



Dell Servers Excel in MLPerf™ Inference 3.0 Performance
Fri, 07 Apr 2023 10:42:23 -0000
|Read Time: 0 minutes
MLCommons has released the latest version (version 3.0) of MLPerf Inference results. Dell Technologies has been an MLCommons member and has been making submissions since the inception of the MLPerf Inference benchmark. Our latest results exhibit stellar performance from our servers and continue to shine in all areas of the benchmark including image classification, object detection, natural language processing, speech recognition, recommender system, and medical image segmentation. We encourage you to see our previous whitepaper about Inference v2.1, which introduces the MLCommons inference benchmark. AI and the most recent awareness of Generative AI, with application examples such as ChatGPT, have led to an increase in understanding about the performance objectives needed to enable customers with faster time-to-model and results. The latest results reflect the continued innovation that Dell Technologies brings to help customers achieve those performance objectives and speed up their initiatives to assess and support workloads including Generative AI in their enterprise.
What’s new with Inference 3.0?
New features for Inference 3.0 include:
- The inference benchmark rules did not make any significant changes. However, our submission has been expanded with the new generation of Dell PowerEdge servers:
- Our submission includes the new PowerEdge XE9680, XR7620, and XR5610 servers.
- Our results address new accelerators from our partners such as NVIDIA and Qualcomm.
- We submitted virtualized results with VMware running on NVIDIA AI Enterprise software and NVIDIA accelerators.
- Besides accelerator-based numbers, we submitted Intel-based CPU-only results.
Overview of results
Dell Technologies submitted 255 results across 27 different systems. The most outstanding results were generated from PowerEdge R750xa and XE9680 servers with the new H100 PCIe and SXM accelerators, respectively, as well as PowerEdge XR5610 and XR7620 servers with the L4 cards. Our overall NVIDIA-based results include the following accelerators:
- (New) Eight-way NVIDIA H100 Tensor Core GPU (SXM)
- (New) Four-way NVIDIA H100 Tensor Core GPU (PCIe)
- (New) Eight-way NVIDIA A100 Tensor Core GPU (SXM)
- Four-way NVIDIA A100 Tensor Core GPU (PCIe)
- NVIDIA A30 Tensor Core GPU
- (New) NVIDIA L4 Tensor Core GPU
- NVIDIA A2 GPU
- NVIDIA T4 GPU
We ran these accelerators on different PowerEdge XE9680, R750xa, R7525, XE8545, XR7620, XR5610 and other server configurations.
This variety of results across different servers, accelerators, and deep learning use cases allows customers to use them as datapoints to make purchasing decisions and set performance expectations.
Interesting Dell datapoints
The most interesting datapoints include:
- Among 21 submitters, Dell Technologies was one of the few companies that submitted results for all closed scenarios including data center, data center power, Edge, and Edge power.
- The PowerEdge XE9680 server procures the highest performance titles with RetinaNet Server and Offline, RNN-T Server, and BERT 99 Server benchmarks. It procures number 2 performance with Resnet Server and Offline, 3D-UNet Offline and 3D-UNet Offline 99.9, BERT 99 Offline, BERT 99.9 Server, and RNN-T Offline benchmarks.
- The PowerEdge XR5610 server procured highest system performance per watt with the NVIDIA L4 accelerator on the ResNet Single Stream, Resnet Multi Stream, RetinaNet Single Stream, RetinaNet Offline, RetinaNet Multi Stream, 3D-UNet 99, 3D-UNet 99.9 Offline, RNN-T Offline, Single Stream, BERT 99 Offline, BERT-99 Single Stream benchmarks.
- Our results included not only various systems, but also exceeded performance gains compared to the last round because of the newer generation of hardware acceleration from the newer server and accelerator.
- The Bert 99.9 benchmark was implemented with FP8 the first time. Because of the accuracy requirement, in the past, the Bert 99.9 benchmark was implemented with FP16 while all other models ran under INT8.
In the following figure, the BERT 99.9 v3.0 Offline scenario renders 843 percent more improvement compared to Inference v2.1. This result is due to the new PowerEdge XE9680 server, which is an eight–way NVIDIA H100 SXM system, compared to the previous PowerEdge XE8545 four-way NVIDIA A100 SXM. Also, the NVIDIA H100 GPU features a Transformer Engine with FP8 precision that speeds up results dramatically.
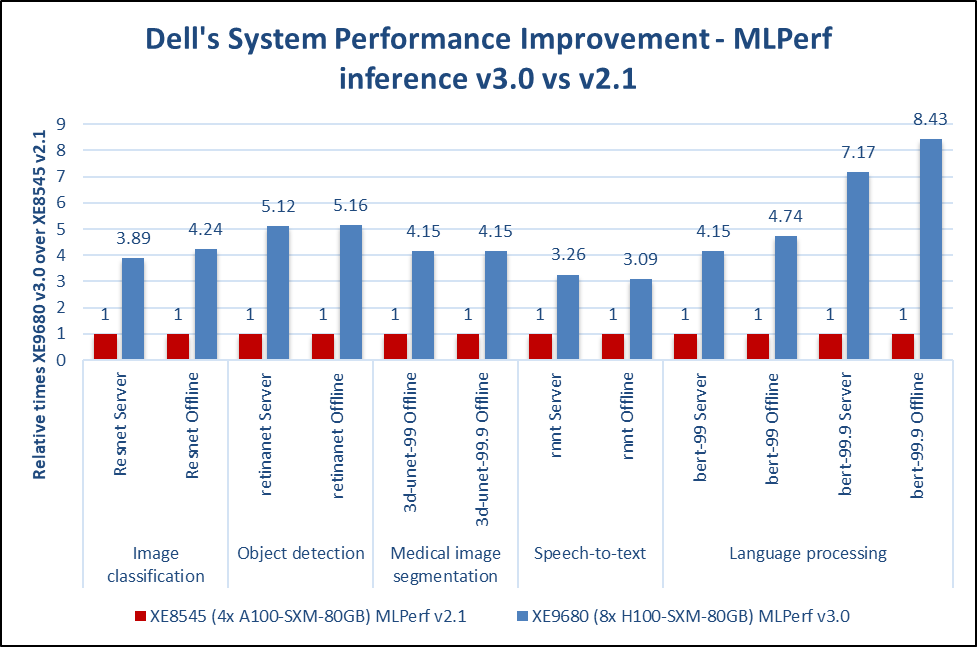
* MLPerf ID 2.1-0014 and MLPerf ID 3.0-0013
Figure 1: Performance gains from Inference v2.1 to Inference v3.0 due to the new system
Results at a glance
The following figure shows the system performance for Offline and Server scenarios. These results provide an overview as upcoming blogs will provide details about these results. High accuracy versions of the benchmark are included for DLRM and 3D-UNet as high accuracy version results are identical to the default version. For the BERT benchmark, both default and high accuracy versions are included as they are different.
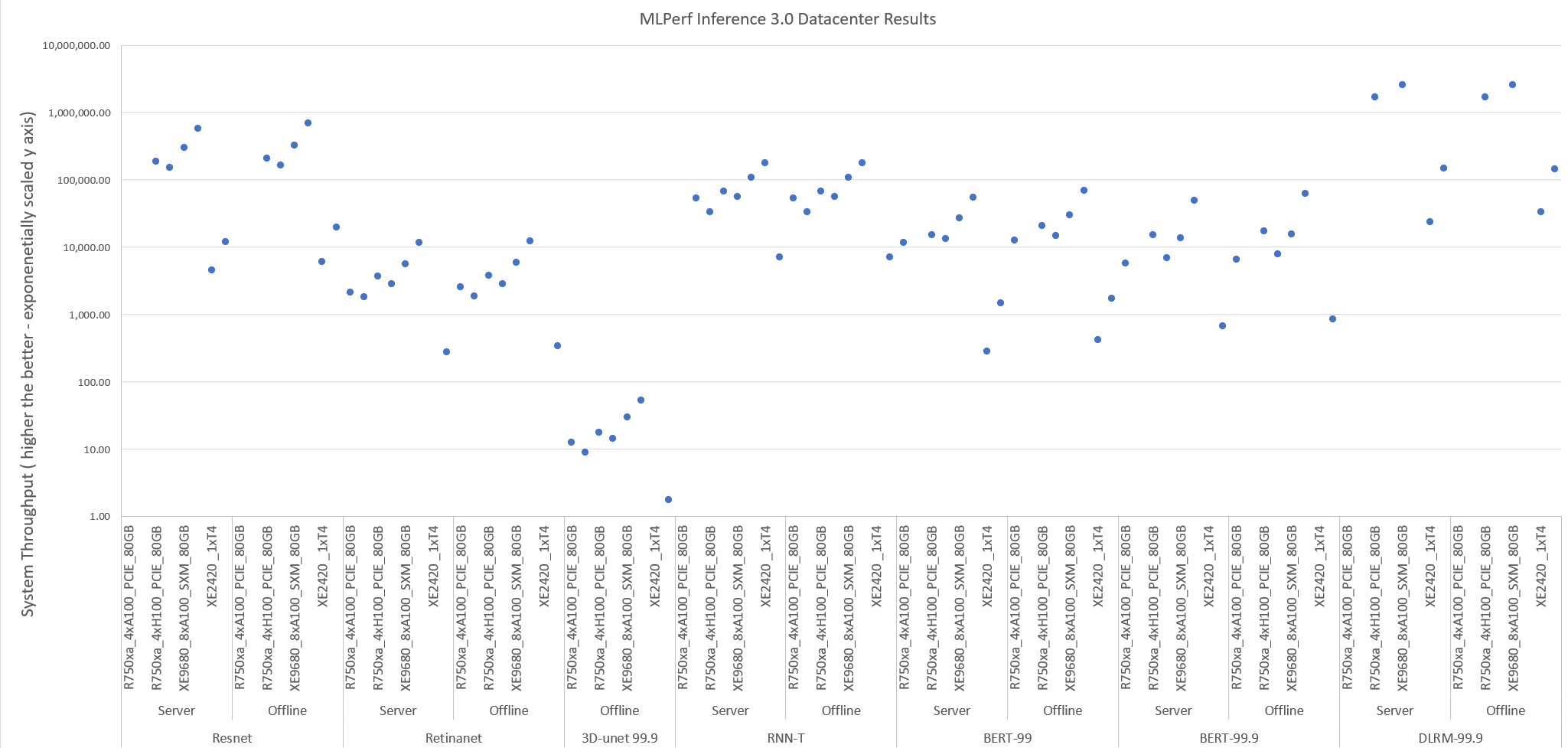
Figure 2: System throughput for data center suite-submitted systems
The following figure shows the Single Stream and Multi Stream scenario latency for the ResNet, RetinaNet, 3D-UNet, RNN-T, and BERT-99 benchmarks. The lower the latency, the better the results.
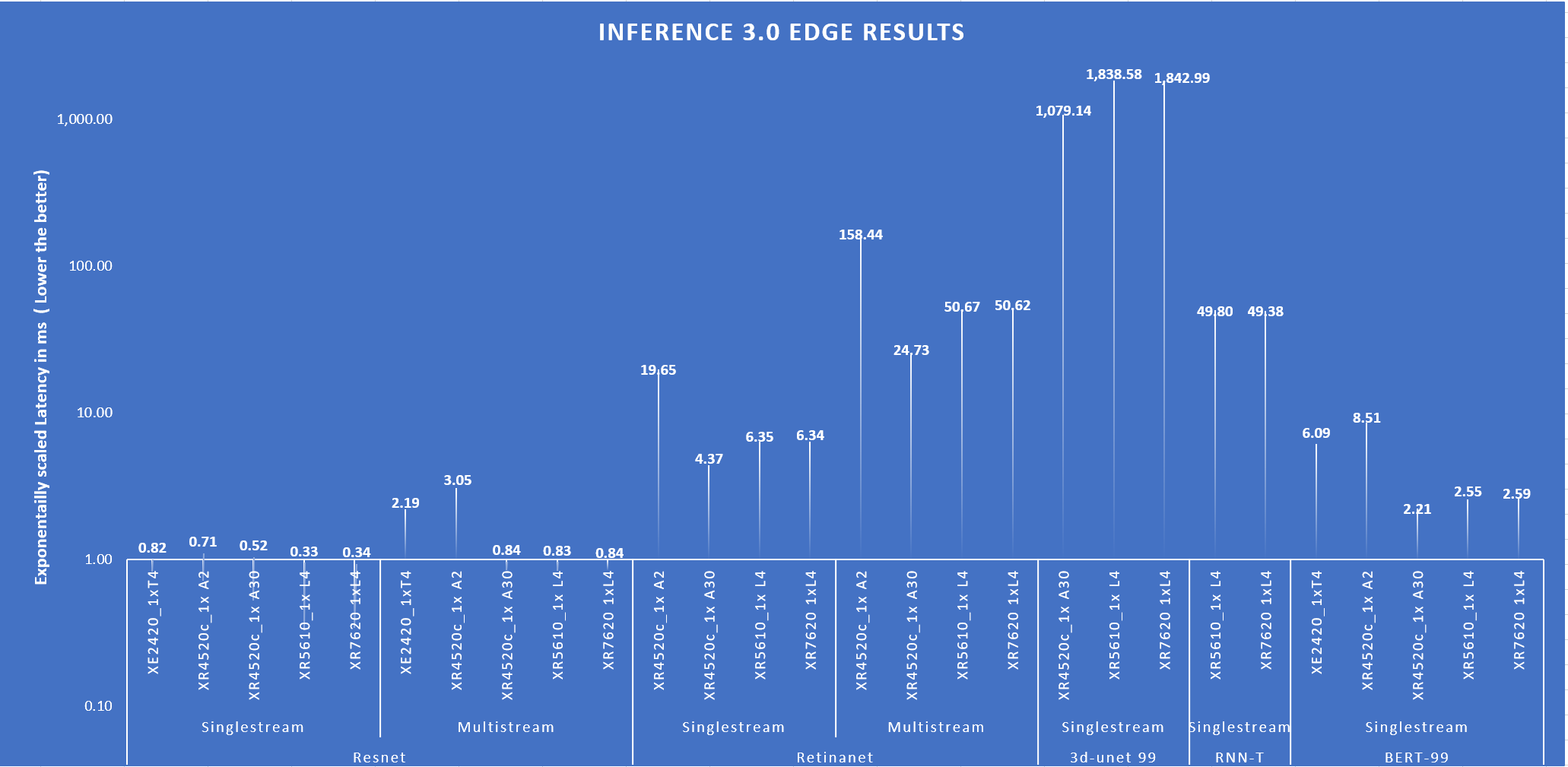
Fig 3: Latency of the systems for different benchmark
Edge benchmark results include Single Stream, Multi Stream, and Offline scenarios. The following figure shows the offline scenario performance.
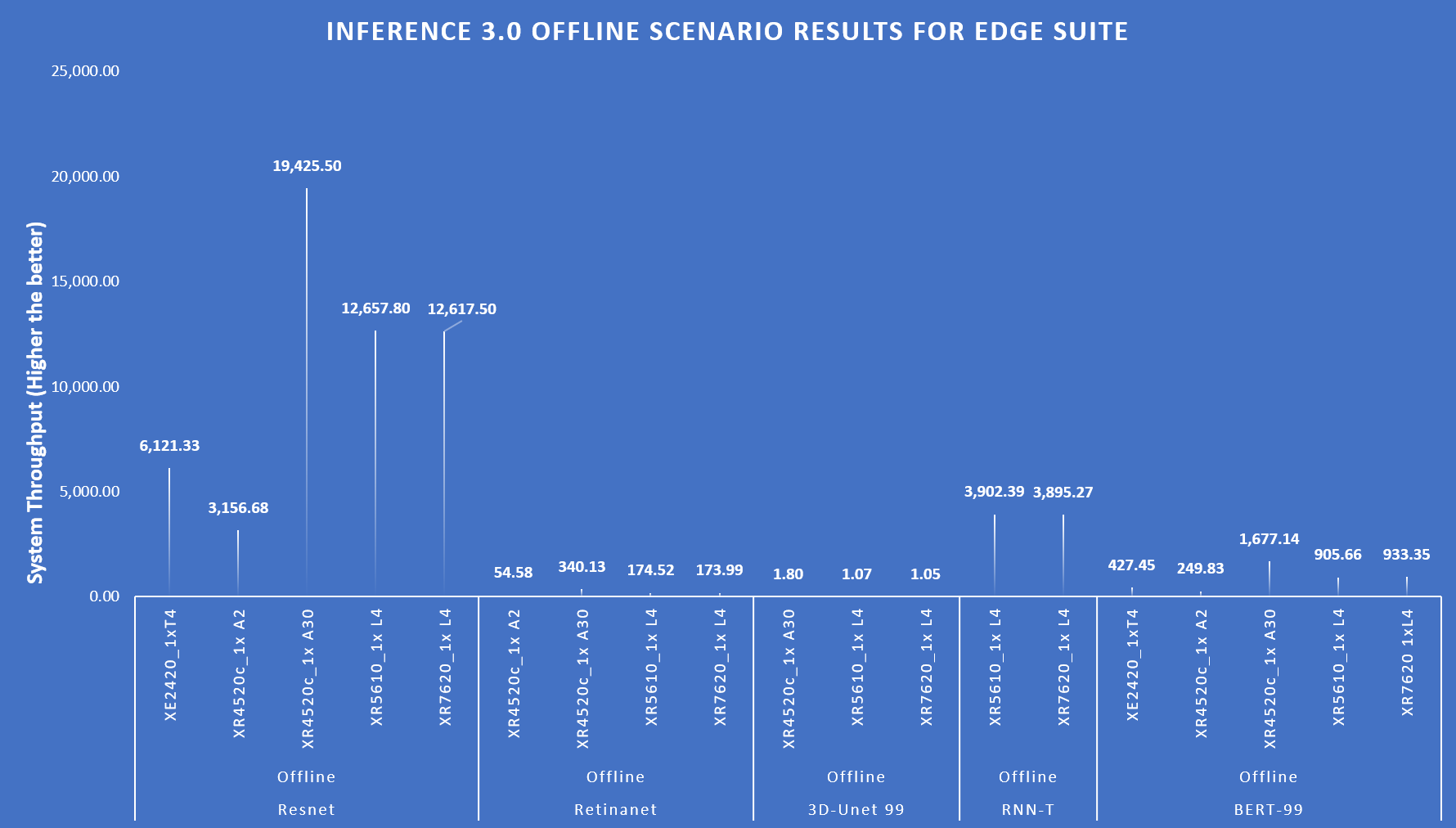
Figure 4: Offline Scenario system throughput for Edge suite
The preceding figures show that PowerEdge servers delivered excellent performance across various benchmarks and scenarios.
Conclusion
We have provided MLCommons-compliant submissions to the Inference 3.0 benchmark across various benchmarks and suites. These results indicate that with the newer generations of servers, such as the PowerEdge XE9680 server, and newer accelerators, such as the NVIDIA H100 GPU, customers can derive higher performance from their data center and edge deployments. Upgrading to newer hardware can yield between 304 and 843 percent improvement across all the benchmarks such as image classification, object detection, natural language processing, speech recognition, recommender systems, and medical image segmentation involved in the MLPerf inference benchmark. From our submissions for new servers such as the PowerEdge XR5610 and XR7620 servers with the NVIDIA L4 GPU, we see exceptional results. These results show that the new PowerEdge servers are an excellent edge platform choice. Furthermore, our variety of submissions to the benchmark can serve as a baseline to enable different performance expectations and cater to purchasing decisions. With these results, Dell Technologies can help fuel enterprises’ AI transformation, including Generative AI adoption, and deployment precisely and efficiently.