



Multinode Performance of Dell PowerEdge Servers with MLPerfTM Training v1.1
Mon, 07 Mar 2022 19:51:12 -0000
|Read Time: 0 minutes
The Dell MLPerf v1.1 submission included multinode results. This blog showcases performance across multiple nodes on Dell PowerEdge R750xa and XE8545 servers and demonstrates that the multinode scaling performance was excellent.
The compute requirement for deep learning training is growing at a rapid pace. It is imperative to train models across multiple nodes to attain a faster time-to-solution. Therefore, it is critical to showcase the scaling performance across multiple nodes. To demonstrate to customers the performance that they can expect across multiple nodes, our v1.1 submission includes multinode results. The following figures show multinode results for PowerEdge R750xa and XE8545 systems.
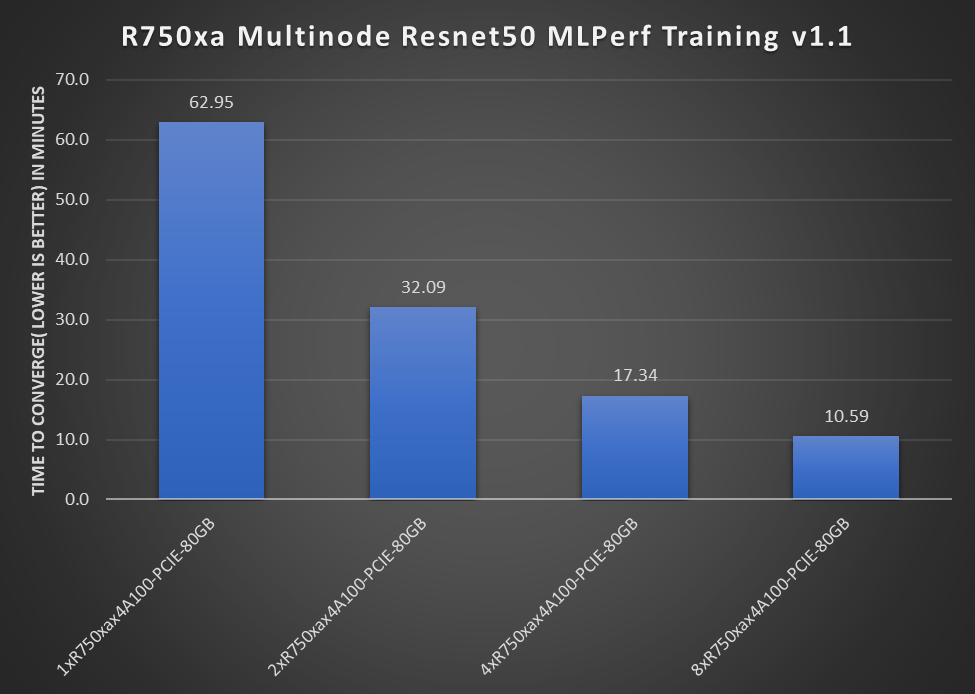
Figure 1: One-, two-, four-, and eight-node results with PowerEdge R750xa Resnet50 MLPerf v1.1 scaling performance
Figure 1 shows the performance of the PowerEdge R750xa server with Resnet50 training. These numbers scale from one node to eight nodes, from four NVIDIA A100-PCIE-80GB GPUs to 32 NVIDIA A100-PCIE-80GB GPUs. We can see that the scaling is almost linear across nodes. MLPerf training requires passing Reference Convergence Points (RCP) for compliance. These RCPs were inhibitors to show linear scaling for the 8x scaling case. The near linear scaling makes a PowerEdge R750xa node an excellent choice for multinode training setup.
The workload was distributed by using singularity on PowerEdge R750xa servers. Singularity is a secure containerization solution that is primarily used in traditional HPC GPU clusters. Our submission includes setup scripts with singularity that help traditional HPC customers run workloads without the need to fully restructure their existing cluster setup. The submission also includes Slurm Docker-based scripts.
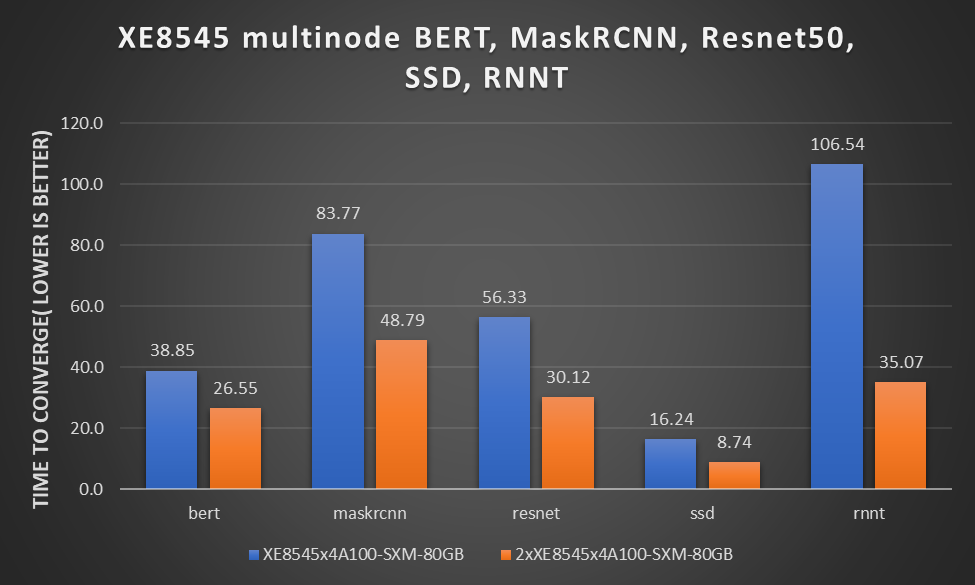
Figure 2: Multinode submission results for PowerEdge XE8545 server with BERT, MaskRCNN, Resnet50, SSD, and RNNT
Figure 2 shows the submitted performance of the PowerEdge XE8545 server with BERT, MaskRCNN, Resnet50, SSD, and RNNT training. These numbers scale from one node to two nodes, from four NVIDIA A100-SXM-80GB GPUs to eight NVIDIA A100-SXM-80GB GPUs. All GPUs operate at 500W TDP for maximum performance. They were distributed using Slurm and Docker on PowerEdge XE8545 servers. The performance is nearly linear.
Note: The RNN-T single node results submitted for the PowerEdge XE8545x4A100-SXM-80GB system used a different set of hyperparameters than for two nodes. After the submission, we ran the RNN-T benchmark again on the PowerEdge XE8545x4A100-SXM-80GB system with the same hyperparameters and found that the new time to converge is approximately 77.37 minutes. Because we only had the resources to update the results for the 2xXE8545x4A100-SXM-80GB system before the submission deadline, the MLCommons results show 105.6 minutes for a single node XE8545x4100-SXM-80GB system.
The following figure shows the adjusted representation of performance for the PowerEdge XE8545x4A100-SXM-80GB system. RNN-T provides an unverified score of 77.31 minutes[1]:
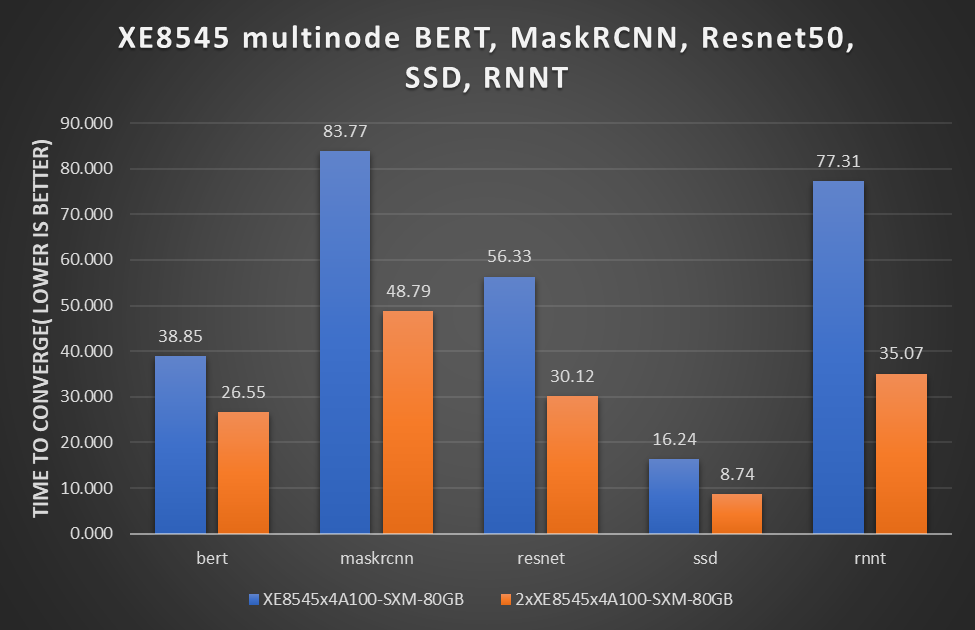
Figure 3: Revised multinode results with PowerEdge XE8545 BERT, MaskRCNN, Resnet50, SSD, and RNNT
Figure 3 shows the linear scaling abilities of the PowerEdge XE8545 server across different workloads such as BERT, MaskRCNN, ResNet, SSD, and RNNT. This linear scaling ability makes the PowerEdge XE8545 server an excellent choice to run large-scale multinode workloads.
Note: This rnnt.zip file includes log files for 10 runs that show that the averaged performance is 77.31 minutes.
Conclusion
- It is critical to measure deep learning performance across multiple nodes to assess the scalability component of training as deep learning workloads are growing rapidly.
- Our MLPerf training v1.1 submission includes multinode results that are linear and perform extremely well.
- Scaling numbers for the PowerEdge XE8545 and PowerEdge R750xa server make them excellent platform choices for enabling large scale deep learning training workloads across different areas and tasks.
[1] MLPerf v1.1 Training RNN-T; Result not verified by the MLCommonsTM Association. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See http://www.mlcommons.org for more information.