




HPC Application Performance on Dell EMC PowerEdge R7525 Servers with the AMD MI100 Accelerator
Wed, 16 Dec 2020 17:34:42 -0000
|Read Time: 0 minutes
Overview
The Dell EMC PowerEdge R7525 server supports the AMD MI100 GPU Accelerator. The server is a two-socket, 2U rack-based server that is designed to run complex workloads using highly scalable memory, I/O capacity, and network options. The system is based on the 2nd Gen AMD EPYC processor (up to 64 cores), has up to 32 DIMMs, and has PCI Express (PCIe) 4.0-enabled expansion slots. The server supports SATA, SAS, and NVMe drives and up to three double-wide 300 W accelerators.
The following figure shows the front view of the server:

Figure 1. Dell EMC PowerEdge R7525 server
The AMD Instinct™ MI100 accelerator is one of the world’s fastest HPC GPUs available in the market. It offers innovations to obtain higher performance for HPC applications with the following key technologies:
- AMD Compute DNA (CDNA)—Architecture optimized for compute-oriented workloads
- AMD ROCm—An Open Software Platform that includes GPU drivers, compilers, profilers, math and communication libraries, and system resource management tools
- Heterogeneous-Computing Interface for Portability (HIP)—An interface that enables developers to covert CUDA code to portable C++ so that the same source code can run on AMD GPUs
This blog focuses on the performance characteristics of a single PowerEdge R7525 server with AMD MI100-32G GPUs. We present results from the general matrix multiplication (GEMM) microbenchmarks, the LAMMPS benchmarks, and the NAMD benchmarks to showcase performance and scalability.
The following table provides the configuration details of the PowerEdge R7525 system under test (SUT):
Table 1. SUT hardware and software configurations
Component | Description |
Processor | AMD EPYC 7502 32-core processor |
Memory | 512 GB (32 GB 3200 MT/s * 16) |
Local disk | 2 x 1.8 TB SSD (No RAID) |
Operating system | Red Hat Enterprise Linux Server 8.2 |
GPU | 3 x AMD MI100-PCIe-32G |
Driver version | 3204 |
ROCm version | 3.9 |
Processor Settings > Logical Processors | Disabled |
System profiles | Performance |
NUMA node per socket | 4 |
NAMD benchmark | Version: NAMD 3.0 ALPHA 6 |
LAMMPS (KOKKOS) benchmark | Version: LAMMPS patch_18Sep2020+AMD patches |
The following table lists the AMD MI100 GPU specifications:
Table 2. AMD MI100 PCIe GPU specification
Component | |
GPU architecture | MI100 |
Peak Engine Clock (MHz) | 1502 |
Stream processors | 7680 |
Peak FP64 (TFLOPS) | 11.5 |
Peak FP64 Tensor DGEMM (TFLOPS) | 11.5 |
Peak FP32 (TFLOPS) | 23.1 |
Peak FP32 Tensor SGEMM (TFLOPS) | 46.1 |
Memory size (GB) | 32 |
Memory ECC support | Yes |
TDP (Watt) | 300 |
GEMM Microbenchmarks
The GEMM benchmark is a simple, multithreaded dense matrix-to-matrix multiplication benchmark that can be used to test the performance of GEMM on a single GPU. The rocblas-bench binary compiled from https://github.com/ROCmSoftwarePlatform/rocBLAS was used to collect DGEMM and SGEMM results. The results of these tests reflect the performance of an ideal application that only runs matrix multiplication in the form of the peak TFLOPS that the GPU can deliver. Although GEMM benchmark results might not represent real-world application performance, it is still a good benchmark to demonstrate the performance capability of different GPUs.
The following figure shows the observed numbers of DGEMM and SGEMM:
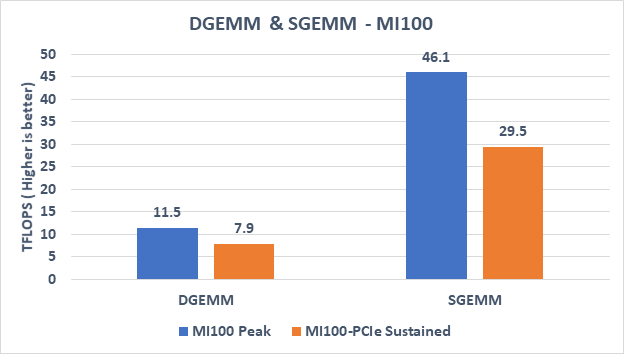
Figure 2. DGEMM and SGEMM for both AMD MI100 peak and AMD-PCIe sustained
The results indicate:
- In the DGEMM (double-precision GEMM) benchmark, the theoretical peak performance of the AMD MI100 GPU is 11.5 TFLOPS and the measured sustained performance is 7.9 TFLOPS. As shown in Table 2, the standard double precision (FP64) theoretical peak and the FP64 tensor DGEMM peak performance are both at 11.5 TFLOPS. Because most real world HPC applications typically are not heavily implemented with DGEMM or other matrix operations, this high standard FP64 capability boosts the performance on other non-matrix double-precision math calculations.
- For FP32 Tensor operations in the SGEMM (single-precision GEMM) benchmark, the theoretical peak performance of the AMD MI100 GPU is 46.1 TFLOPS, and the measured sustained performance is approximately 30 TFLOPS.
The LAMMPS benchmark
The Large-Scale Atom/Molecular Massively Parallel Simulator (LAMMPS) runs threads in parallel using message-passing techniques. This benchmark measures the scalability and performance of large, parallel systems of multiple GPUs.
The following figure shows the KOKKOS implementation of LAMMPS scaled relatively linearly as AMD MI100 GPUs were added across four datasets: EAM, LJ, Tersoff, and ReaxFF/C.
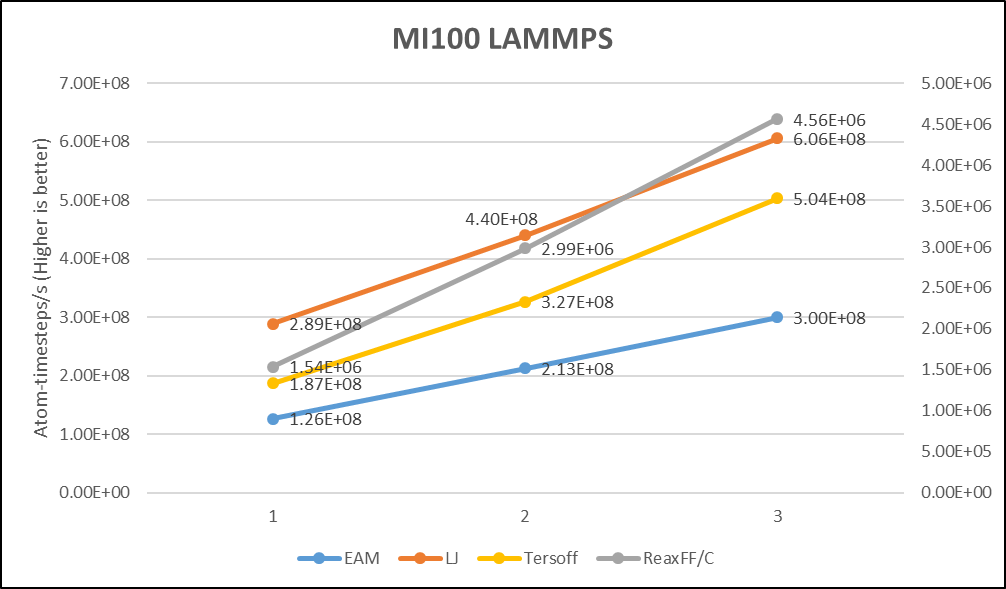
Figure 3. LAMMPS benchmark showing scaling of multiple AMD MI100 GPUs
The NAMD Benchmark
Nanoscale Molecular Dynamics (NAMD) is a parallel molecular dynamics system designed for simulation of large biomolecular systems. The NAMD benchmark stresses the scaling and performance aspects of the server and GPU configuration.
The following figure plots the results of the NAMD microbenchmark:
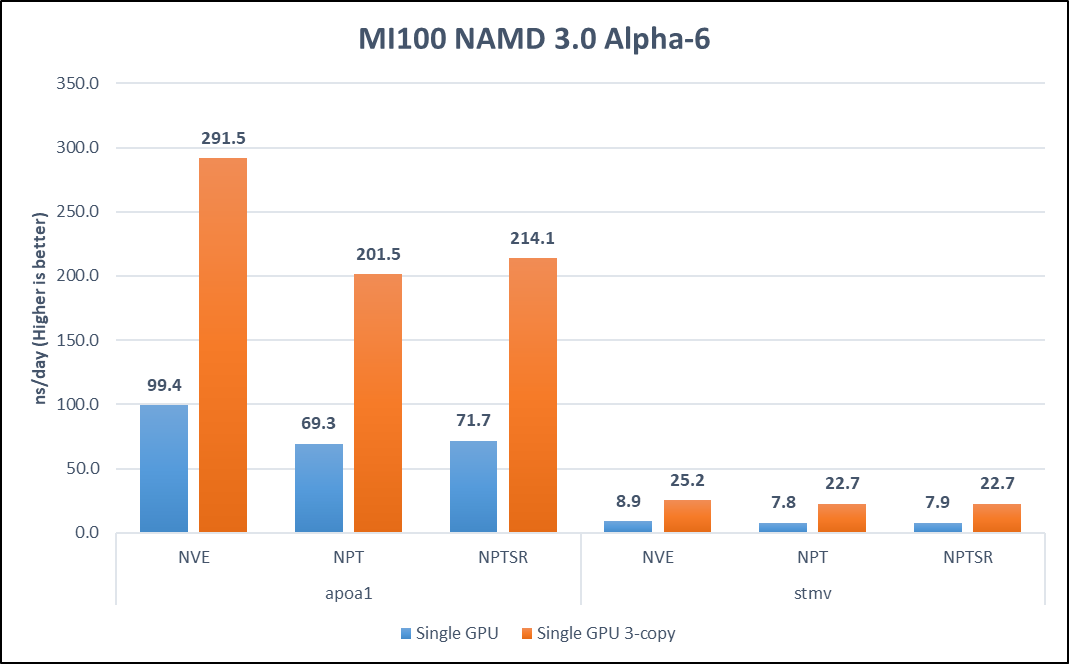
Figure 4. NAMD benchmark performance
Aggregate data of multiple GPU cards is preferred because the Alpha builds of the NAMD 3.0 binary do not scale beyond a single accelerator. Three replica simulations were launched on the same server, one on each GPU, in parallel. NAMD was CPU-bound in previous versions. The new 3.0 version has reduced the CPU dependence. As a result, three-copy simulation produced linear scaling performing three times faster across all datasets.
As part of the optimization, the NAMD benchmark numbers in the following figure show the relative performance difference using different numbers of CPU cores for the STMV dataset:
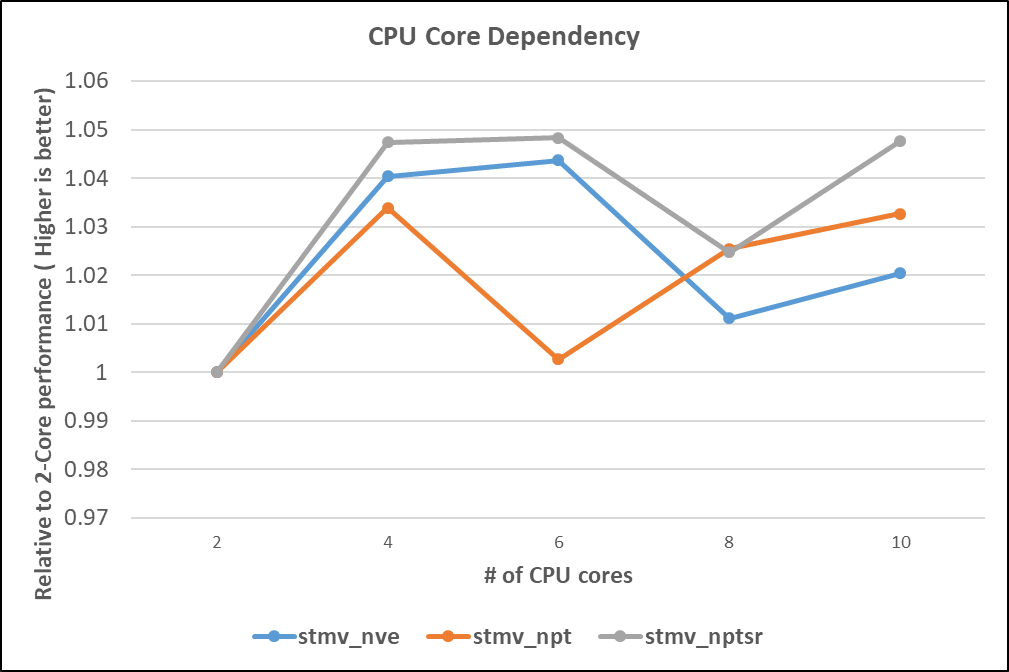
Figure 5. CPU core dependency on NAMD
The AMD MI100 GPU exhibited an optimum configuration of four CPU cores per GPU.
Conclusion
The AMD MI100 accelerator delivers industry-leading performance, and it is a well-positioned performance per dollar GPU for both FP32 and FP64 HPC parallel codes.
- FP32 applications perform well using the AMD MI100 GPU based on the SGEMM, LAMMPS, and NAMD benchmarks performance by using tensor cores and native FP32 compute cores.
- FP64 applications perform well using the AMD MI100 GPU by using native FP64 compute cores.
Next Steps
In the future, we plan to test other HPC and Deep Learning applications. We also plan to research using “Hipify” tools to port CUDA sources to HIP.