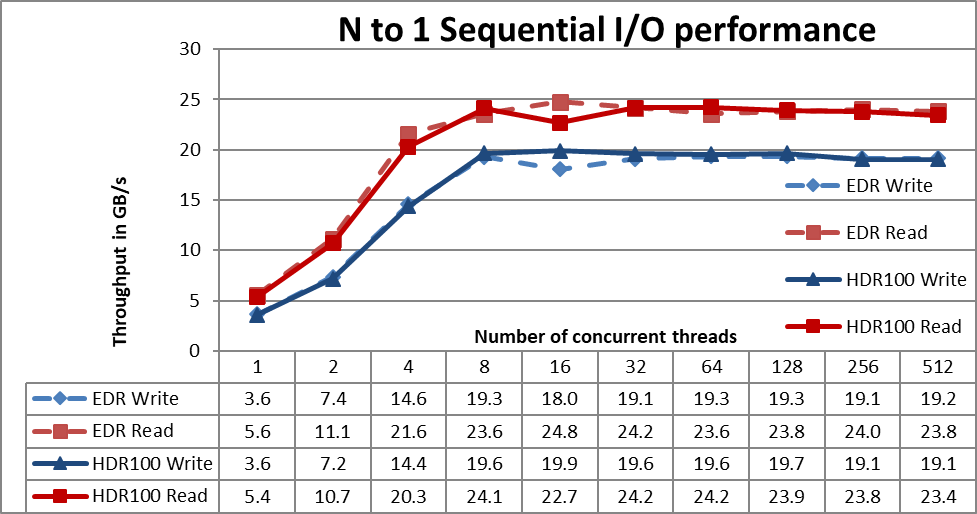
Figure 3 N to 1 Sequential Performance
Performance rises fast with the number of clients used and then reaches a plateau that is fairly stable for reads and writes from 8 threads all the way to the maximum number of threads used on this test. The maximum read performance was 24.2 GB/s at 32 threads and the bottleneck was the InfiniBand HDR100 interface apparently at higher than line speed. Similarly, notice that the maximum write performance of 19.9 GB/s was reached at 16 threads. An important data point is at 4 threads, that even that uses the same data size and parameters as IOzone with the extra burden of locking, no performance drop is observed for writes as it was for IOzone.
Random small blocks IOzone Performance N clients to N files
Random N clients to N files performance was measured with IOzone 3.487. Tests executed varied from 16 threads up to 512 threads since there was not enough client-cores for 1024 threads. Lower thread counts were not tested at this time since they take a very large execute time and IOzone does not allow to get results until the test is completed in its entirety and the most important information tends to be the maximum IOPS that the solution can provide. Each thread was using a different file and the threads were assigned on a round robin fashion to the client nodes. This benchmark used 4 KiB blocks for emulating small block traffic.
Caching effects were minimized by setting the file system page pool tunable to 8GiB on the clients and 24 GiB on the servers and using a total data size bigger than twice the total page pool size of clients or servers (whichever is larger). It is important to note that the page pool tunable sets the maximum amount of memory used by the file system for caching data, regardless the amount of RAM installed and free.
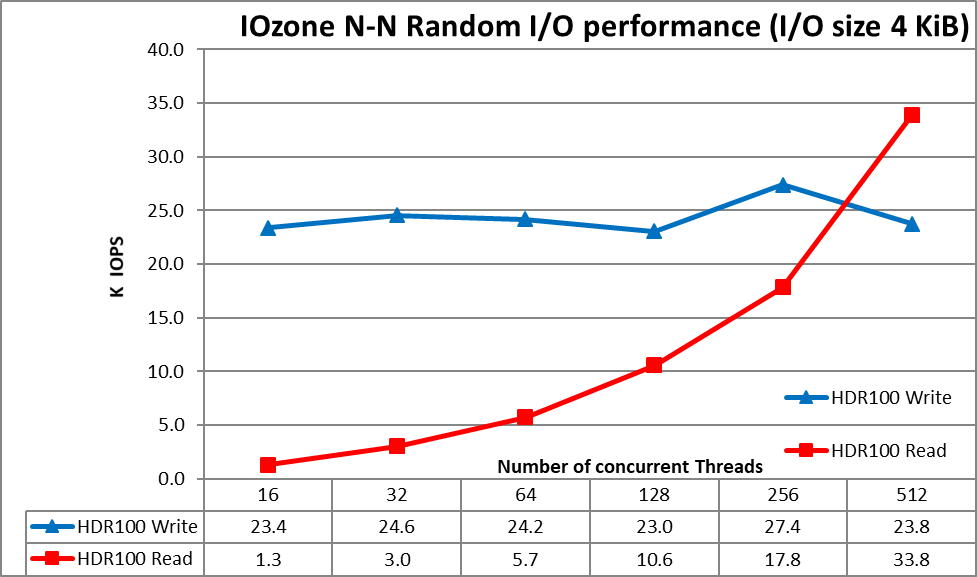
Figure 4 N to N Random Performance
From the results we can observe that write performance starts at a high value of 23.4K IOps and remains under 25K steadily up to 256 threads where it peaks at 27.4K IOps. Read performance on the other hand starts at 1.3K IOps and increases performance almost linearly with the number of threads used (keep in mind that number of threads is doubled for each data point) and reaches the maximum performance of 33.8K IOPS at 512 threads. Using more threads would require more than the 16 compute nodes or more cores per node to avoid loss of performance due to process context switching, data locality and similar effects. ME4 arrays require a higher IO pressure (queue or IO depth) to reach their maximum random IOPS showing in this test a lower apparent performance, where the arrays could in fact deliver more IOPS when using tests like FIO that can control the IO depth per process.
Metadata performance with MDtest using empty files
Metadata performance was measured with MDtest version 3.3.0, assisted by OpenMPI v4.0.1 to run the benchmark over the 16 compute nodes. Tests executed varied from single thread up to 512 threads. The benchmark was used for files only (no directory metadata), getting the number of creates, stats and removes that the solution can handle, and results were contrasted with previous EDR results.
To properly evaluate the solution in comparison to other DellEMC HPC storage solutions and the previous blog results, the optional High Demand Metadata Module was used, but with a single ME4024 array; but in fact, the large configuration tested in this work was designated to have two ME4024s.
This High Demand Metadata Module can support up to four ME4024 arrays, and it is suggested to increase the number of ME4024 arrays to 4, before adding another metadata module. Additional ME4024 arrays are expected to increase the Metadata performance with each additional array, except maybe for Stat operations, since the IOPS numbers are very high, at some point the CPUs will become a bottleneck and performance will not continue to increase linearly.
The following command was used to execute the benchmark, where Threads was the variable with the number of threads used (1 to 512 incremented in powers of two), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using round robin to spread them homogeneously across the 16 compute nodes. Similar to the Random IO benchmark, the maximum number of threads was limited to 512, since there are not enough cores for 1024 threads and context switching would affect the results, reporting a number lower than the real performance of the solution.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F
Since performance results can be affected by the total number of IOPs, the number of files per directory and the number of threads, it was decided to fix the total number of files to 2 MiB files (2^21 = 2097152), the number of files per directory fixed at 1024, and the number of directories varied as the number of threads changed as shown in Table 3.
Table 3 MDtest distribution of files on directories
Number of Threads | Number of directories per thread | Total number of files |
1 | 2048 | 2,097,152 |
2 | 1024 | 2,097,152 |
4 | 512 | 2,097,152 |
8 | 256 | 2,097,152 |
16 | 128 | 2,097,152 |
32 | 64 | 2,097,152 |
64 | 32 | 2,097,152 |
128 | 16 | 2,097,152 |
256 | 8 | 2,097,152 |
512 | 4 | 2,097,152 |
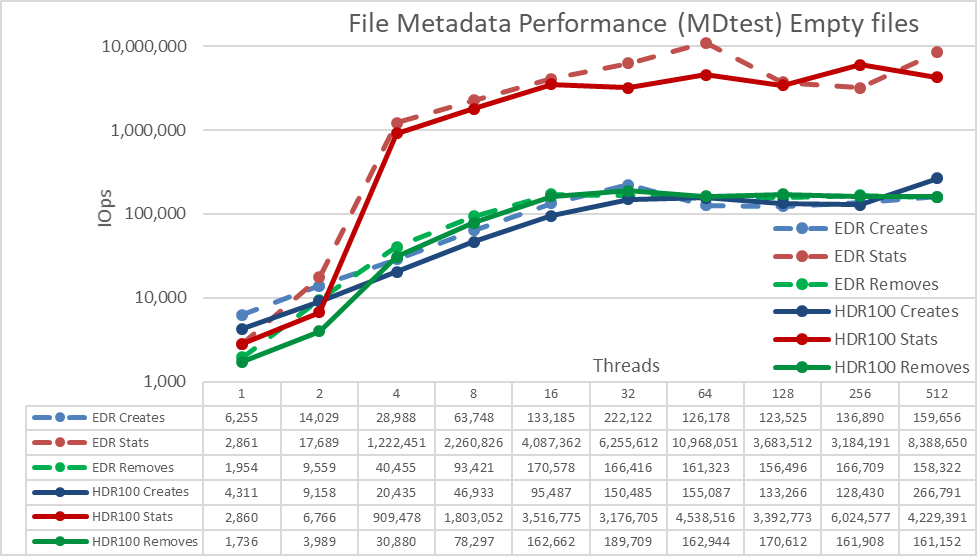
Figure 5 Metadata Performance - Empty Files
First, note that the scale chosen was logarithmic with base 10, to allow comparing operations that have differences several orders of magnitude; otherwise some of the operations would look like a flat line close to 0 on a normal graph. A log graph with base 2 could be more appropriate, since the number of threads are increased in powers of 2, but the graph would look very similar and people tend to handle and remember better numbers based on powers of 10.
The system gets very good results with Stat operations reaching their peak value at 256 threads with 6M op/s respectively. Removal operations attained the maximum of 189.7K op/s at 32 threads and Create operations achieving their peak at 512 threads with 266.8.1K op/s. Stat operation have more variability, but once they reach their peak value, performance does not drop below 3M op/s for Stats. Create and Removal are more stable once their reach a plateau and remain above 160K op/s for Removal and 128K op/s for Create.
Metadata performance with MDtest using 4 KiB files
This test is almost identical to the previous one, except that instead of empty files, small files of 4KiB were used.
The following command was used to execute the benchmark, where Threads was the variable with the number of threads used (1 to 512 incremented in powers of two), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using round robin to spread them homogeneously across the 16 compute nodes.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
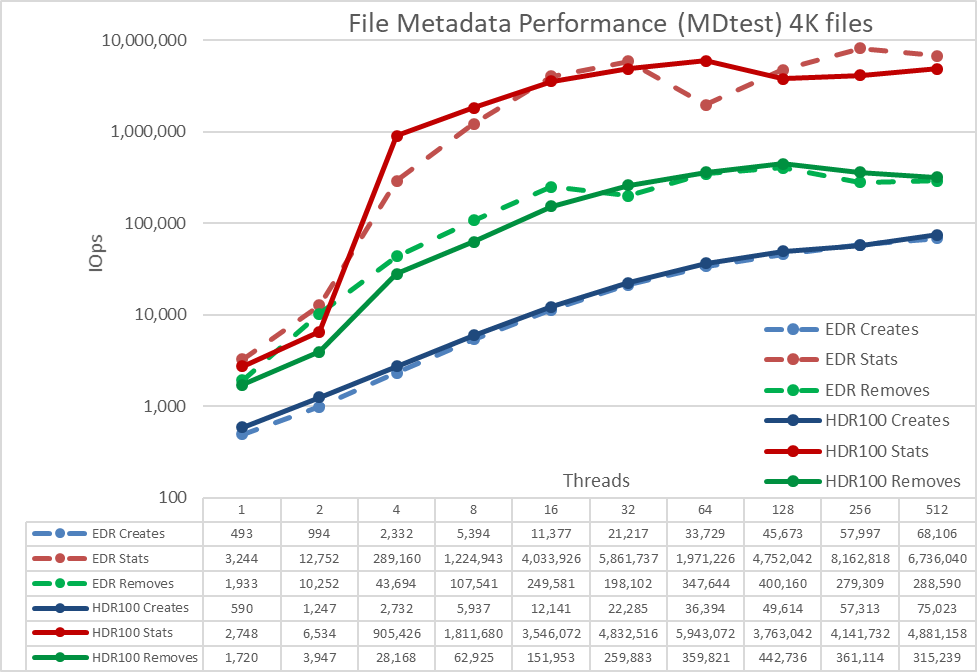
Figure 6 Metadata Performance - Small files (4K)
The system gets very good results for Stat reaching a peak value at 512 threads with almost 4.9M op/s. Remove operations attained the maximum of 442.7K op/s at 128 threads and Create operations achieving their peak with 75K op/s at 512 threads and apparently not reaching a plateau yet. Stat and Removal operations have more variability, but once they reach their peak value, performance does not drop below 3.5M op/s for Stats and 315K op/s for Removal. Create and Read have less variability and keep increasing as the number of threads grows.
Since these numbers are for a metadata module with a single ME4024, performance will increase for each additional ME4024 array, however we cannot simply assume a linear increase for each additional ME4024. Unless the whole file fits inside the inode for such file, data targets on the ME4084s will be used to store part of the 4K files, limiting the performance to some degree. Since the inode size is 4KiB and it still needs to store metadata, only files around 3 KiB will fit inside and any file bigger than that will use data targets.
Conclusions and Future Work
The solution has similar performance to that observed with the Infiniband EDR technology. An overview of the performance for HDR100 can be seen in Table 4; it is expected to be stable from an empty file system until is almost full because of the use of Scatter allocation across the whole surface area of ALL HDDs. Furthermore, the solution scales in capacity and performance linearly as more storage node modules are added, and a similar performance increase can be expected from the optional high demand metadata module. This solution provides HPC customers with a very reliable parallel file system used by many Top 500 HPC clusters. In addition, it provides exceptional search capabilities, advanced monitoring and management. With the addition of optional gateway nodes, it allows file sharing via ubiquitous standard protocols like NFS, SMB to as many clients as needed. Finally, Ngenea nodes allow efficient access to other cost-effective storage tiers such as ECS, Isilon enterprise NAS and Cloud solutions using different protocols.
Table 4 Peak & Sustained Performance
| Peak Performance | Sustained Performance | ||
Write | Read | Write | Read | |
Large Sequential N clients to N files | 21.0 GB/s | 23.8 GB/s | 20.5 GB/s | 23.0 GB/s |
Large Sequential N clients to single shared file | 19.9 GB/s | 24.2 GB/s | 19.1 GB/s | 23.4 GB/s |
Random Small blocks N clients to N files | 33.8KIOps | 27.4KIOps | 33.80KIOps | 23.0KIOps |
Metadata Create empty files | 266.8K IOps | 128K IOps | ||
Metadata Stat empty files | 6M IOps | 3M IOps | ||
Metadata Remove empty files | 189.7K IOps | 160K IOps | ||
Metadata Create 4KiB files | 75K IOps | 75K IOps | ||
Metadata Stat 4KiB files | 4.9M IOps | 3.5M IOps | ||
Metadata Remove 4KiB files | 442.7K IOps | 315K IOps | ||
Performance for the gateway nodes was measured and will be reported in a new blog. Finally, high performance NVMe nodes are being tested and results will also be released in a different blog.