



Dell Technologies’ NVIDIA H100 SXM GPU submission to MLPerf™ Inference 3.0
Tue, 23 May 2023 17:10:45 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to MLPerf Inference v3.0 in the closed division. This blog highlights Dell Technologies’ closed division submission made with the NVIDIA H100 Tensor Core GPU using the SXM-based HGX system.
Introduction
MLPerf Inference v3.0 submission falls under the benchmarking pillar of the MLCommonsTM consortium with the objective to make fair comparisons across server configurations. Submissions that are made to the closed division warrant an equitable comparison of the systems.
This blog highlights the closed division submissions that Dell Technologies made with the NVIDIA H100 GPU using an HGX 100 system. The HGX system uses a high-bandwidth socket solution designed to work in parallel with NVIDIA NVSwitch interconnect technology.
Aside from NVIDIA, Dell Technologies was the only company to publish results for the NVIDIA H100 SXM GPU card. The NVIDIA H100 GPU results shine in this MLPerf Inference round. This GPU has between 300 percent to 800 percent increases in performance compared to the NVIDIA A100 Tensor Core GPUs. It achieved top results when considering performance per system and performance per GPU.
Submissions made with the NVIDIA H100 GPU
In this round, Dell Technologies used the Dell PowerEdge XE9680 and Dell PowerEdge XE8545 servers to make submissions for the NVIDIA H100 SXM card. Because the PowerEdge XE9680 server is an eight-way GPU server, it allows customers to experience outstanding acceleration for artificial intelligence (AI), machine learning (ML), and deep learning (DL) training and inference.
Platform | PowerEdge XE9680 (8x H100-SXM-80GB, TensorRT) | PowerEdge XE8545 (4x A100-SXM-80GB, TensorRT) | PowerEdge XE9680 (8x A100-SXM-80GB, TensorRT) |
MLPerf System ID | XE9680_H100_SXM_80GBx8_TRT | XE8545_A100_SXM4_80GBx4_TRT | XE9680_A100_SXM4_80GBx8_TRT |
Operating system | Ubuntu 22.04 | ||
CPU | Intel Xeon Platinum 8470 | AMD EPYC 7763 | Intel Xeon Platinum 8470 |
Memory | 2 TB | 4 TB | |
GPU | NVIDIA H100-SXM-80GB | NVIDIA A100-SXM-80GB CTS | NVIDIA A100-SXM-80GB CTS |
GPU form factor | SXM | ||
GPU memory configuration | HBM3 | HBM2e | |
GPU count | 8 | 4 | 8 |
Software stack | TensorRT 8.6.0 CUDA 12.0 cuDNN 8.8.0 Driver 525.85.12 DALI 1.17.0 | ||
Table 1: Software stack of submissions made on NVIDIA H100 and NVIDIA A100 SXM GPUs in MLPerf Inference v3.0
PowerEdge XE9680 Rack Server
With the PowerEdge XE9680 server, customers can take on demanding artificial intelligence, machine learning, and deep learning workloads, including generative AI. This high-performance application server enables rapid development, training, and deployment of large machine learning models. The PowerEdge XE9680 server was made for artificial intelligence, machine learning, deep learning, and other demanding workloads. The PowerEdge XE9680 server is loaded with features for any possible artificial intelligence, machine learning, and deep learning workload as it supports eight NVIDIA HGX H100 80GB 700W SXM5 GPUs or eight NVIDIA HGX A100 80GB 500W SXM4 GPUs, fully interconnected with NVIDIA NVLink technology. For more details, see the specification sheet for the PowerEdge XE9680 server.

Figure 2: Front side view of the PowerEdge XE9680 Rack Server

Figure 3: Front view of the PowerEdge XE9680 Rack Server

Figure 4: Rear side view of the PowerEdge XE9680 Rack Server

Figure 5: Rear view of the PowerEdge XE9680 Rack Server

Figure 6: Top view of the PowerEdge XE9680 Rack Server
Comparison of the NVIDIA H100 SXM GPU with the NVIDIA A100 SXM GPU
Looking at the best entire system results for this round of submission (v3.0) and the previous round of submission (v2.1), the performance gains achieved by the PowerEdge XE9680 server with eight NVIDIA H100 GPUs are outstanding. In comparison, the NVIDIA H100 GPU server outperforms its predecessor, the NVIDIA A100 GPU server, by a large margin in all the tested workloads, as shown in the following figure. Note that the best results in the previous round of submission were generated by the PowerEdge XE8545 server with four NVIDIA A100 GPUs.
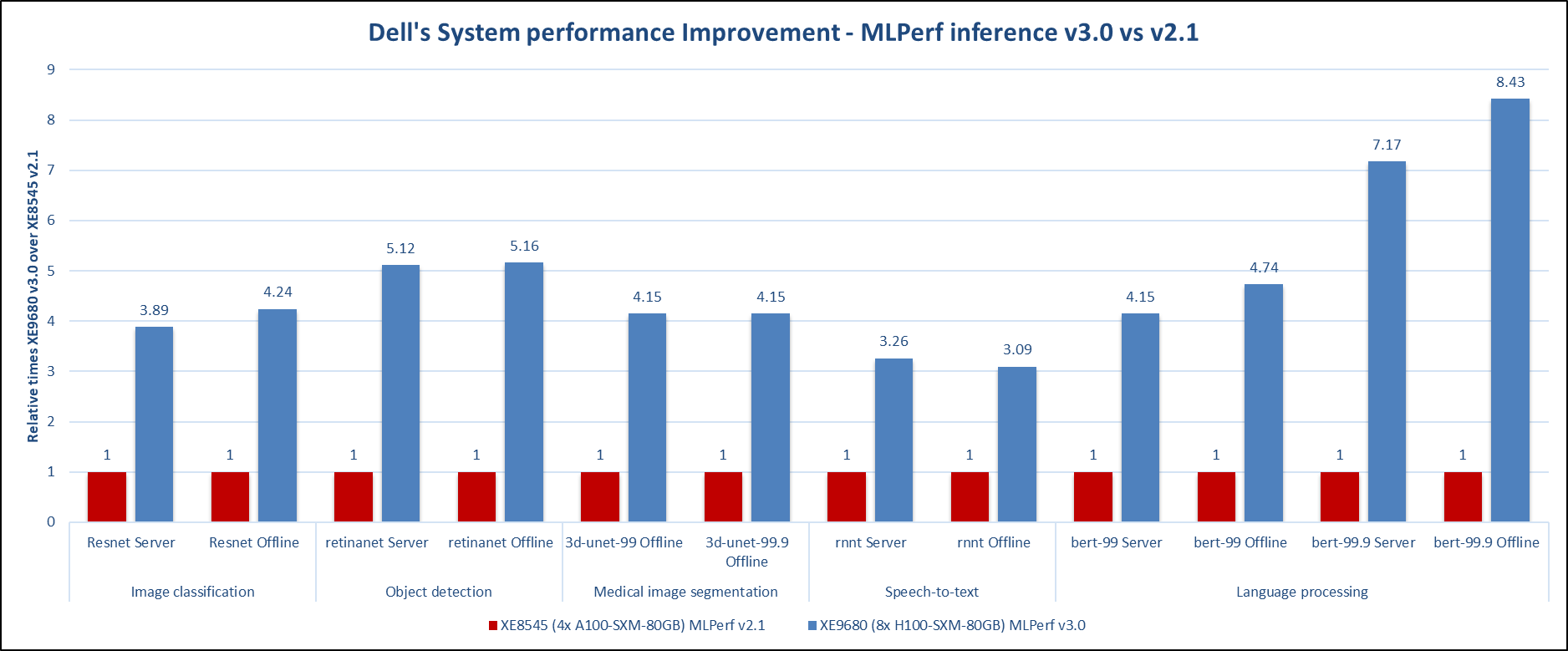
*MLPerf ID 2.1-004 and MLPerf ID 3.0.-0013
Figure 7: Dell’s system performance improvement – MLPerf Inference v3.0 compared to MLPerf Inference v2.1
In the Computer Vision domain for image classification and object detection, the submission for this round showed a four- and five-times performance improvement across the two rounds of submissions respectively. For the medical image segmentation task, the 3D-Unet benchmark, the PowerEdge XE9680 server with NVIDIA H100 GPUs produced up to four times the performance gains. For the RNNT benchmark, which is in the speech-to-text domain, the PowerEdge XE9680 submission for v3.0 showed a three-times performance improvement when compared to the PowerEdge XE8545 submission for v2.1. In the natural language processing benchmark, BERT, we observed impressive gains in both default and high accuracy modes. For the default mode, a four-times performance boost can be seen, and an eight-times performance boost can be claimed for the high accuracy mode. With the recent popularity rise in Large Language Models (LLMs), these results make for an exciting submission.
Conclusion
The NVIDIA H100 GPU is a game changer with its eye-catching performance increases when compared to the NVIDIA A100 GPU. The PowerEdge XE9680 server performed exceptionally well for this round in all machine learning tasks ranging from image classification, object detection, medical image segmentation, speech to text, and language processing. Aside from NVIDIA, Dell Technologies was the only MLPerf submitter for NVIDIA H100 SXM GPU results. Given the high-quality submissions made by Dell Technologies for this round with the PowerEdge XE9680 server, the future in the deep learning space is exciting, especially when we realize the impact this server with NVIDIA H100 GPUs may have for generative AI workloads.