




Delivering an AI-Powered Computer Vision Application with NVIDIA DeepStream and Dell NativeEdge

The Dell NativeEdge platform, with its latest 2.0 update, brings to the table an array of features designed to streamline edge operations. From centralized management to zero-touch deployment, it ensures that businesses can deploy and manage their edge solutions with unprecedented ease. The addition of blueprints for key Independent Software Vendors (ISV) and AI applications gives users the ability to get a fully automated end-to-end stack from bare metal to production grade vertical service in retail, manufacturing, energy, and other industries. In essence, it brings the best of both worlds—an open platform that is not bound to any specific ISV or cloud provider while preserving the simplicity of a vertical solution.
This blog describes the specific integration of NativeEdge with NVIDIA DeepStream to enable developers to build AI-powered, high-performance, low-latency video analytics applications and services.
Introduction to NVIDIA DeepStream
NVIDIA DeepStream is a comprehensive streaming analytics toolkit designed to facilitate the development and deployment of AI-powered applications. It is built on the GStreamer framework and is part of NVIDIA’s Metropolis platform. Its main features include: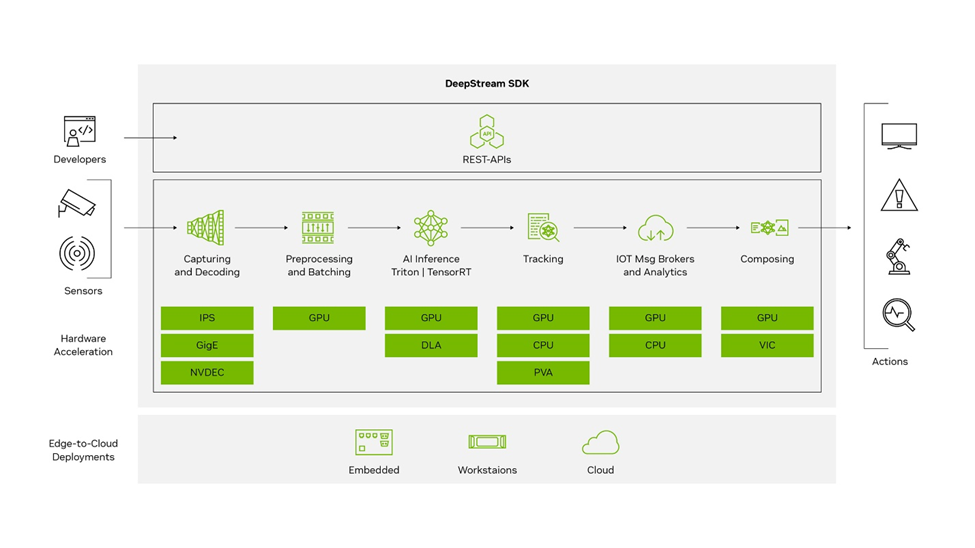 DeepStream SDK
DeepStream SDK
- Input sources—DeepStream accepts streaming data from various sources, including USB/ CSI cameras, video files, or RTSP streams.
- AI and computer vision—It utilizes AI and computer vision to analyze streaming data and extract actionable insights.
- SDK components—The core SDK includes hardware accelerator plugins that leverage accelerators such as VIC, GPU, DLA, NVDEC, and NVENC for compute-intensive operations.
- Edge-to-cloud deployment—Applications can be deployed on embedded edge devices running the Jetson platform or on a larger edge or datacenter GPUs like the T4.
- Security protocols—It offers security features like SASL/ Plain authentication and two way TLS authentication for secure communication between edge and cloud.
- CUDA-X integration—It builds on top of NVIDIA libraries from the CUDA-X stack, including CUDA, TensorRT, and NVIDIA Triton Inference Server, abstracting these libraries in DeepStream plugins.
- Containerization—Its applications can be containerized using NVIDIA Container Runtime, with containers available on NGC or NVIDIA’s GPU cloud registry.
- Programming flexibility—Developers can create applications in C, C++, or Python, and for those preferring a low-code approach, DeepStream offers Graph Composer.
- Real-time analytics—It is optimized for real-time analytics on video, image, and sensor data, providing insights at the edge.
The key benefit of the platform is that it is optimized for NVIDIA’s hardware, providing efficient video decoding and AI inferencing. It can also handle multiple video streams in real time, making it suitable for large-scale applications.
NativeEdge Integration with NVIDIA DeepStream
Deploying an AI application at the edge involves configuring and managing potentially many versions of hardware drivers, applying specific NVIDIA configuration to the containerization platform, and deploying the DeepStream stack with specific AI inferencing models. NativeEdge uses a blueprint model to automate the operational aspect of this integration. This blueprint is delivered as part of the NativeEdge solution catalog. It streamlines the entire deployment process in a way that is consistent with other solutions in the NativeEdge portfolio.
A Deeper Look Into the NativeEdge Blueprint for NVIDIA DeepStream
DeepStream is packaged as a cloud-native container and as such it relies on the availability of a container platform to be available at the edge as a prerequisite. NativeEdge enables two methods to deliver workload at the edge: a packaged virtual machine (VM) which provides full isolation or a bare metal container which maximizes performance. Once the VM or container gets provisioned on the edge, NativeEdge pulls the relevant stack, configures the GPU passthrough, and starts running the target model to enable the inferencing process.
Deployment Configuration
To deploy, the configuration steps allow the user to select the GPU target, deployment mode, and the actual artifacts without having to customize the automation blueprint for each case.
GPU Target
Select the GPU targets for the solution. The target can be A2 to L4 depending on the target footprint and performance. You can find a comparison table which provides guidance on each of the GPU capabilities here.
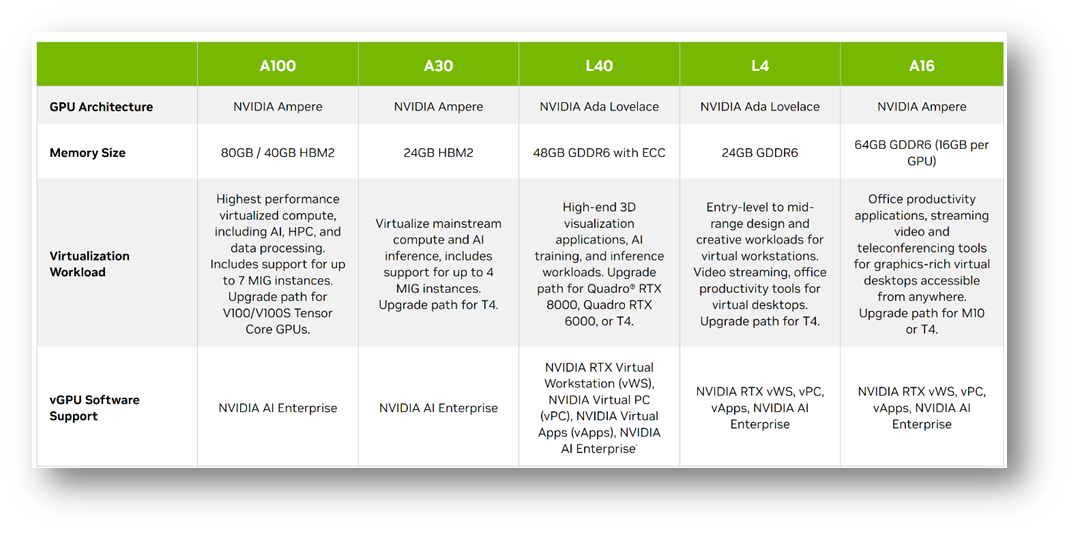 GPU configuration
GPU configuration
Deployment Mode
The deployment mode input specifies how the blueprint should configure the DeepStream container. There are three deployment modes currently supported: demo, custom model, and developer.
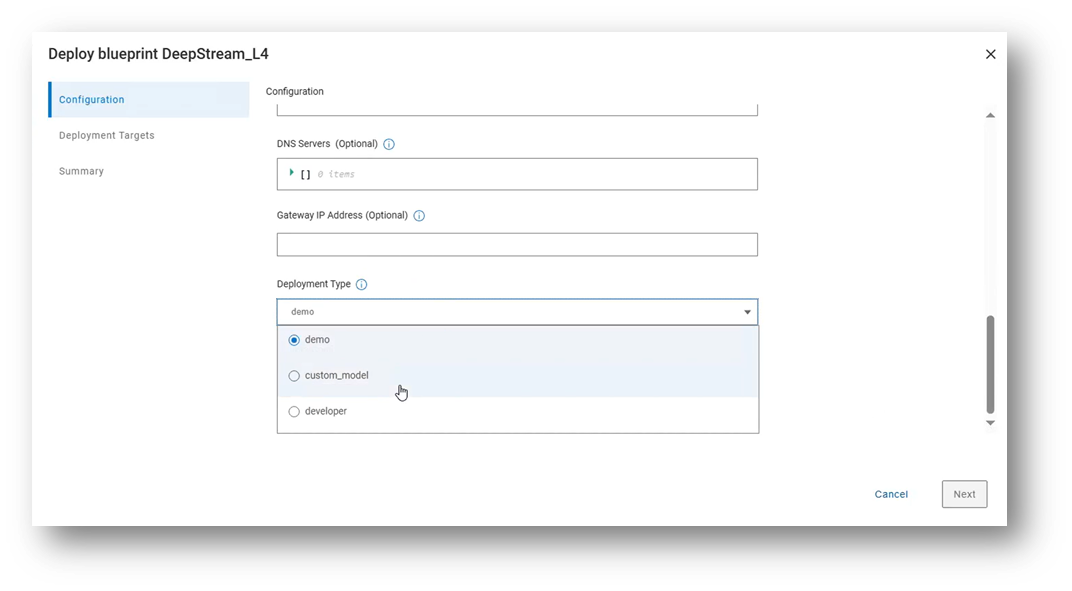 Blueprint deployment modes
Blueprint deployment modes
Demo
This mode deploys the DeepStream container and immediately starts a Triton inferencing pipeline based on an embedded demonstration video file.
Artifacts used in this mode:
- The base DeepStream container
- An archive file containing pre-built Triton inferencing models
Custom Model
This mode deploys the DeepStream container along with a customer’s bespoke pipeline configuration. In addition, the customer has the option to automatically run the pipeline as soon as the DeepStream container is deployed, without any further user intervention.
Artifacts used in this mode:
- The base DeepStream container
- An archive file containing the customer’s pipeline configuration plus any other files or data required
- An archive file containing pre-built Triton inferencing models (optional)
Developer
This mode deploys the DeepStream container and forces it to run in the background, so that a developer can log on to the host and access the container for work such as development or testing.
Artifacts used in this mode:
- The base DeepStream container
- An archive file containing pre-built Triton inferencing models (optional)
Irrespective of which deployment type is chosen, the user also needs to supply a secret artifact, which contains information such as the endpoint of the customer’s artifact repository and the credentials required to download.
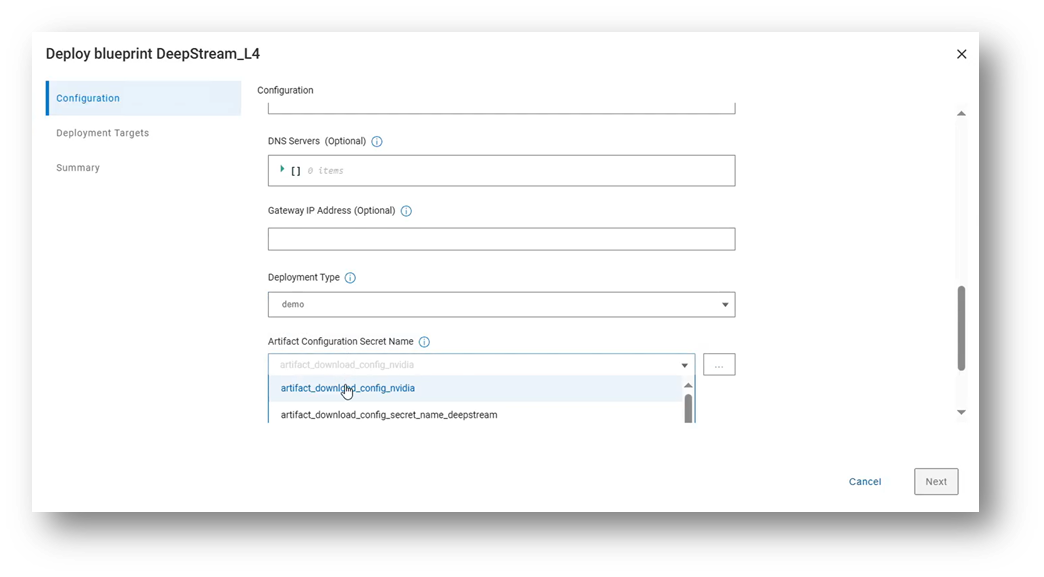 Deployment bundle Configuration
Deployment bundle Configuration
Deploy the DeepStream Solution
To deploy the solution, select the target list of devices and the specific DeepStream solution from the NativeEdge catalog and execute the install workflow.
The install workflow parses the blueprint and auto-generates the execution graph that will automates the entire deployment process based on the provided configuration and environment setup.
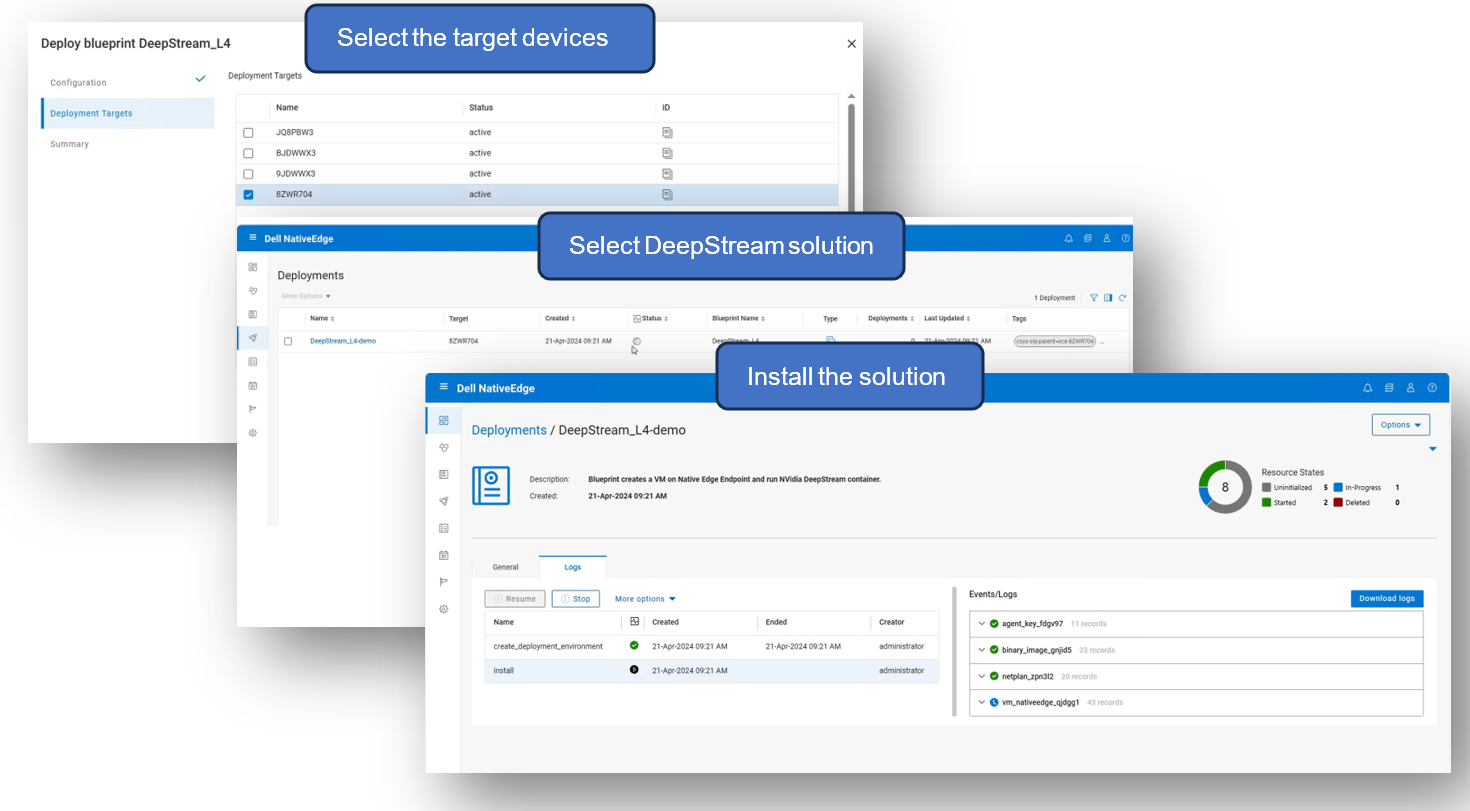 Deploying DeepStream solution in NativeEdge Orchestrator
Deploying DeepStream solution in NativeEdge Orchestrator
The event flow is automated through this process. The process includes everything from setting up the endpoint configuration to the actual deployment of the inferencing model. This enables the full end-to-end automation of the entire stack and thus allows the user to start using the system immediately after it completes the process, without the need for any additional human intervention.
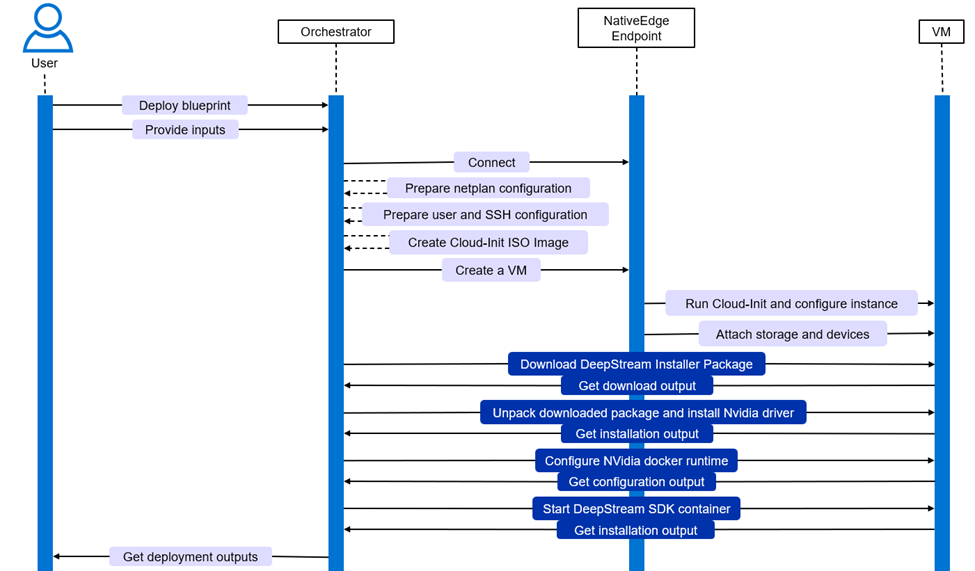 Automation event flow
Automation event flow
Use the DeepStream Solution
Once the installation from the previous step is completed successfully, we can review any relevant outputs (or capabilities) from the blueprint.
For example, if the solution is deployed with the “demo” deployment type, an RTSP feed is automatically created, which can be used by remote clients to view the output of the DeepStream demo application.
This can be seen in the following figure:
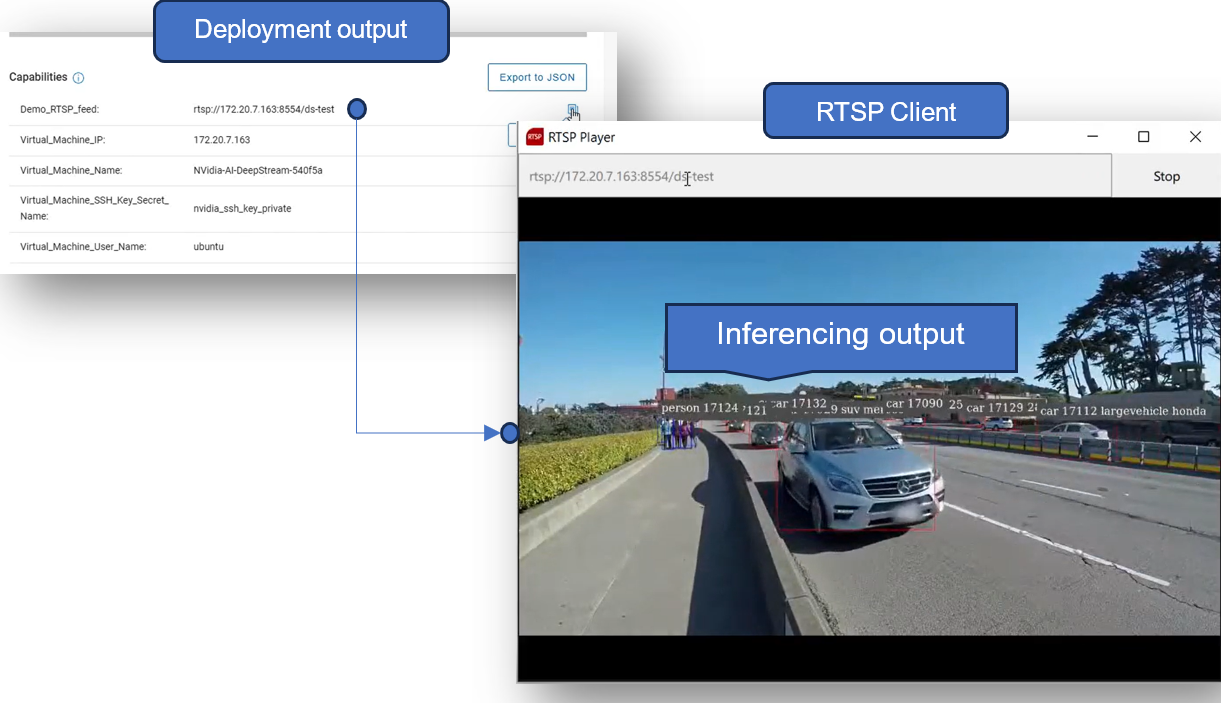 Deployment of the solution and inferencing at the edge
Deployment of the solution and inferencing at the edge
If the “custom model” deployment type is chosen, any output produced from the DeepStream application is configured by the customer themselves. In other words, the custom pipeline could potentially create an RTSP stream, in which case a client could use a similar approach to view the stream. Alternatively, the pipeline could define a video file output instead, configured to output to the persistent storage folder that is configured by NativeEdge.
Conclusion
According to IDC , inferencing at the edge is projected to double the growth rate of training by 2026. This projection is in line with the anticipated expansion of edge computing use cases, as illustrated in the following figure:
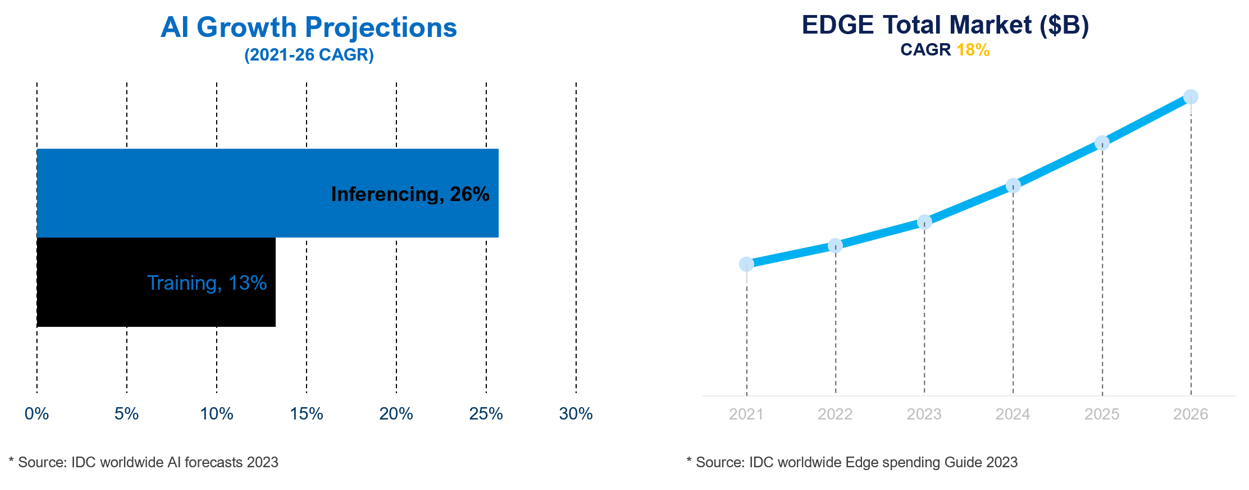 Growth of inferencing opportunities in edge market
Growth of inferencing opportunities in edge market
Dell NativeEdge is the first edge orchestration engine that automates the delivery of NVIDIA AI Enterprise software. In general, and specifically with DeepStream, NativeEdge simplifies the deployment and management of inferencing applications at the edge.
Through this integration, customers have the capability to implement their custom applications, which leverage popular frameworks, on NVIDIA AI accelerators that are compatible with Dell NativeEdge. This is complemented by the ability to incorporate their development infrastructure using the NativeEdge API or CI/CD processes. Additionally, NativeEdge provides support for orchestrating cloud services through Infrastructure as Code (IaC) frameworks like Terraform, Ansible, CloudFormation, or Azure ARM, allowing customers to manage their edge and associated cloud services using the same automation framework.
Integration with ServiceNow enables IT personnel to oversee NativeEdge Endpoints in a manner that is similar to other data center resources, utilizing the ServiceNow CMDB. This integration simplifies edge operations and supports more rapid and flexible release cycles for inferencing services to the edge, thereby helping customers keep pace with the speed of AI developments.
References
- Recent posts for: “DeepStream” | NVIDIA Technical Blog
- Building Intelligent Video Analytics Apps Using NVIDIA DeepStream 5.0 (Updated for GA) | NVIDIA Technical Blog
- Inferencing at the Edge | Dell Technologies Info Hub
- Announcing Dell NativeEdge 2.0: Reimagining Edge Operations | Dell USA
- Managing Video Streams in Runtime with the NVIDIA DeepStream SDK | NVIDIA Technical Blog
- DeepStream SDK | NVIDIA Developer | NVIDIA Developer