



Dell EMC PowerEdge R750xa Server for Inference on AI Applications
Wed, 01 Dec 2021 13:24:57 -0000
|Read Time: 0 minutes
Introduction to the PowerEdge R750xa server for inference on AI applications
Dell Technologies HPC & AI Innovation Lab has submitted results for the Dell EMC PowerEdge R750xa server to MLPerf™ Inference v1.1, the latest round from MLCommons™, for data center on-premises benchmarks. Based on these results submitted for data center on-premises inference, the PowerEdge R750xa server performs well across many application areas and consistently provides high-performance results for machine-learning inference benchmarks. In this blog, we showcase the PowerEdge R750xa server results as a benchmark for high performance.
The results show that the PowerEdge R750xa server is flexible and can support challenges across many AI applications. Also, the results are reproducible for inference performance in problem areas that are addressed by vision, speech, language, and commerce applications.
PowerEdge R750xa server technical specifications
The PowerEdge R750xa server base configuration provides enterprise solutions for customers in the field of artificial intelligence. It is a 2U, dual-socket server with dual 3rd Gen Intel Xeon Scalable processors with 40 cores and 32 DDR4 RDIMM slots for up to 1 TB of memory at powerful data rates.
With state-of-the-art hardware, the PowerEdge R750xa server is well suited for heavy workloads. It is especially well suited for artificial intelligence, machine learning, and deep learning applications and their heavy computational requirements. Also, the PowerEdge R750xa server is designed for flexibility, capable of adding more processors and PCIe cards, and adequate HDD or SSD/NVMe storage capacity to scale to meet workload needs. With scalability at its foundation, the server can be expanded to manage visualization, streaming, and other types of workloads to address AI processing requirements.
The following figures show the PowerEdge R750xa server:

Figure. 1: Front view of the PowerEdge R750xa server

Figure. 2: Rear view of the PowerEdge R750xa server

Figure. 3: Top view of the PowerEdge R750xa server without the cover
Overview of MLPerf Inference
The MLPerf Inference benchmark is an industry-standard benchmark suite that accepts submission of inference results for a system under test (SUT) to various divisions. Each division is governed by policies that define the conditions for generating the results and the acceptable configurations for the SUTs. This blog provides details about the divisions and policies governing MLPerf Inference Benchmarking. For more information, see the MLCommons Inference Benchmarking website.
The focus of the PowerEdge R750xa server for inference was on the Closed Division Datacenter suite. There are six tasks spanning four areas for which benchmarking results were submitted. Within each task, the closed division defines a set of constraints that the inference benchmark must follow.
Systems submitting inference benchmark results in each of these tasks are required to meet each of the constraints shown in the following table:
Table 1: Benchmark tasks for MLPerf v1.1 Inference
Area | Task | Model | QSL size | Quality | Server latency constraint |
Vision | Image classification | Resnet50-v1.5 | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection (large) | SSD-ResNet34 | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical image segmentation | 3D UNet | 16 | 99% of FP32 and 99.9% of FP32 (0.85300 mean DICE score) | N/A |
Speech | Speech-to-text | RNNT | 2513 | 99% of FP32 (1 - WER, where WER=7.452253714852645%) | 1000 ms |
Language | Language processing | BERT | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Commerce | Recommendation | DLRM | 204800 | 99% of FP32 and 99.9% of FP32 (AUC=80.25%) | 30 ms |
PowerEdge R750xa server performance for inference
We submitted PowerEdge R750xa server benchmarking results for each task listed in the preceding table. For each task, we provided two submissions. The first submission was for the system operating in the Offline scenario, in which the SUT receives all samples in a single query and processes them continuously until completed. In this mode, system latency is not a primary issue. The second submission addressed the system operating in a server scenario, in which the model and data are processed through a network connection and depend on the latency of the SUT.
The PowerEdge R750xa server generated results for each task, in both modes, across three different configurations. The following table lists the three configurations:
Table 2: PowerEdge R750xa server configurations submitted for benchmarking
Configuration | 1 | 2 | 3 |
System | PowerEdge R750xa server | ||
Accelerator | 4x A100-PCIe (80 GB) | ||
CPU | Intel Xeon Gold 6338 | ||
Software stack | CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 | CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 Triton 21.07 | CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 Triton 21.07 Multi-Instance GPU (MIG) |
The table shows that all three configurations are similar, using a 4 x A100-PCIe (80 GB) GPU and the Intel Xeon Gold 6338 CPU. The primary difference is in the software stack. All three configurations use TensorRT. Configuration 2 adds a layer by using the NVIDIA Triton Inference Server as the inference engine. Configuration 3 adds two layers by using the NVIDIA Triton Inference Server and the NVIDIA Multi-Instance GPU (MIG).
The following figures show the results of each of these systems for the Offline and Server scenarios.
The following figure shows the first inference benchmark for image classification inferences with the PowerEdge R750xa server:
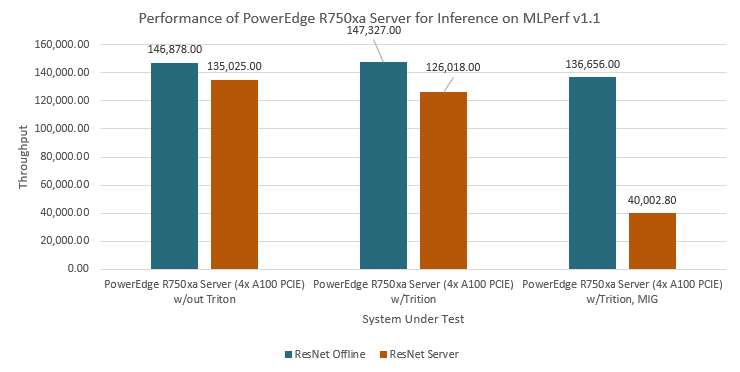
Figure. 1: PowerEdge R750xa server performance on inference for image classification using ResNet
Three different configurations of the PowerEdge R750xa server were benchmarked. Each configuration used ResNet-50 as the base model and we observed performance in both the Offline and Server scenarios. The first configuration with the Triton Inference Server performed slightly faster in the Offline scenario with 147,327 samples per second compared to the other two configurations. The configuration without the Triton Inference Server ran 146,878 samples per second while the configuration with the Triton Inference Server and MIG ran 136,656 samples per second. In the Offline scenario, these results suggest that the Triton Inference Server performs slightly faster, handling batches of samples quicker without regard to latency. These results give the first configuration a performance edge in the Offline scenario. In the Server scenario, the configuration without the Triton Inference Server performed the fastest at 135,025 samples per second. The configuration with the Triton Inference Server ran 126,018 samples per second, while the configuration with the Triton Inference Server and MIG ran 40,003 samples per second. These results show that the configurations including MIG all performed comparably, ranking highly for 4 x A100-PCIe (80 GB) GPU configurations on the image classification task. The results demonstrate that the PowerEdge R750xa server is a high-performance computing platform for image classification, especially when high-performance acceleration is installed on the system.
The following figure shows the second inference benchmark for Natural Language Processing (NLP) inferences with the PowerEdge R750xa server:
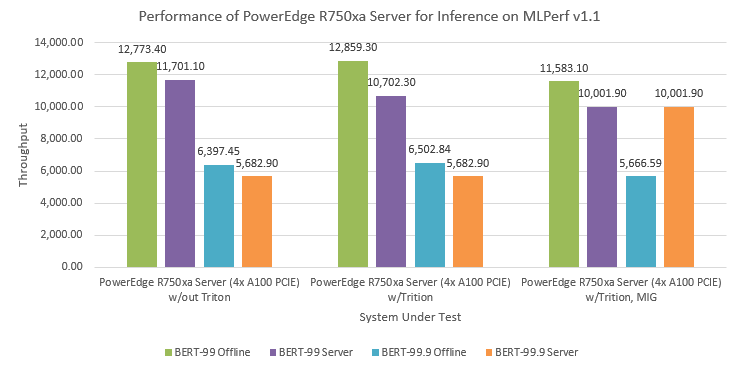
Figure. 2: PowerEdge R750xa server performance on inference for language processing using BERT
The same three configurations of the PowerEdge R750xa server were benchmarked. Each configuration used two versions of BERT as the base model and we observed performance in both the Offline and Server scenarios. The first version of the BERT model (BERT-99) is based on a 99 percent accuracy of inference; the second version (BERT-99.9) is based on a 99.9 percent accuracy of inference. In both cases, the PowerEdge R750xa server ran approximately 50 percent more samples per second with the BERT-99 model compared to the BERT-99.9 model. This result is because using the Bert-99.9 model to achieve 99.9 percent accuracy is based on 16-bit floating point data whereas the BERT-99 model is based on 8-bit integer data. The former requires significantly more computations due to the larger number of bits per sample.
As with the first inference benchmark, the configuration with the Triton Inference Server performed slightly faster in the Offline scenario with 12,859 samples per second compared to the other configurations using the BERT-99 model. It follows that the Triton Inference Server is configured to perform slightly better in the Offline scenario. In the Server scenario, the configuration without the Triton Inference Server performed best at 11,701 samples per second. For the BERT-99.9 model, the configuration without the Triton Inference Server ran 6,397 samples per second in the Offline scenario. Both configurations without MIG performed identically at 5,683 samples per second in the Server scenario for the BERT-99.9 model. This marginal difference can be attributed to run-to-run variability. Therefore, both configurations performed nearly identically.
These results show that all configurations performed comparably with or without the Triton Inference Server. For NLP, all configurations ranked highly for 4 x PCIe GPU configurations. The results suggest that the PowerEdge R750xa server is well suited for handling natural language processing samples in an inference configuration.
The following figure shows the third inference benchmark for light-weight object detection in images with the PowerEdge R750xa server:
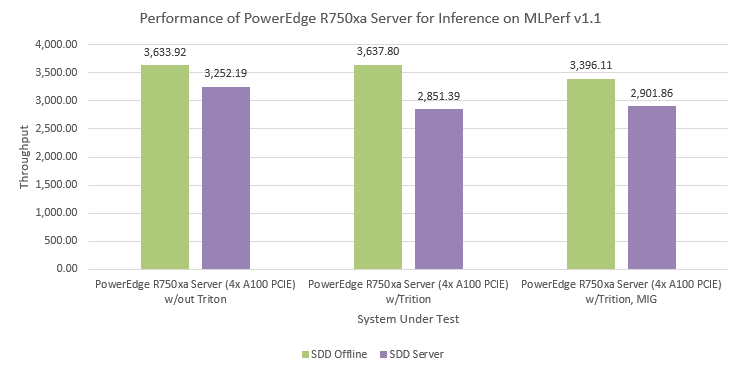
Figure. 3: PowerEdge R750xa server performance on inference for light-weight object detection.
The same three configurations of the PowerEdge R750xa server were benchmarked. Each configuration used SDD-Large as the base model and we observed performance in both the Offline and Server scenarios. The configuration that relied on the Triton Inference Server performed slightly faster in the Offline scenario with 3,638 samples per second. In the Server scenario, the configuration without the Triton Inference Server performed best at 3,252 samples per second, approximately 14 percent faster than the other configurations. Once again, each configuration performed comparably with or without the Triton Inference Server or MIG. For object detection, all configurations ranked highly for 4 x PCIe GPU configurations.
In addition to image classification, NLP, and object detection, the PowerEdge R750xa server was benchmarked for medical image classification, speech-to-text processing, and recommendation systems. The following table shows the best performance of the PowerEdge R750xa server, which relies on 4 x GPU A100 acceleration without the Triton Inference Server or MIG, and its respective performance in both the Offline and Server scenarios for each of the major tasks identified in Table 1.
Table 3: Performance of the PowerEdge R750xa server 4x A100-PCIe (80 GB) on TensorRT
Area | Task | Model | Mode | Samples per second |
Vision | Image classification | Resnet50-v1.5 | Offline | 146,878 |
Vision | Image classification | Resnet50-v1.5 | Server | 135,025 |
Vision | Object detection (large) | SSD-ResNet34 | Offline | 3,634 |
Vision | Object detection (large) | SSD-ResNet34 | Server | 3,252 |
Vision | Medical image segmentation | 3D UNet 99 | Offline | 231 |
Vision | Medical image segmentation | 3D UNet 99.9 | Offline | 231 |
Speech | Speech-to-text | RNNT | Offline | 53,113 |
Speech | Speech-to-text | RNNT | Server | 48,504 |
Language | Language processing | BERT-99 | Offline | 12,773 |
Language | Language processing | BERT-99 | Server | 11,701 |
Language | Language processing | BERT-99.9 | Offline | 6,397 |
Language | Language processing | BERT-99.9 | Server | 5,683 |
Commerce | Recommendation | DLRM-99 | Offline | 1,136,410 |
Commerce | Recommendation | DLRM-99 | Server | 1,136,670 |
Commerce | Recommendation | DLRM-99.9 | Offline | 1,136,410 |
Commerce | Recommendation | DLRM-99.9 | Server | 1,136,670 |
The results show that the system performed well in all tasks, ranking highly for each. These results show that the PowerEdge R750xa server is a solid system with flexibility for handling most AI problems that you might encounter.
Conclusion
In this blog, we quantified the performance of the PowerEdge R750xa server in the MLCommons Inference v1.1 performance benchmarks. Customers can use the submitted results to evaluate the applicability and flexibility of the PowerEdge R750xa server to address their needs and challenges.
The results in this blog show that the PowerEdge R750xa server is a flexible choice for AI inference problems. It has the flexibility to meet the inference requirements across many different scenarios and workload types.