




Model Deployments Made Easy by Dell Enterprise Hub on PowerEdge XE9680 with AMD MI300X


Overview
The Dell Enterprise Hub is a game changer for obtaining and using optimized models that run on the Dell PowerEdge XE9680 with AMD MI300X. The Dell Enterprise Hub (DEH) offers a curated set of models that have been thoughtfully packaged with the right software stack in partnership with Hugging Face and AMD and delivered as a container for ease of deployment. These containers are optimized for maximum performance on Dell hardware with current optimization techniques and have been thoroughly tested on the Dell PowerEdge XE9680 with AMD MI300X. These optimization techniques, conducted by AMD and Hugging Face, include composable kernel-based flash attention, custom paged attention enabled, custom kernel, hip graph, pytorch tunableop, and quantization techniques like gptq, awq, and fp8. This is a result of the hard work of engineers from AMD, Dell Technologies, and Hugging Face, allowing you to tune the software stack and determine how you want to deploy the model on the Dell PowerEdge XE9680 with AMD MI300X quickly and with ease.
This blog showcases how you can go from the Dell Enterprise Hub to a running model in a matter of minutes, stepping through the setup from the beginning to when the container(s) are running.
Implementation
Dell Optimized containers are built on top of the text generation inference (TGI) framework, which allows you to rely on all the existing benefits of TGI while enjoying optimization for Dell products. Additionally, Dell containers come preconfigured with all the required model weights and software components, so no additional steps are needed to get your system up and running.
Here, we will focus on the simpler case of deploying a model for inference. Dell Enterprise Hub also offers containers that can be used for model training which will be covered in a future blog for the AMD platform
Server setup
During our optimization and validation, we worked on a Dell XE9680 server with 8 AMD Mi300X GPUs.
Hardware
Table 1. Dell XE9680 Server with 8 AMD Mi300x GPUs hardware setup
CPU | 2 x Intel® Xeon® Platinum 8468 (48 cores each) |
Memory | 4TB |
Storage | 2TB local storage |
GPU | 8 x AMD MI300X |
This server has the capacity to run multiple parallel AI workloads and contains the maximum number of GPUs supported.
Software
Following is the software stack along with the versions used:
- Ubuntu 22.04
- Docker 24.0.7
- AMD ROCm 6.2
ROCm is an open source framework designed for GPU computation with AMD. The framework consists of multiple low-level APIs and development tools to help execute workloads on AMD GPUs. For more information, see the AMD ROCm documentation .
To install ROCm, we recommend following the detailed install guide for your specific platform that is available from AMD. Once the install is complete, test that the library is available via Docker containers since this will be part of the next stage when deploying DEH models. To do this, use the following:
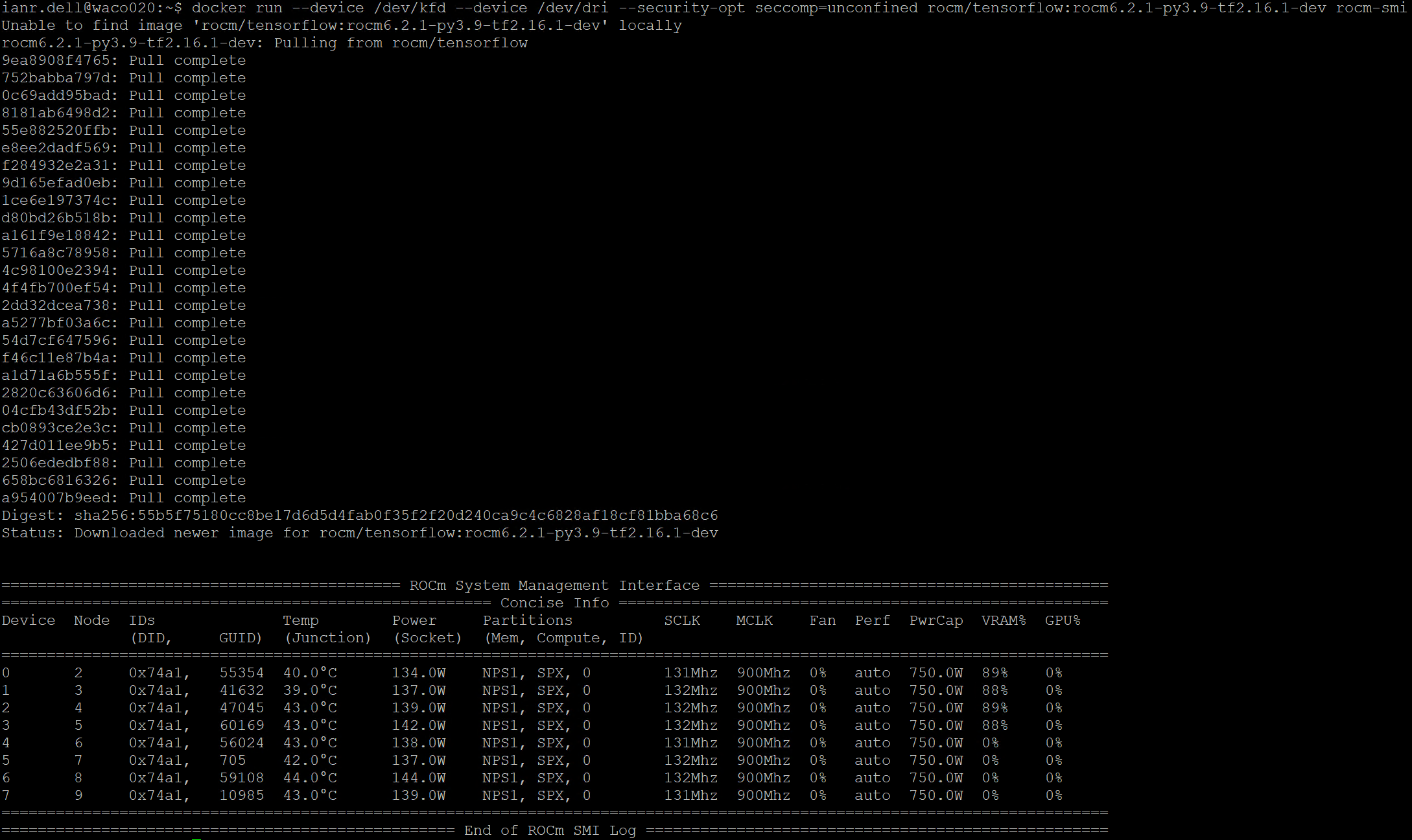
docker run --device /dev/kfd --device /dev/dri --security-opt seccomp=unconfined rocm/tensorflow:rocm6.2.1-py3.9-tf2.16.1-dev rocm-smi
This command launches a container that is preconfigured to run TensorFlow workloads on AMD GPUs. The details of the docker command will be explained in the next section. This command lists all GPUs along with their utilization, as shown in the following figure.
Following is an illustration of the software stack used for this testing:
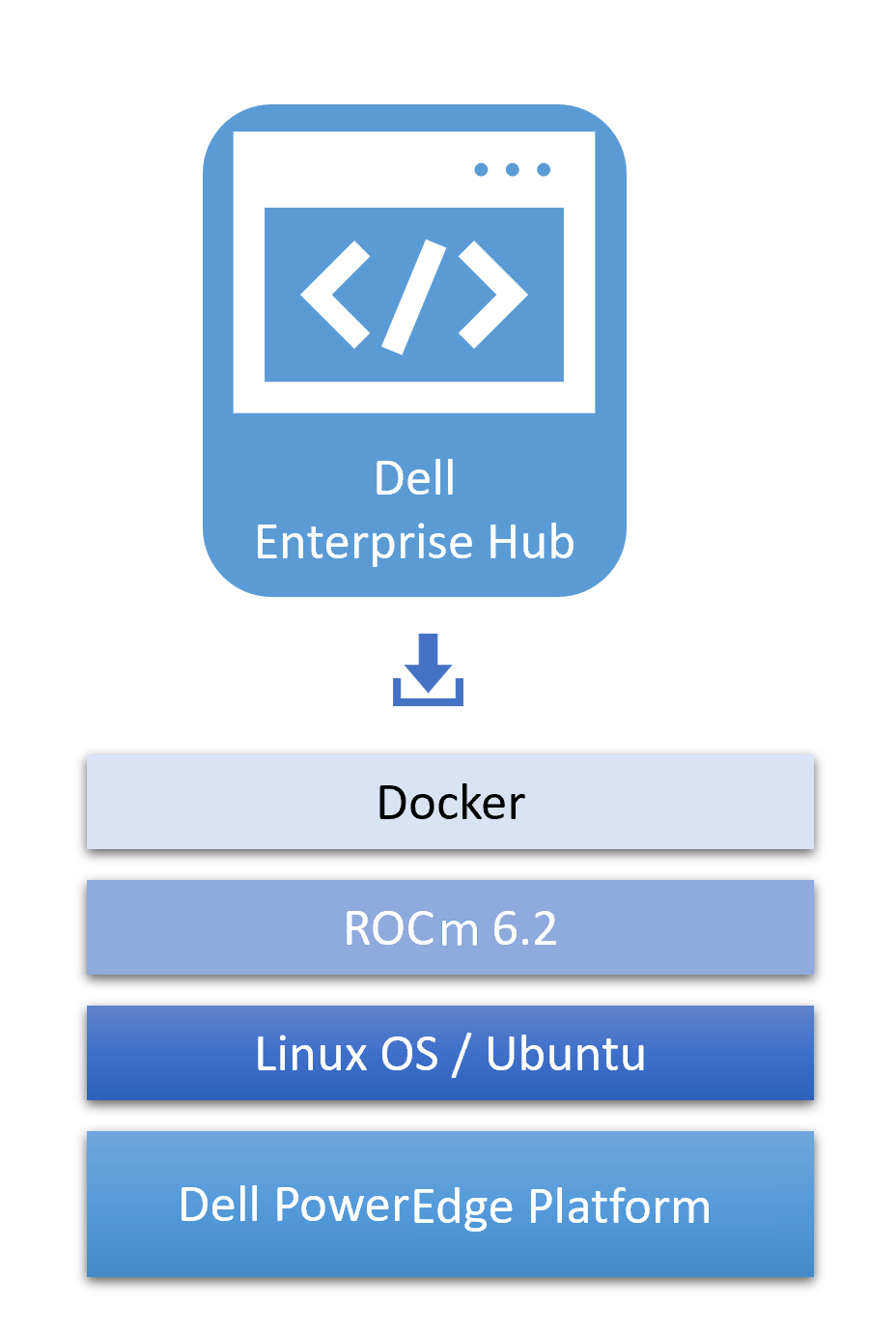
Optimized containers from Dell Enterprise Hub
Select a model
The Dell Enterprise Hub contains an expanding set of models that are optimized to run on Dell hardware with AMD. To select a model, navigate to https://dell.huggingface.com/ and select your model of choice. Here, we will use the Llama 3.1 8B model for demonstration, however the DEH supports a wide variety of models for AMD.
Following is a sample portal screen for the deployment of the Llama3 8B model on a Dell PowerEdge XE9680 server with MI300X GPUs:
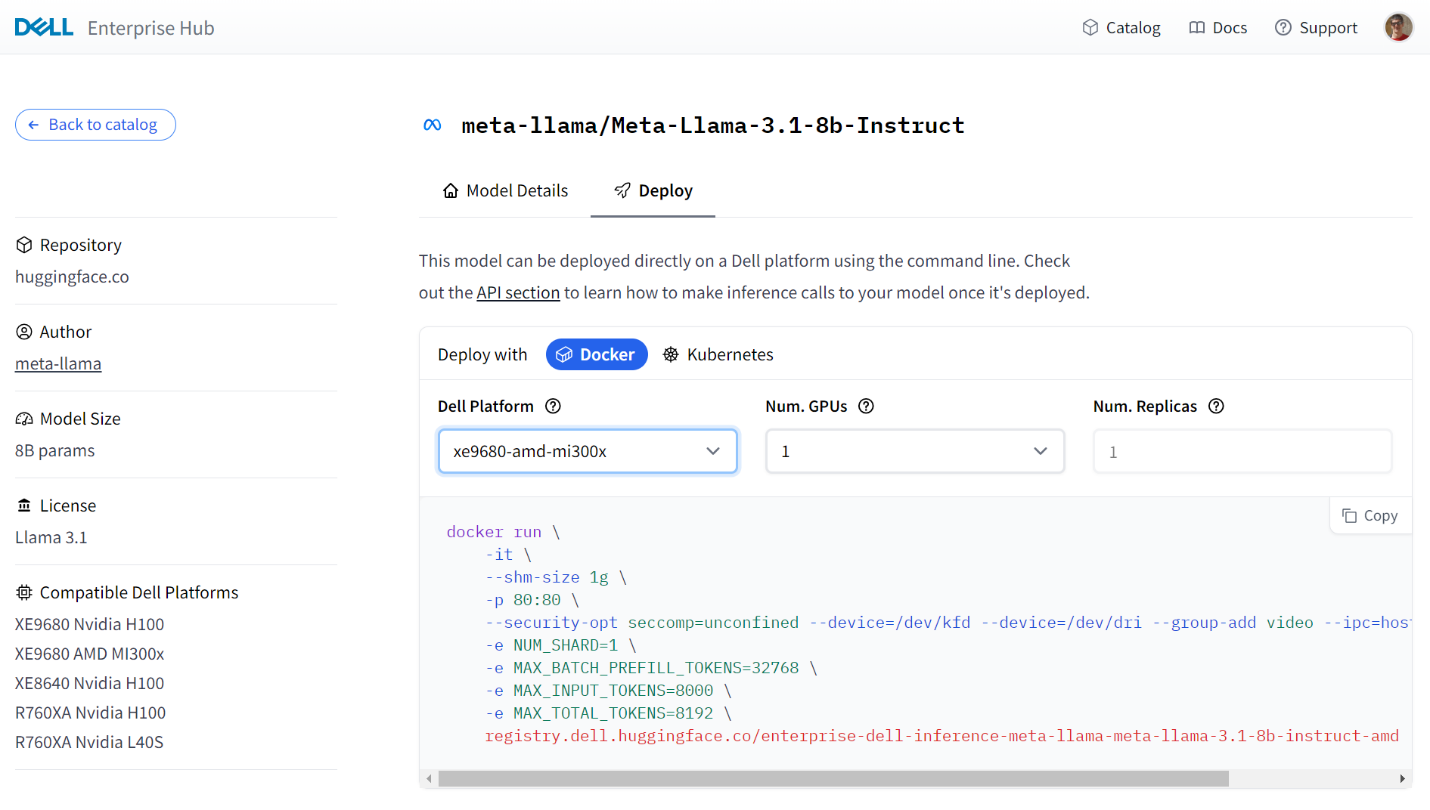
Some models on the Dell Enterprise Hub will require you to request or agree to terms set out by the model authors (e.g Llama). This must be done before running those containers.
Container deployment
From the portal, the following Docker run command was generated based on number of GPUs:
docker run \ -it \ --shm-size 1g \ -p 80:80 \ --security-opt seccomp=unconfined --device=/dev/kfd --device=/dev/dri --group-add video --ipc=host --shm-size 256g \ -e NUM_SHARD=1 \ -e MAX_BATCH_PREFILL_TOKENS=32768 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-8b-instruct-amd
This can be executed as-is on your Dell server, which will pull and execute the model locally. The AMD-specific parameters in the command are as follows:
Table 2. AMD-specific parameters for container deployment
| Command | Details |
|---|---|
--device=/dev/kfd | This is the main compute interface that is shared by all 8 GPUs |
--device=/dev/dri | This is the Direct Rendering Interface (DRI) for all GPUs. Setting this enables the container to access all GPUs in the system. |
--group-add video | This allows the container access to a video group and is required to interact with AMD GPUs. |
--security-opt seccomp=unconfined | Enables memory mapping features. This is optional. |
registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-8b-instruct-amd | This is the location in the Dell Enterprise Hub for the Llama 3.1 8B AMD compatible container. |
In this command, all 8 AMD GPUs are visible to the container. Not all will be used, however in most cases, multiple models will run on a single server. To isolate and assign specific AMD GPUs to containers, please see the AMD documentation for GPU isolation techniques.
When running a standard Docker command, you are expected to provide your HF Token associated with your HF Login.
You can specify your token in one of two ways:
- Set your token as an environment variable “HUGGING_FACE_HUB_TOKEN”
- Add it to each Docker container run command “-e HUGGING_FACE_HUB_TOKEN=$token”
It is important to secure your token and not to post it in any public repository. For greater detail on how to use tokens, see the Hugging Face documentation of private and gated models .
Testing the deployment
The DEH containers expose http endpoints that can be used to execute queries in various formats. The full swagger definition of the API is available at https://huggingface.github.io/text-generation-inference/#/ .
For a simple test, we can use the “generate” endpoint to POST a simple query to the model that we ran in the previous step:
curl 127.0.0.1:80/generate \
-X POST \
-d '{"inputs":"Who are AMD?", "parameters":{"max_new_tokens":50}}' \
-H 'Content-Type: application/json'This produces the following output:
{"generated_text":" AMD (Advanced Micro Devices) is a multinational semiconductor company that specializes in the design and manufacture of computer processors, graphics processing units (GPUs), and other semiconductor products. AMD was founded in 1969 and is headquartered in Santa Clara, California."}The response is generated and keeps within the limit of 50 tokens that was specified in the query.
Conclusion
Dell Enterprise Hub simplifies the deployment and execution of the latest AI models. The prebuilt containers run seamlessly on Dell hardware. In this example, we showed how easy it is to run the latest large language models on AMD GPUs. Getting the open-source models and open-source software stack to production isn't easy with many software dependencies, configurations, knobs, and switches along the way. The choices you make in those implementations drastically impact performance and scale and take weeks and/or months of effort to tune. Dell Enterprise Hub is a result of the partnership and collaboration between Dell Technologies and Hugging Face and strives to address those challenges, making it easier for customers to consume those incredible open-source models in their AI systems on Dell PowerEdge platforms.
Authors: Ian Roche, Balachandran Rajendran