



Introduction to MLPerf™ Inference v1.0 Performance with Dell EMC Servers
Wed, 15 Sep 2021 12:09:44 -0000
|Read Time: 0 minutes
This blog provides MLPerf inference v1.0 data center closed results on Dell servers running the MLPerf inference benchmarks. Our results show optimal inference performance for the systems and configurations on which we chose to run inference benchmarks.
The MLPerf benchmarking suite measures the performance of machine learning (ML) workloads. Currently, these benchmarks provide a consistent way to measure accuracy and throughput for the following aspects of the ML life cycle:
- Training—The MLPerf training benchmark suite measures how fast a system can train ML models.
- Inference—The MLPerf inference benchmark measures how fast a system can perform ML inference by using a trained model in various deployment scenarios.
MLPerf is now a part of the MLCommons™ Association. MLCommons is an open engineering consortium that promotes the acceleration of machine learning innovation. Its open collaborative engineering solutions support your machine learning needs. MLCommons provides:
- Benchmarks and metrics
- Datasets and models
- Best practices
MLPerf inference overview
As of March 2021, MLPerf inference has submitted three versions: v0.5, v0.7, and v1.0. The latest version, v1.0, uses the same benchmarks as v0.7 with the following exceptions:
- Power submission—Power submission, which is a wrapper around inference submission, is supported.
- Error connection code (ECC)—The ECC must set to ON.
- 10-minute runtime—The default benchmark run time is 10 minutes.
- Required number of runs for submission and audit tests—The number of runs that are required to submit Server scenario is one.
v1.0 meets v0.7 requirements, therefore v1.0 results are comparable to v0.7 results. Because the MLPerf v1.0 submissions are more restrictive, the v0.7 results do not meet v1.0 requirements.
In the MLPerf inference evaluation framework, the LoadGen load generator sends inference queries to the system under test (SUT). In our case, the SUTs are Dell EMC servers with various GPU configurations. The SUTs uses a backend (for example, TensorRT, TensorFlow, or PyTorch) to perform inferencing and returns the results to LoadGen.
MLPerf has identified four different scenarios that enable representative testing of a wide variety of inference platforms and use cases. The main differences between these scenarios are based on how the queries are sent and received:
- Offline—One query with all samples is sent to the SUT. The SUT can send the results back once or multiple times in any order. The performance metric is samples per second.
- Server—The queries are sent to the SUT following a Poisson distribution (to model real-world random events). One query has one sample. The performance metric is queries per second (QPS) within latency bound.
- Single-stream—One sample per query is sent to the SUT. The next query is not sent until the previous response is received. The performance metric is 90th percentile latency.
- Multi-stream—A query with N samples is sent with a fixed interval. The performance metric is max N when the latency of all queries is within a latency bound.
MLPerf Inference Rules describes detailed inference rules and latency constraints. This blog focuses on Offline and Server scenarios, which are designed for data center environments. Single-stream and Multi-stream scenarios are designed for non-datacenter (edge and IoT) settings.
MLPerf inference results are submitted under either of the following divisions:
- Closed division—The Closed division provides a “like-to-like” comparison of hardware platforms or software frameworks. It requires using the same model and optimizer as the reference implementation.
The Closed division requires using preprocessing, postprocessing, and model that is equivalent to the reference or alternative implementation. It allows calibration for quantization and does not allow retraining. MLPerf provides a reference implementation of each benchmark. The benchmark implementation must use a model that is equivalent, as defined in MLPerf Inference Rules, to the model used in the reference implementation.
- Open division—The Open division promotes faster models and optimizers and allows any ML approach that can reach the target quality. It allows using arbitrary preprocessing or postprocessing and model, including retraining. The benchmark implementation may use a different model to perform the same task.
To allow the like-to-like comparison of Dell Technologies results and enable our customers and partners to repeat our results, we chose to test under the Closed division, as the results in this blog show.
Criteria for MLPerf Inference v1.0 benchmark result submission
For any benchmark, the result submission must meet all the specifications shown in the following table. For example, if we choose the Resnet50 model, then the submission must meet the 76.46 percent target accuracy and the latency must be within 15 ms for the standard image dataset with dimensions of 224 x 224 x 3.
Table 1: Closed division benchmarks for MLPerf inference v1.0 with expectations
Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint |
Vision | Image classification | Resnet50 – v1.5 | Standard image dataset (224 x 224 x3) | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection (large) | SSD-Resnet34 | COCO (1200 x 1200) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical image segmentation | 3D UNet | BraTs 2019 (224 x 224 x 160) | 16 | 99% of FP32 and 99.9% of FP32 (0.85300 mean DICE score) | N/A |
Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) | 2513
| 99% of FP32 (1 - WER, where WER=7.452253714852645%)
| 1000 ms |
Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) | 10833
| 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Commerce | Recommendation | DLRM | 1 TB Click Logs | 204800 | 99% of FP32 and 99.9% of FP32 (AUC=80.25%) | 30 ms |
It is not mandatory to submit all the benchmarks. However, if a specific benchmark is submitted, then all the required scenarios for that benchmark must also be submitted.
Each data center benchmark requires the scenarios in the following table:
Table 2: Tasks and corresponding required scenarios for data center benchmark suite in MLPerf inference v1.0.
Area | Task | Required scenario |
Vision | Image classification | Server, Offline |
Vision | Object detection (large) | Server, Offline |
Vision | Medical image segmentation | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Commerce | Recommendation | Server, Offline |
SUT configurations
We selected the following servers with different types of NVIDIA GPUs as our SUT to conduct data center inference benchmarks. The following table lists the MLPerf system configurations:
Table 3: MLPerf system configurations
Platform | Dell EMC DSS8440_A100 | Dell EMC DSS8440_A40 | PowerEdge R750xa | PowerEdge XE8545 |
MLPerf System ID | DSS8440_A100-PCIE-40GBx10_TRT | DSS8440_A40x10_TRT | R750xa_A100-PCIE-40GBx4_TRT | XE8545_7713_A100-SXM4-40GBx4 |
Operating system | CentOS 8.2.2004 | CentOS 8.2.2004 | CentOS 8.2.2004 | CentOS 8.2.2004 |
CPU | 2 x Intel Xeon Gold 6248 CPU @ 2.50 GHz | 2 x Intel Xeon Gold 6248R CPU @ 3.00 GHz | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz | 2 x AMD EPYC 7713 |
Memory | 768 GB | 768 GB | 256 GB | 1 TB |
GPU | NVIDIA A100-PCIe-40GB | NVIDIA A40 | NVIDIA A100-PCIE-40GB | NVIDIA A100-SXM4-40GB |
GPU Form Factor | PCIE | PCIE | PCIE | SXM4 |
GPU count | 10 | 10 | 4 | 4 |
Software Stack | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 |
MLPerf inference 1.0 benchmark results
The following graphs include performance metrics for the Offline and Server scenarios.
For the Offline scenario, the performance metric is Offline samples per second. For the Server scenario, the performance metric is queries per second (QPS). In general, the metrics represent throughput. A higher throughput is a better result.
Resnet50 results
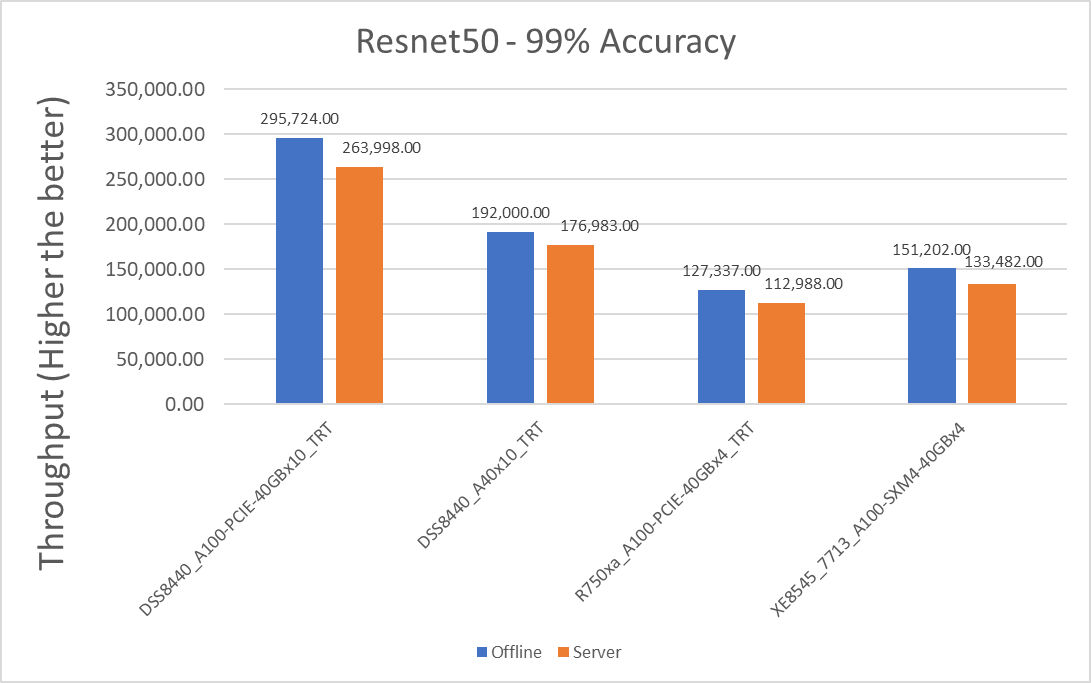
Figure 1: Resnet50 v1.5 Offline and Server scenario with 99 percent accuracy target
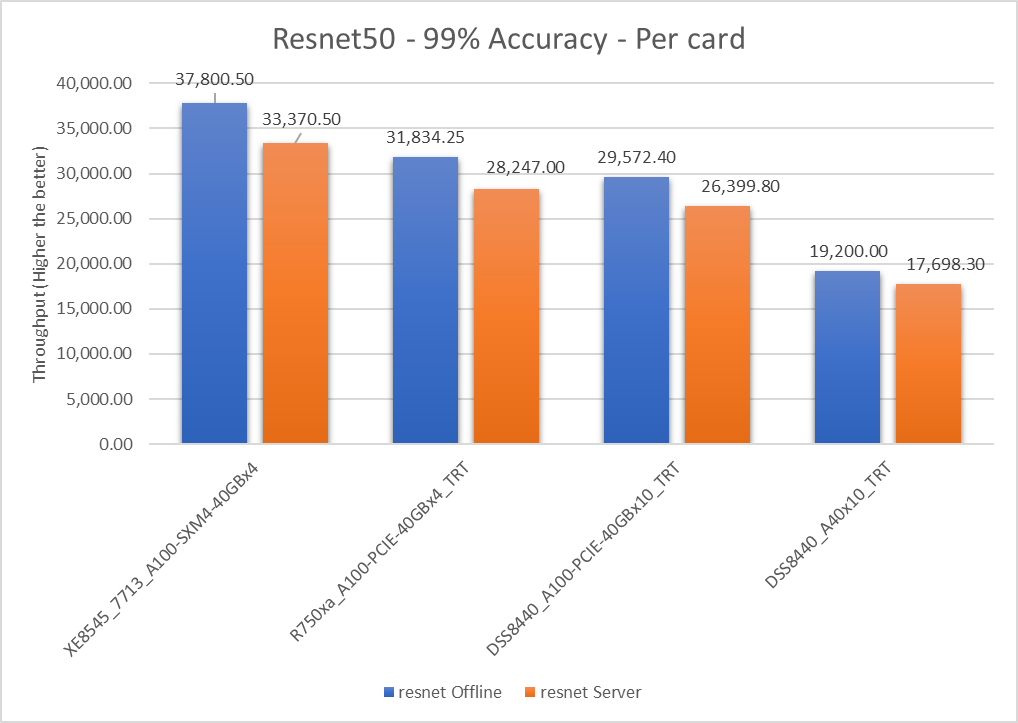
Figure 2: Resnet50 v1.5 Offline and Server scenario with 99 percent accuracy target per card
Table 4: Per card numbers and scenario percentage difference
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 37800.5 | 33370.5 | 12.44 |
R750xa_A100-PCIE-40GBx4_TRT | 31834.25 | 28247 | 11.94 |
DSS8440_A100-PCIE-40GBx10_TRT | 29572.4 | 26399.8 | 11.33 |
DSS8440_A40x10_TRT | 19200 | 17698.3 | 8.139 |
The Offline per card throughput exceeds the Server per card throughput for all the servers in this study.
Table 5: Per card percentage difference from a XE8545_7713_A100-SXM4-40GBx4 system
Dell Server | Offline (in percentage) | Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 17.13 | 16.63 |
DSS8440_A100-PCIE-40GBx10_TRT | 24.42 | 26.39 |
DSS8440_A40x10_TRT | 65.26 | 61.37 |
SSD-Resnet34 results
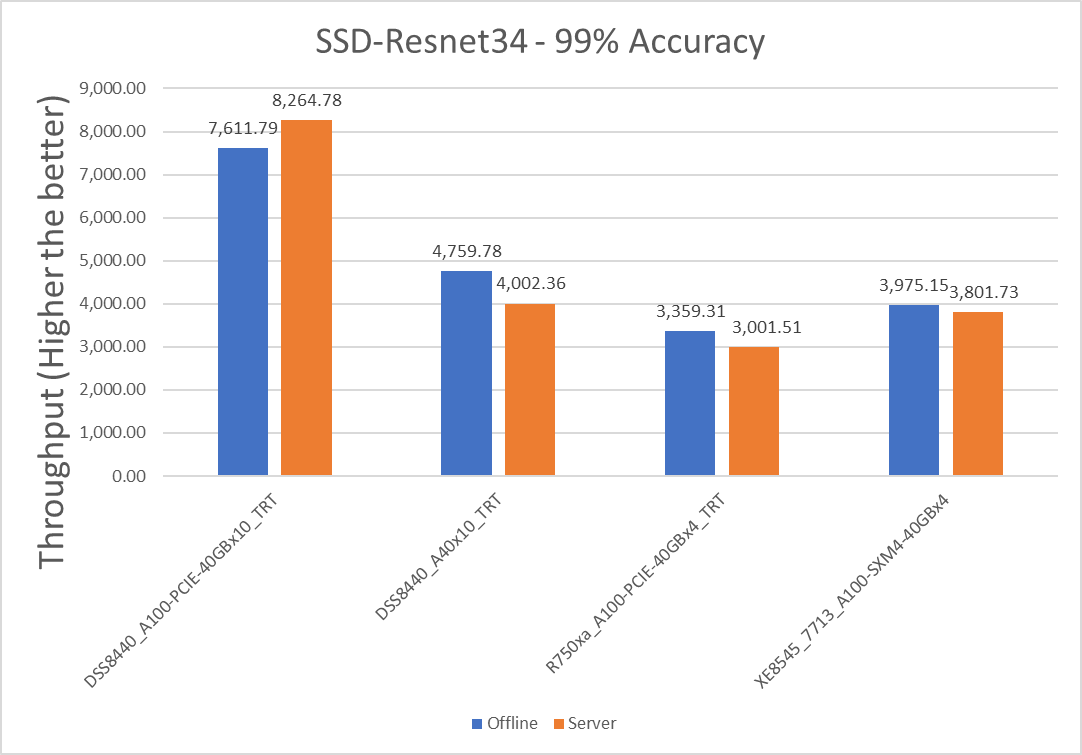
Figure 3: SSD with Resnet34 Offline and Server scenario with 99 percent accuracy target
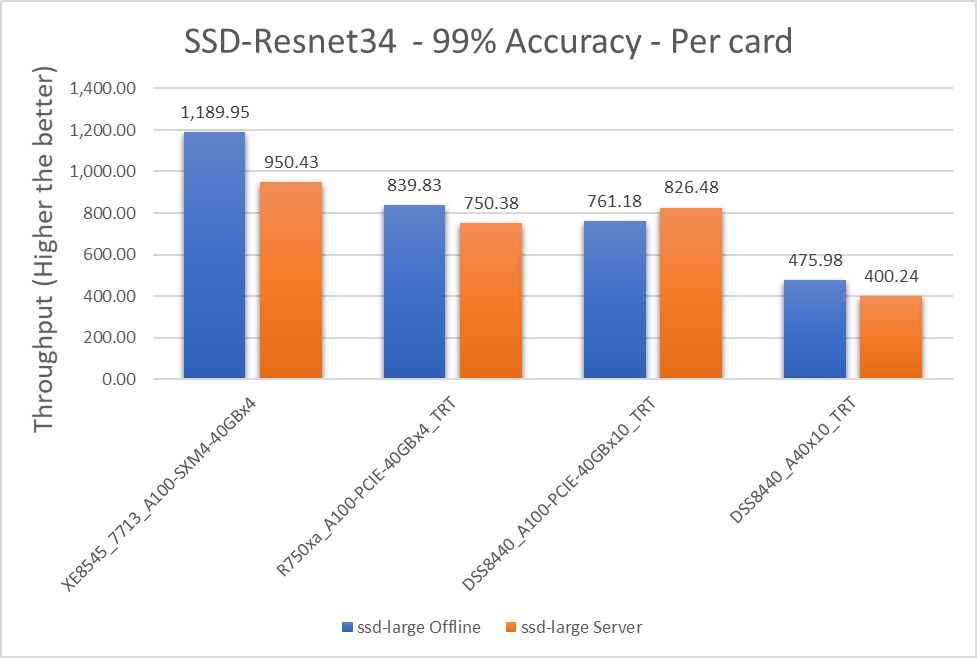
Figure 4: SSD-Resnet34, Offline and Server scenario with 99 percent accuracy targets per card
Table 6: Per card numbers and scenario percentage difference on SSD-Resnet34
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 1189.945 | 950.4325 | 22.38 |
R750xa_A100-PCIE-40GBx4_TRT | 839.8275 | 750.3775 | 11.25 |
DSS8440_A100-PCIE-40GBx10_TRT | 761.179 | 826.478 | -8.22 |
DSS8440_A40x10_TRT | 475.978 | 400.236 | 17.28 |
Note: A negative value of percentage difference indicates the Server scenario outperformed the Offline scenario.
Table 7: Per card percentage difference from a XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | Offline (in percentage) | Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 34.4982 | 23.52 |
DSS8440_A100-PCIE-40GBx10_TRT | 43.95067 | 13.95 |
DSS8440_A40x10_TRT | 85.71429 | 81.47 |
BERT Results
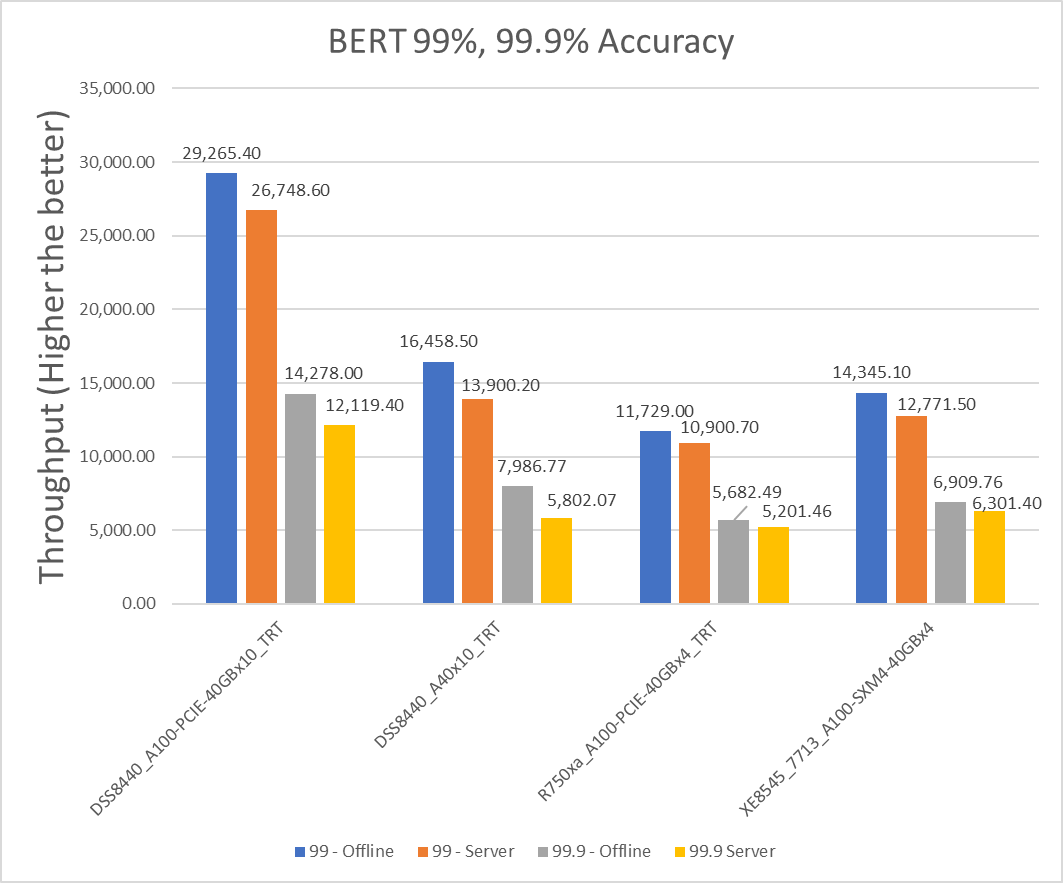
Figure 4: BERT Offline and Server scenario with 99 percent and 99.9 percent accuracy targets
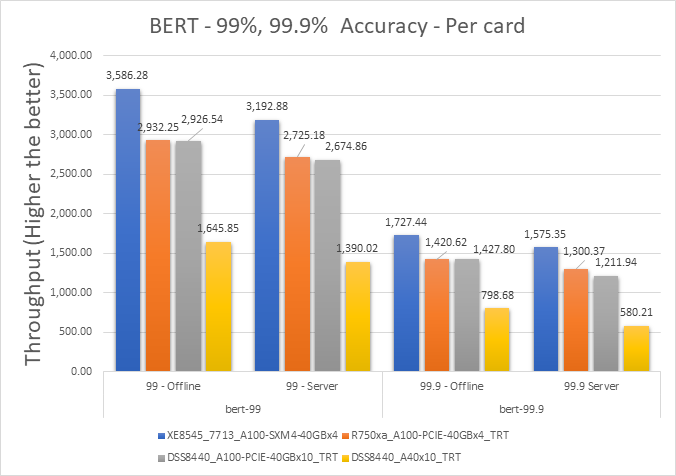
Figure 5: BERT Offline and Server scenario with 99 percent and 99.9 percent accuracy targets per card
Table 8: Per card numbers and scenario percentage difference on BERT with 99 percent accuracy target
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 3586.275 | 3192.875 | 11.60617482 |
R750xa_A100-PCIE-40GBx4_TRT | 2932.25 | 2725.175 | 7.320468234 |
DSS8440_A100-PCIE-40GBx10_TRT | 2926.54 | 2674.86 | 8.986324847 |
DSS8440_A40x10_TRT | 1645.85 | 1390.02 | 16.85381785 |
Table 9: Per card percentage difference from an XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | 99% - Offline (in percentage) | 99% - Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 20.06 | 15.8 |
DSS8440_A100-PCIE-40GBx10_TRT | 20.25 | 17.65 |
DSS8440_A40x10_TRT | 74.17 | 78.67 |
Table 10: Per card numbers and scenario percentage difference on BERT with 99.9 percent accuracy target
Dell Server | 99.9% - Offline throughput | 99.9% Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 1727.44 | 1575.35 | 9.2097893 |
R750xa_A100-PCIE-40GBx4_TRT | 1420.6225 | 1300.365 | 8.8392541 |
DSS8440_A100-PCIE-40GBx10_TRT | 1427.8 | 1211.94 | 16.354641 |
DSS8440_A40x10_TRT | 798.677 | 580.207 | 31.687945 |
Table 11: Per card percentage difference from an XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | 99.9% - Offline (in percentage) | 99.9% - Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 19.49 | 19.12 |
DSS8440_A100-PCIE-40GBx10_TRT | 18.99 | 26.07 |
DSS8440_A40x10_TRT | 73.53 | 92.33 |
RNN-T Results
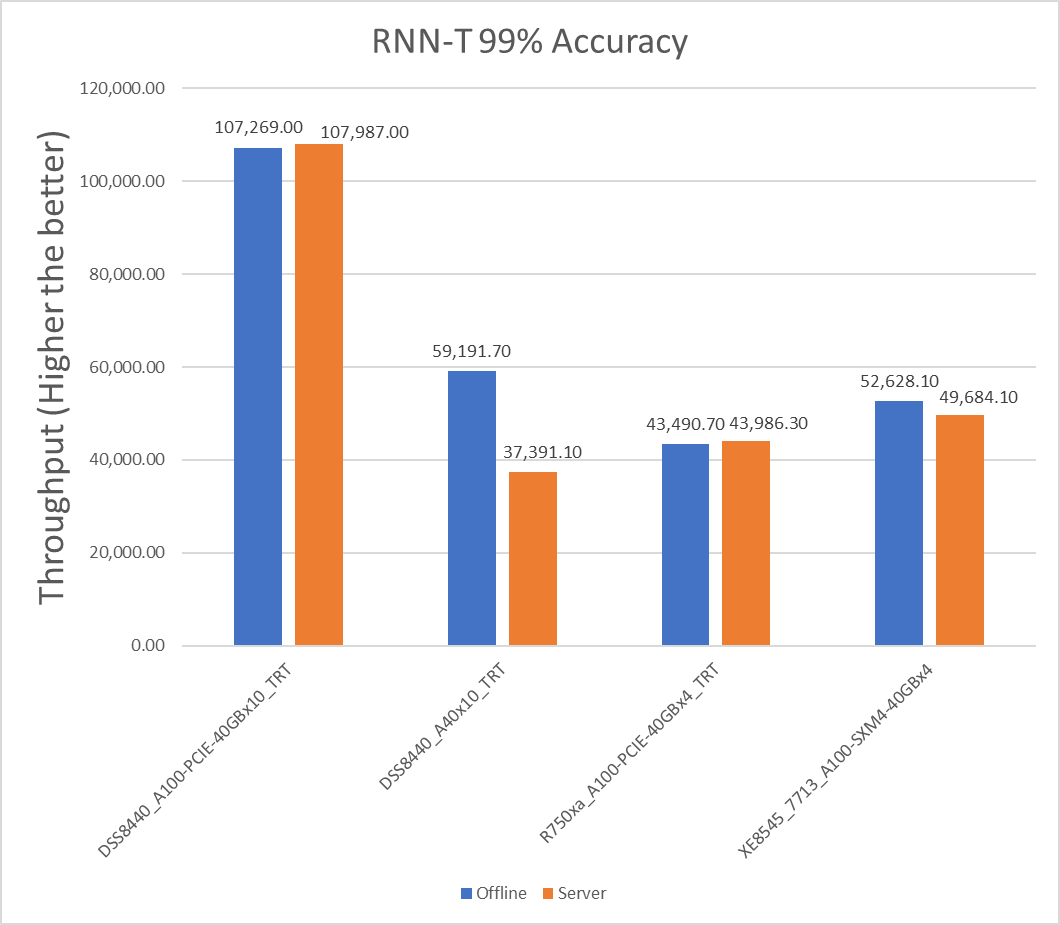
Figure 6: RNN-T Offline and Server scenario with 99 percent accuracy target
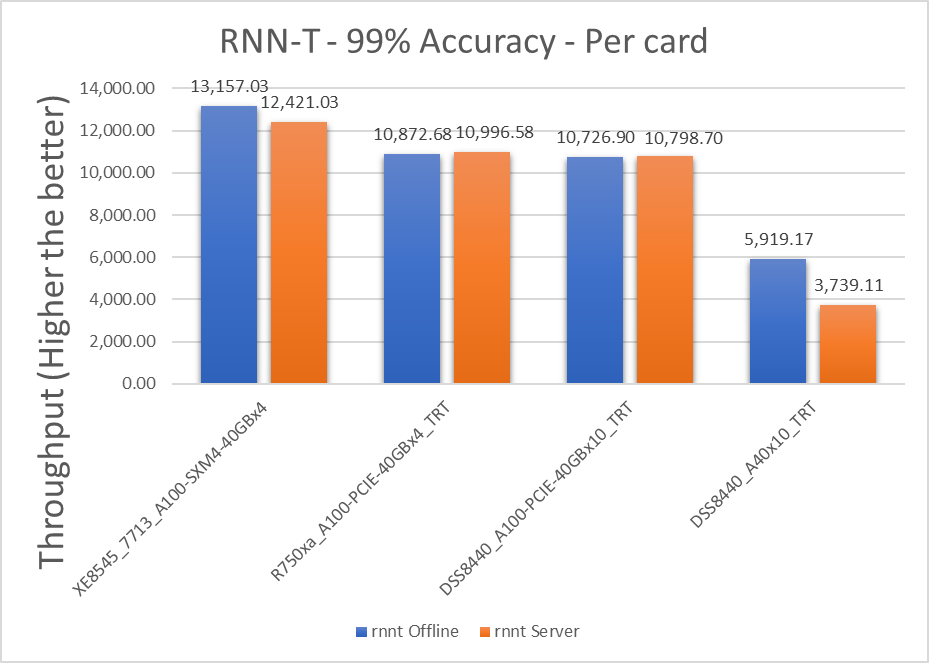
Figure 7: RNN-T Offline and Server scenario with 99 percent accuracy target per card
Table 12: Per card numbers and scenario percentage difference on RNNT with 99 percent accuracy target
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 13157.025 | 12421.025 | 5.754934 |
R750xa_A100-PCIE-40GBx4_TRT | 10872.675 | 10996.575 | -1.1331 |
DSS8440_A100-PCIE-40GBx10_TRT | 10726.9 | 10798.7 | -0.66711 |
DSS8440_A40x10_TRT | 5919.17 | 3739.11 | 45.14386 |
Note: A negative value for the percentage difference indicates that Server scenario performed better than Offline scenario.
Table 13: Per card percentage difference from an XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | Offline (in percentage) | Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 19.01 | 12.16 |
DSS8440_A100-PCIE-40GBx10_TRT | 20.34 | 13.97 |
DSS8440_A40x10_TRT | 75.88 | 107.44 |
3D-UNet Results
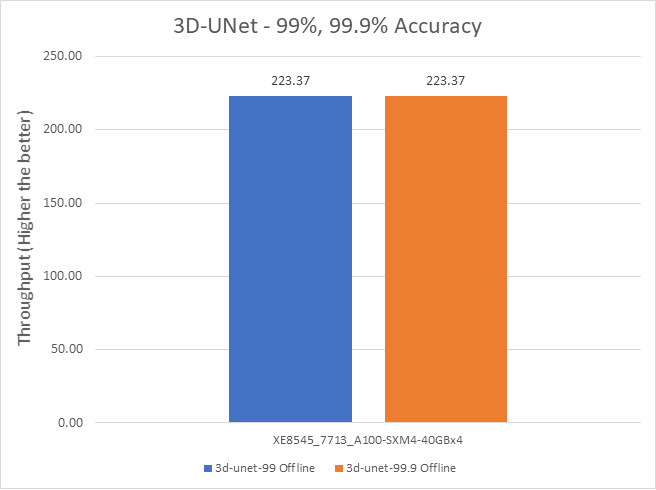
Figure 8: 3D-UNet Offline and Server scenario with 99 percent and 99.9 percent accuracy target
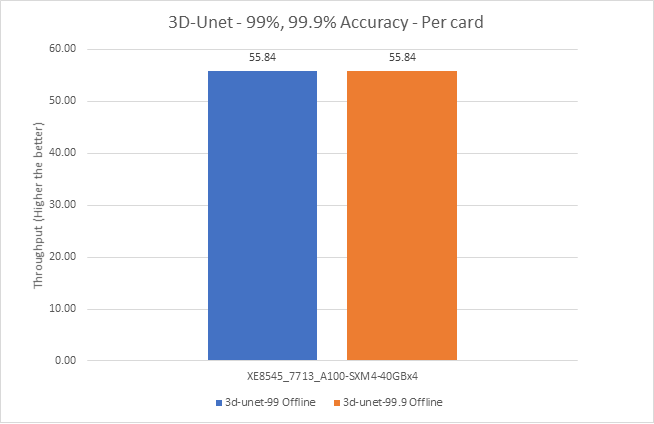
Figure 9: 3D-UNet Offline and Server scenario with 99 percent and 99.9 percent accuracy target
Conclusion
In this blog, we quantified the MLCommons MLPerf inference v1.0 performance on Dell EMC DSS8440, PowerEdge R750xa, and PowerEdge XE8545 servers with A100 PCIE and SXM form factors using benchmarks such as Resnet50, SSD w/ Resnet34, BERT, RNN-T, and 3D-UNet. These benchmarks span tasks from vision to recommendation. Dell EMC servers delivered top inference performance normalized to processor count among commercially available results.
The PowerEdge XE8545 server outperforms the per card numbers of other servers in this study. This result can be attributed to its SXM GPU, which offers higher base and boost clock rate.
The SSD-Resnet34 image segmentation model benefits significantly from an SXM form factor-based GPU. The results show an approximate 34 percent performance difference compared to a PCIE from factor, relative to other models that average approximately 20 percent.
The PowerEdge R750xa server with an A100 GPU performs better in the Server scenario than in the Offline scenario for RNN-T model.
The DSS 8440 server with an A100 GPU performs better in the Server scenario than the Offline scenario for BERT, RNN-T, and SSD-Resnet34 models.
Furthermore, we found that the performance of the DSS8440 server with 10 x A100 PCIE cards exceeded other MLCommons MLPerf inference v1.0 submissions for the RNN-T Server benchmark.
Next Steps
In future blogs, we plan to describe how to:
- Run MLCommons MLPerf inference v1.0
- Understand MLCommons MLPerf inference results on recently released PowerEdge R750xa and PowerEdge XE8545 servers
- Run benchmarks on other servers