




Deep Neural Network Inference Performance on Intel FPGAs using Intel OpenVINO
Mon, 03 Aug 2020 15:55:14 -0000
|Read Time: 0 minutes
Originally published on Nov 16, 2018 9:22:39 AM
Inference is the process of running a trained neural network to process new inputs and make predictions. Training is usually performed offline in a data center or a server farm. Inference can be performed in a variety of environments depending on the use case. Intel® FPGAs provide a low power, high throughput solution for running inference. In this blog, we look at using the Intel® Programmable Acceleration Card (PAC) with Intel® Arria® 10GX FPGA for running inference on a Convolutional Neural Network (CNN) model trained for identifying thoracic pathologies.
Advantages of using Intel® FPGAs
System Acceleration: Intel® FPGAs accelerate and aid the compute and connectivity required to collect and process the massive quantities of information around us by controlling the data path. In addition to FPGAs being used as compute offload, they can also directly receive data and process it inline without going through the host system. This frees the processor to manage other system events and enables higher real time system performance.
Power Efficiency: Intel® FPGAs have over 8 TB/s of on-die memory bandwidth. Therefore, solutions tend to keep the data on the device tightly coupled with the next computation. This minimizes the need to access external memory and results in a more efficient circuit implementation in the FPGA where data can be paralleled, pipelined, and processed on every clock cycle. These circuits can be run at significantly lower clock frequencies than traditional general-purpose processors and results in very powerful and efficient solutions.
Future Proofing: In addition to system acceleration and power efficiency, Intel® FPGAs help future proof systems. With such a dynamic technology as machine learning, which is evolving and changing constantly, Intel® FPGAs provide flexibility unavailable in fixed devices. As precisions drop from 32-bit to 8-bit and even binary/ternary networks, an FPGA has the flexibility to support those changes instantly. As next generation architectures and methodologies are developed, FPGAs will be there to implement them.
Model and software
The model is a Resnet-50 CNN trained on the NIH chest x-ray dataset. The dataset contains over 100,000 chest x-rays, each labelled with one or more pathologies. The model was trained on 512 Intel® Xeon® Scalable Gold 6148 processors in 11.25 minutes on the Zenith cluster at DellEMC.
The model is trained using Tensorflow 1.6. We use the Intel® OpenVINO™ R3 toolkit to deploy the model on the FPGA. The Intel® OpenVINO™ toolkit is a collection of software tools to facilitate the deployment of deep learning models. This OpenVINO blog post details the procedure to convert a Tensorflow model to a format that can be run on the FPGA.
Performance
In this section, we look at the power consumption and throughput numbers on the Dell EMC PowerEdge R740 and R640 servers.
Using the Dell EMC PowerEdge R740 with 2x Intel® Xeon® Scalable Gold 6136 (300W) and 4x Intel® PACs
The figures below show the power consumption and throughput numbers for running the model on Intel® PACs, and in combination with Intel® Xeon® Scalable Gold 6136. We observe that the addition of a single Intel® PAC adds only 43W to the system power while providing the ability to inference over 100 chest X-rays per second. The additional power and inference performance scales linearly with the addition of more Intel® PACs. At a system level, wee see a 2.3x improvement in throughput and 116% improvement in efficiency (images per sec per Watt) when using 4x Intel® PACs with 2x Intel® Xeon® Scalable Gold 6136.
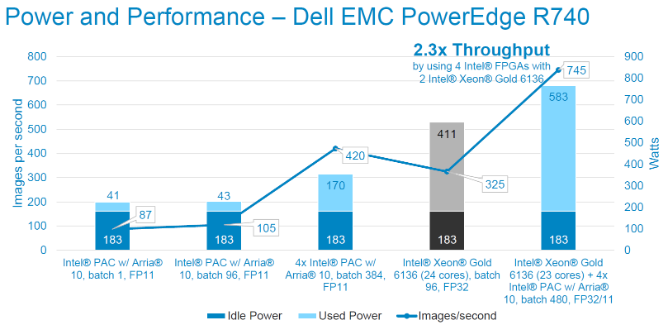 Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
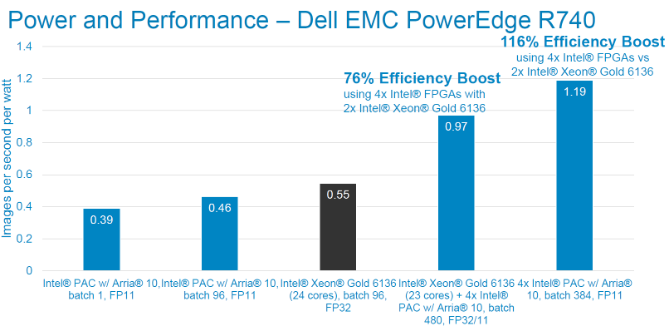 Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadmUsing the Dell EMC PowerEdge R640 with 2x Intel® Xeon® Scalable Gold 5118 (210W) and 2x Intel® PACs
We also used a server with lower idle power. We see a 2.6x improvement in system performance in this case. As before, each Intel® PAC linearly adds performance to the system, adding more than 100 inferences per second for 43W (2.44 images/sec/W).
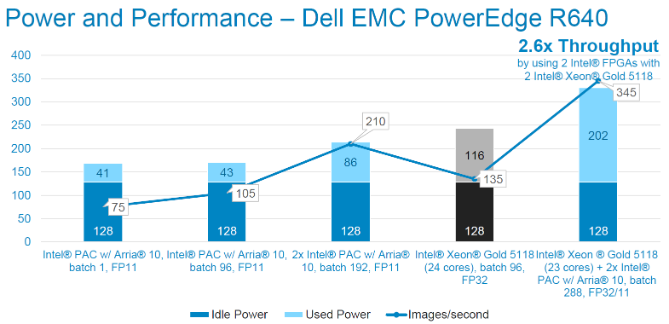 Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
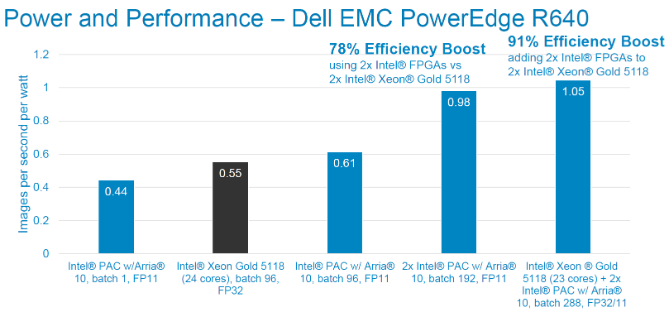 Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Conclusion
Intel® FPGAs coupled with Intel® OpenVINO™ provide a complete solution for deploying deep learning models in production. FPGAs offer low power and flexibility that make them very suitable as an accelerator device for deep learning workloads.